
پاسخگویی خودکار به سوالات آب منطقه ای خراسان رضوی (پارسا)
Document Management System with Retrieval-Augmented Generation for Water Projects
فهرست محتویات
- مقدمه و هدف
- معماری سیستم
- اجزای اصلی
- تفصیل کامل کدها
- فرآیند شاخصسازی
- سیستم بازیابی هوشمند
- واسط کاربری و API
- دادههای نمونه
مقدمه و هدف
در دهههای اخیر، پیشرفتهای چشمگیر هوش مصنوعی و یادگیری ماشین، فرصتهای بیسابقهای را برای تحول در حوزه های مختلف از جمله مسایل مربوط به آب ایجاد کردهاند. با این حال، سیستمهای پاسخگوی هوشمند با چالش حجم انبوه و تخصصی در هر سازمان مواجه هستند که موجب سردرگمی کارشناسان و ارابا رجوعان می شود.
مدلهای زبان بزرگ (LLMs) بهعنوان راهحلی نویدبخش مطرح شدهاند، اما کاربرد مستقیم آنها در پزشکی با دو محدودیت اساسی روبرو است: ۱) توهمزایی (تولید اطلاعات نادرست اما بهظاهر معتبر) و ۲) دانش قدیمی (عدم دسترسی به جدیدترین یافتهها و دستورالعملها). برای غلبه بر این موانع و افزایش قابلیت اطمینان، رویکرد “تولید تقویتشده با بازیابی” (RAG) پیشنهاد شده است. در این رویکرد، پیش از تولید پاسخ، اطلاعات معتبر و مرتبط از پایگاههای دانش بهروز (مانند مقالات) بازیابی و به مدل ارائه میشود تا پاسخهایی مستند، دقیق و مبتنی بر شواهد تولید کند. هدف نهایی، ارائه یک دستیار هوشمند، قابل اعتماد و عملیاتی برای کمک به کارشناسان سازمان آب است.
امروزه، حجم دادههای مربوط به منابع آب، مصرف، کیفیت، پروژههای آبی و گزارشهای بهرهبرداری در شرکت آب منطقهای خراسان رضوی با نرخ بیسابقهای در حال افزایش است. با این حال، شکاف عظیمی بین وجود داده و “تبدیل آن به بینش عملیاتی و تصمیم راهبردی” وجود دارد.
مسئله اصلی این است:
- اطلاعات پراكنده و جزيرهای: دادههای مختلف در سیلوهای جداگانه محبوس شدهاند
- عدم شناسایی ارتباطات راهبردی: کشف روندهای پنهان به صورت کاملاً دستی و تصادفی انجام میشود
- اتلاف منابع و فرصتها: این آشفتگی اطلاعاتی منجر به تأخیر در تصمیمگیری میشود
نیاز حیاتی: شرکت آب منطقهای به یک “پارسا” (پاسخگویی خودکار سوالات آب منطقهای) نیاز دارد که بتواند به طور خودکار این اکوسیستم پیچیده داده را پایش کند و تصمیمگیرندگان را از حالت انفعال به وضعیت فعال در بهرهبرداری از “بینشهای استخراجشده” برساند.
ضرورت و اهمیت اجرای طرح
اجرای موفقیتآمیز طرحهای کلان در حوزه آب، مستلزم ایجاد یک «پایگاه دانش هوشمند و یکپارچه» است. این سیستم، فراتر از یک پایگاه دادهی SQL متعارف عمل نموده و علاوه بر دادههای ساختاریافته، باید بتواند انبوه اسناد، گزارشهای فنی و طرحهای تحقیقاتی را نیز در خود ادغام و پردازش نماید.
نکته کلیدی و تعیینکننده دیگر، انتخاب صحیح و هوشمندانه اطلاعات است. این پروژه از روشهای «نمونهبرداری هوشمند مبتنی بر حفظ مفهوم» بهره میبرد که توسط مولفین پیشرو در حوزههای علم داده توسعه یافته است. این رویکرد، اطمینان حاصل میکند که هستهی اطلاعاتی سیستم، نه تنها کامل، بلکه دقیق، مرتبط و غنی از ارتباطات معنایی است.
الف) ضرورت راهبردی و امنیت ملی
کسب برتری اطلاعاتی در حوزه آب در شرایط بحران آب، برتری اطلاعاتی تعیینکننده است. این سامانه با تحلیل یکپارچه تمامی داراییهای دادهای شرکت، “درک وضعیت جامعی” را برای تصمیمگیرندگان فراهم میکند.
ب) ضرورت اقتصادی و توسعه پایدار
بهینهسازی سرمایهگذاریهای کلان بودجههای پروژههای آبی محدود است. این سامانه با جلوگیری از تصمیمات نادرست، بازده سرمایه گذاری را به صورت تصاعدی افزایش میدهد.
اهداف سامانه ““پارسا””
الف) اهداف کلان (راهبردی و ملی)
- ارتقای امنیت آبی استان خراسان رضوی از طریق تسلط بر دادههای حوزه آب
- تحقق حکمرانی هوشمند و دادهمحور در مدیریت منابع آب
- جایگاهسازی ایران به عنوان پیشرو در استفاده از هوش مصنوعی برای مدیریت بحران آب
ب) اهداف خرد (عملیاتی و فنی)
- ایجاد یک پایگاه دانش هوشمند و پویا از دادههای شرکت آب منطقهای
- توسعه و استقرار یک موتور کشف ارتباطات پیشرفته و پاسخگویی خودکار
- تسهیل و تسریع فرآیندهای تحقیق و توسعه و تصمیمگیری
- کاهش زمان مورد نیاز برای شناسایی اطلاعات مرتبط از روزها به دقایق
این سامانه با هدف فراهمکردن یک رابط هوشمند و طبیعی برای کاربران جهت دسترسی به اسناد پروژههای آبی طراحی شده است. به کمک فناوری Retrieval-Augmented Generation (RAG)، سیستم میتواند:
- جستجوی معنایی: درک معنی و مفهوم درخواست کاربر، نه صرف جستجوی کلمات کلیدی
- بازیابی بهینه: یافتن اسناد و بخشهای مرتبط از میان هزاران صفحه
- پاسخ هوشمند: تولید پاسخهای روشن و منطقی بر اساس اسناد
- توجیه تصمیم: ارائه منابع و مراجع برای هر پاسخ
چرایی استفاده از ““پارسا””
بدون RAG:
کاربر: "چگونه میتوان مصرف انرژی تصفیهخانه را بهینهسازی کرد؟"
LLM: [پاسخ عمومی بدون اطلاع از اسناد محلی]
با RAG:
کاربر: "چگونه میتوان مصرف انرژی تصفیهخانه را بهینهسازی کرد؟"
سیستم: [جستجو در اسناد مشهد + بازیابی نتایج مرتبط]
LLM: [تولید پاسخ بر اساس اسناد واقعی]
کاربر: [پاسخ + منابع]
سوابق علمی و کاربردی
پیشینه تحقیق
در سالهای اخیر، ترکیب مدلهای زبانی بزرگ (LLMها) با سامانههای بازیابی اطلاعات، به یکی از خطوط اصلی پژوهش در پردازش زبان طبیعی و سامانههای پرسش و پاسخ تبدیل شده است. هسته این خط پژوهشی را معماریهای تولید تقویتشده با بازیابی (RAG) تشکیل میدهند که در آن، مدل زبانی به جای اتکا به حافظه پارامتری خود، پاسخ را بر اساس اسناد بازیابیشده از یک پایگاه دانش بیرونی تولید میکند [1, 2]. معرفی اولیه RAG توسط لوئیس و همکاران، این ایده را در زمینه مسائل «دانشمحور» تثبیت کرد و نشان داد که ترکیب یک ماژول بازیابی متراکم با یک LLM میتواند دقت را نسبت به روشهای صرفاً «بازیابی + رتبهبند عصبی» بهبود دهد [1]. معرفی چند نمونه در بازیابی اطلاعات
حوزه مالی و سرمایهگذاری: Bloomberg
عنوان کاربرد: BloombergGPT و دستیار هوشمند ترمینال بلومبرگ کاربرد سازمانی: تحلیل مالی، پژوهش بازار سرمایه و تصمیمگیری سرمایهگذاری. توضیحات مختصر: بلومبرگ به یکی از بزرگترین پایگاههای داده مالی جهان دسترسی دارد. آنها با استفاده از معماری RAG، یک دستیار هوشمند برای ترمینال معروف خود ایجاد کردهاند. کارشناسان مالی میتوانند سوالات پیچیدهای به زبان طبیعی بپرسند، برای مثال: “عملکرد سهام شرکت اپل در ۱۰ سال گذشته در مقایسه با شاخص نزدک چگونه بوده و تحلیلگران چه پیشبینیهایی برای سود سهام آن داشتهاند؟” بخش Retrieval (بازیابی): سیستم به صورت آنی در پایگاه دادههای عظیم بلومبرگ (شامل قیمتها، گزارشهای مالی، اخبار و تحلیلها) جستجو میکند و مرتبطترین اطلاعات را استخراج میکند. بخش Generation (تولید): مدل زبانی بزرگ (BloombergGPT) این اطلاعات بازیابیشده را خلاصه کرده و یک پاسخ منسجم و دقیق به همراه منبع آن برای کاربر تولید میکند. این کار از نیاز به جستجوهای دستی و زمانبر جلوگیری میکند.
نکته مهم مورد نیاز پروژه پارسا
در بلومبرگ یک دانشنامه تخصصی اموزش دیده است حالا با استفاده از اسناد محرمانه قابلیت بیشتر خواهد یافت بطوریکه با استفاده از RAG مانند مجهز کردن آن دانشنامه به یک موتور جستجوی سریع است که میتواند در کتابخانه تخصصی بلومبرگ جستجو کند. اما بلومبرگGPT با آموزش عمیق و ترکیبی، نه تنها موتور جستجو را اضافه کرده، بلکه بیش از نیمی از محتوای اصلی دانشنامه را با دانش فوق تخصصی مالی (FinPile) جایگزین کرده است تا درک و پاسخهای بومیاش در امور مالی دقیقتر و سریعتر باشد.
حوزه حقوقی و قراردادها: Harvey AI
نام شرکت: Harvey AI (استفاده توسط شرکتهای حقوقی بزرگی مانند Allen & Overy)
عنوان کاربرد: دستیار هوشمند برای وکلا و مشاوران حقوقی کاربرد سازمانی: تحقیق حقوقی، تحلیل قراردادها و مدیریت پروندهها. توضیحات مختصر: شرکتهای حقوقی با حجم انبوهی از اسناد، قوانین، دعاوی سابقه و قراردادها سروکار دارند. Harvey AI یک پلتفرم مبتنی بر RAG است که به وکلا کمک میکند تا کارهای خود را به سرعت انجام دهند. بخش Retrieval: وکیل میتواند سوالاتی مانند “چه دعاوی مشابهی در زمینه نقض قرارداد نرمافزاری در ایالت کالیفرنیا در ۵ سال گذشته با این نتیجه به ثبت رسیده است؟” را بپرسد. سیستم در پایگاه دادههای حقوقی و اسناد داخلی شرکت جستجو میکند. بخش Generation: Harvey تحلیلهای حقوقی، پیشنویسهای قرارداد، یا خلاصهای از نقاط کلیدی یک پرونده طولانی را بر اساس اطلاعات بازیابیشده تهیه میکند. این کار دقت را افزایش داده و زمان را به شدت کاهش میدهد.
این متن، ویژگیها و قابلیتهای یک پلتفرم هوشمند مخصوص حوزه حقوقی را معرفی میکند. به نظر میرسد این پلتفرم (احتمالاً یک شرکت فناوری حقوقی مانند Harvey AI، Casetext یا مشابه) با استفاده از هوش مصنوعی تخصصی، به وکلا و شرکتهای حقوقی در خودکارسازی و بهبود فرآیندهای کاری کمک میکند.
خلاصه و تفسیر بخشهای اصلی:
- Assistant (دستیار): یک هوش مصنوعی تخصصی حقوقی که به کاربران در پرسش سؤال، تحلیل اسناد و تسریع نگارش کمک میکند. (مشابه ChatGPT اما برای حقوق)
- Vault (گاوصندوق/انباره امن): یک فضای امن برای ذخیرهسازی، سازماندهی و تحلیل گروهی اسناد حقوقی (مانند قراردادها، پروندهها).
- Knowledge (دانش): امکان تحقیق جامع در زمینههای پیچیده حقوقی، مقررات و مالیات را فراهم میکند.
- Workflows (گردشهای کاری): به کاربران اجازه میدهد از گردشهای کاری از پیش ساختهشده استفاده کنند یا گردشهای کاری سفارشی متناسب با نیازهای خاص شرکت خود بسازند.
- Microsoft Integrations (یکپارچهسازی با مایکروسافت): قابلیتهای هوش مصنوعی حقوقی را مستقیماً در Word، Outlook و SharePoint برای بررسی قرارداد، نگارش، ایمیل و اسناد ارائه میدهد.
این پلتفرم یک دستیار حقوقی همهکاره مبتنی بر هوش مصنوعی است که هدف آن اتوماسیون هوشمند، بهبود دقت و صرفهجویی در زمان برای متخصصان حقوق از طریق مجموعهای از ابزارهای تخصصی و یکپارچه با محیطهای کاری رایج است.
ارائه یک چارچوب علمی و عملیاتی برای توسعه سامانه هوشمند مدیریت دانش و تصمیمیاری در حوزه آب
1. چالشهای بنیادین و ضرورت تحول
صنعت آب و مدیریت منابع هیدرولوژیک با چالشهای ساختاری مواجه است که پیچیدگی ذاتی این حوزه را دوچندان میکند:
- حجم انبوه و پراکندگی دادههای ناهمگون: دادههای کمی (دبی، سطح ایستابی، کیفیت شیمیایی)، دادههای کیفی (گزارشهای کارشناسی، تصاویر ماهوارهای، نقشههای ژئوتکنیک) و دادههای حقوقی (مجوزها، قراردادها) غالباً در سیلوهای اطلاعاتی جداگانه و با فرمتهای متنوع ذخیره میشوند.
- وابستگی شدید به دانش ضمنی (Tacit Knowledge): بخش عمدهای از دانش فنی و تجربی در ذهن کارشناسان ارشد نهفته است و با بازنشستگی یا جابجایی آنان، خطر از دست رفتن این سرمایه دانشی سازمان را تهدید میکند.
- زمانبری فرآیندهای بازیابی اطلاعات: پاسخ به یک پرسش تخصصی ساده (مانند «آخرین گزارش آسیبشناسی سد X چیست؟») ممکن است نیازمند جستجو در آرشیوهای فیزیکی و دیجیتال متعدد و صرف ساعتها زمان باشد.
- نیاز به تصمیمگیری سریع در شرایط بحرانی: در مواجهه با پدیدههایی مانند سیل، خشکسالی شدید یا آلودگی ناگهانی منابع آب، دسترسی فوری به دادههای تاریخی، پروتکلها و درسآموختههای گذشته حیاتی است.
2. راهحل پیشنهادی: سامانه هوشمند یکپارچه (“پارسا”)
برای فائق آمدن بر این چالشها، طراحی و استقرار یک سامانه سه رکنی پیشنهاد می شود:
رکن اول: موتور بازیابی و یکپارچهسازی دانش (Knowledge Retrieval & Integration Engine)
این لایه مسئول شکستن سیلوهای اطلاعاتی است.
- اتصال به منابع داده پراکنده: این موتور قادر خواهد بود به طیف وسیعی از منابع داده داخلی (سرورهای SQL، فایلسرورهای سازمانی، اسکن اسناد قدیمی) و خارجی (دادههای سازمان هواشناسی، تصاویر ماهوارهای) متصل شود.
- پردازش چندوجهی اسناد: از فناوریهای پردازش زبان طبیعی (NLP) برای درک متون گزارشها، تشخیص نویسه نوری (OCR) برای استخراج متن از نقشهها و اسناد اسکنشده، و پردازش دادههای ساختاریافته (مانند جداول اکسل و خروجیهای نرمافزارهای هیدرولوژیک) استفاده میکند.
- ایجاد نمای یکپارچه و ایندکسشده: خروجی این لایه، ایجاد یک «نمای یکپارچه معنایی» (Unified Semantic Index) از تمام دانش سازمان است که در آن هر مفهوم، داده یا سند به همراه ارتباطات آن با سایر اجزا نقشهبرداری شده است.
رکن دوم: موتور استدلال و پاسخگویی تقویتشده با بازیابی (Retrieval-Augmented Reasoning Engine)
این هسته مرکزی سامانه، مسئول تعامل هوشمند با کاربر و تولید پاسخهای مستند است. این رکن بهطور مشخص از معماری تولید تقویتشده با بازیابی (RAG) بهره میبرد که مشکل توهمزایی مدلهای زبانی بزرگ عمومی را حل میکند.
- درک پرسش تخصصی: یک مدل زبانی که بهطور خاص بر روی پیکرههای متون تخصصی حوزه آب (شامل فارسی و انگلیسی) آموزش دیده یا تنظیم شده (Fine-tuned) است، قصد و نیت کاربر را از پرسش آزاد (مثال: «چه عواملی در افت سطح آبخوان دشت Y در پنج سال اخیر بیشترین تأثیر را داشته؟») استخراج میکند.
- بازیابی مستندات مرتبط: بر اساس درک حاصل شده، موتور به نمای یکپارچه معنایی مراجعه کرده و مرتبطترین قطعات اطلاعات (بندهایی از گزارشها، ردیفهایی از دادهها، بخشهایی از نقشهها) را بازیابی میکند.
- تولید پاسخ مستند و قابل ردیابی: مدل زبانی، پاسخ نهایی را تنها بر اساس اسناد بازیابیشده تولید میکند و بهطور خودکار به منابع استناد میکند. این مکانیزم، صحت پاسخ و قابلیت اعتماد آن را تضمین میکند.
رکن سوم: موتور خودکارسازی فرآیندهای دانشبنیاد (Knowledge-Driven Process Automation Engine)
این رکن، “پارسا” را از یک سیستم پاسخگو به یک دستیار عملیاتی ارتقا میدهد.
- تبدیل دانش به عمل: سامانه قادر خواهد بود بر اساس درخواست کاربر یا تحلیل خودکار دادهها، اقدامات عملیاتی را آغاز کند. برای مثال، در پاسخ به پرسش «گزارش ماهانه عملکرد سد Z را آماده کن»، میتواند دادههای خام را از پایگاههای مختلف جمعآوری، تحلیل، در قالب استاندارد سازمانی قرار داده و یک پیشنویس گزارش تولید کند.
- یکپارچگی با سیستمهای کاری: این موتور از طریق API با سیستمهای نرمافزاری موجود سازمان (مانند سیستم مدیریت پروژه، سیستم مکاتبات، نرمافزارهای مدلسازی هیدرولوژیک) یکپارچه میشود تا گردش کارهای پیچیده را هدایت کند.
3. کاربردها و خروجیهای مورد انتظار در شرکت آب منطقهای
پیادهسازی “پارسا” منجر به خلق قابلیتهای انقلابی زیر خواهد شد:
| حوزه کاربرد | توصیف | مثال عینی |
|---|---|---|
| پشتیبانی از تصمیمگیری فوری | ارائه سریع تحلیلهای چندمعیاره بر اساس دادههای تاریخی و مدلهای شبیهسازی. | در زمان پیشبینی سیل، سامانه بهطور خودکار دادههای بارش، وضعیت مخازن سدها و هیدروگراف سیلابهای تاریخی را بازیابی و تحلیل کرده و گزینههای مدیریتی را با پیامدهای هرکدام به تصمیمگیر ارائه میدهد. |
| مدیریت دانش پروژهها | ایجاد پایگاه دانش زنده از تمامی پروژههای گذشته و حال. | مهندس جدید پروژه انتقال آب میپرسد: «در پروژه مشابه الف، مهمترین چالشهای ژئوتکنیکی چه بود و چگونه حل شد؟». سامانه صورتجلسات، گزارشهای مذاکره و طرحهای فنی آن پروژه را استخراج و خلاصه میکند. |
| آموزش و توانمندسازی نیروی انسانی | ایجاد یک محیط آموزشی تعاملی و مبتنی بر موارد واقعی. | کارشناس جوان با پرسش «روال رسیدگی به درخواست حفر چاه کشاورزی چیست؟» میتواند علاوه بر دریافت متن دستورالعمل، نمونههای واقعی پروندههای تکمیلشده، نظرات کارشناسی صادر شده و آراء هیئتهای رسیدگی را مشاهده کند. |
| گزارشدهی و تحلیل پیشرفته | خودکارسازی تولید گزارشهای دورهای و کشف الگوهای پنهان در دادهها. | سامانه بهطور خودکار در پایان هر فصل، گزارش جامعی از وضعیت کمی و کیفی منابع آب حوضه، انحراف از برنامه و پیشبینی روندها را با نمودارها و جداول تولید و برای مدیران ارسال میکند. |
4. مسیر پیادهسازی و ملاحظات
- فاز صفر: تدوین نقشه دانش (Knowledge Mapping): شناسایی و فهرستبرداری از تمام منابع داده، اسناد کلیدی و جریانهای اطلاعاتی در سازمان.
- فاز یک: ساخت زیرساخت داده و موتور بازیابی: یکپارچهسازی دادههای ساختاریافته و ایجاد مخزن اسناد با قابلیت ایندکسگذاری پیشرفته.
- فاز دو: توسعه و آموزش مدل زبانی تخصصی: جمعآوری پیکره متون تخصصی آب و تنظیم مدل زبانی پایه برای درک بهتر اصطلاحات و مفاهیم این حوزه.
- فاز سه: پیادهسازی معماری RAG و رابط کاربری: توسعه هسته اصلی سامانه و ایجاد یک رابط گفتگومحور ساده و کاربرپسند برای تعامل کلیه پرسنل.
- فاز چهار: خودکارسازی فرآیندها و توسعه پیشرفته: یکپارچهسازی با سیستمهای عملیاتی و افزودن قابلیتهای پیچیدهتر مانند تحلیل پیشبینانه.
جمعبندی نهایی: چارچوب پیشنهادی “پارسا”، صرفاً یک نرمافزار جدید نیست، بلکه تحولی در روش مدیریت دانش و تصمیمگیری در شرکت آب منطقهای است. این سامانه با تبدیل دادههای پراکنده به دانش قابلدسترس و عمل، سرمایه اطلاعاتی سازمان را به یک مزیت رقابتی و عملیاتی پایدار تبدیل میکند و توانایی پاسخگویی به چالشهای پیچیده حال و آینده حوزه آب را بهطور چشمگیری افزایش میدهد. موفقیت این طرح در گرو تعهد مدیریت ارشد، مشارکت فعال کارشناسان به عنوان صاحبان دانش، و انتخاب فناوریهای پایدار و قابل توسعه است.
فرآیند عملکرد سیستم اولیه
1. شاخصسازی (Indexing)
└─ سند → چانکینگ → Embedding → FAISS Index
2. بازیابی (Retrieval)
└─ پرسش → معمولسازی → جستجو معنایی + کلیدی
3. تولید (Generation)
└─ پرسش + منابع → LLM (Gemini) → پاسخ توضیحی
آیین نامه مورد استفاده
تصویر نرم افزار
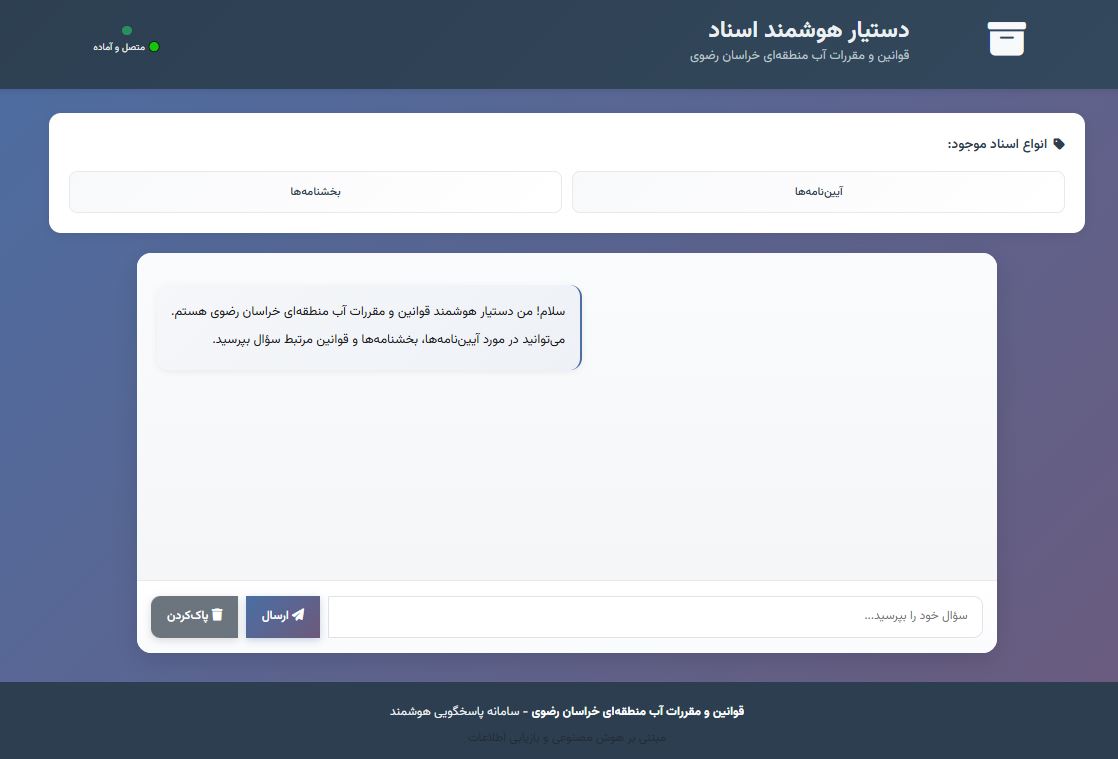
جزییات تحلیلی
در پیوست برخی جزییات بازیابی اطلاعات ارایه شده است برای رتبه بندی برخی از کارهای مولف در جریان پیاده سازی مد نظر بوده است. نمونه های نزدیک [3],[4] را ملاحظه کنید و دیگر نکات را در لینک زیر کارهای اخیر خواهید یافت.
چند سوال از پارسا
پیوست ها
مدلهای زبان بزرگ و RAG: تعاریف و مفاهیم پایه در حوزه آب
مدلهای زبان بزرگ (Large Language Models یا LLMs) نوعی از شبکههای عصبی عمیق هستند که با استفاده از معماری Transformer و آموزش بر روی حجم عظیمی از دادههای متنی، توانایی درک و تولید زبان طبیعی را در سطح بسیار بالایی کسب کردهاند. مدلهایی مانند GPT-4، Claude، Llama و Gemini نمونههایی از این نسل جدید LLMها هستند که در سالهای اخیر توجه زیادی را به خود جلب کردهاند. این مدلها میتوانند طیف گستردهای از وظایف زبانی را انجام دهند، از جمله پاسخ به سؤالات، ترجمه، خلاصهسازی متون، تولید گزارش و تحلیل دادهها.
با وجود قابلیتهای شگفتانگیز LLMها، استفاده از آنها در حوزههای فنی و حساسی مانند مدیریت منابع آب با چالشهای خاصی همراه است. مهمترین این چالشها عبارتند از:
- توهمزایی (Hallucination): LLMها ممکن است اطلاعات نادرست یا ساختگی تولید کنند که در ظاهر منطقی به نظر میرسند اما با واقعیتهای فنی و دادههای سازمانی مطابقت ندارند. این موضوع در تصمیمگیریهای حیاتی مرتبط با آب میتواند خطرات عملیاتی ایجاد کند.
- قدیمی بودن دانش: LLMها تنها تا زمان مشخصی از دادهها آگاهی دارند و از آخرین گزارشها، آمارها، مقررات و تحولات جدید در حوزه آب (مانند تغییرات سطح آبهای زیرزمینی یا سیاستهای جدید تخصیص آب) بیاطلاع هستند.
- عدم شفافیت: LLMها اغلب نمیتوانند منبع اطلاعات خود را مشخص کنند یا دلیل منطقی برای پاسخهای خود ارائه دهند، که این موضوع اعتماد کارشناسان فنی و مدیران به آنها را کاهش میدهد.
- عدم تخصص حوزهای: LLMهای عمومی ممکن است در درک تخصصی اصطلاحات هیدرولوژی، آمارهای منابع آب، گزارشهای کیفی آب، قوانین تخصیص و زمینه پیچیده مدیریت یک حوضه آبی ضعف داشته باشند.
برای مقابله با این محدودیتها، رویکرد «تولید متن تقویتشده با بازیابی» (Retrieval-Augmented Generation یا RAG) ارائه شده است. RAG یک چارچوب معماری است که LLMها را با سیستمهای بازیابی اطلاعات ترکیب میکند تا دقت، بهروزبودن و قابلیت اعتماد پاسخهای تولیدشده را افزایش دهد. در یک سیستم RAG، فرآیند پاسخدهی به یک سؤال یا درخواست کاربر در دو مرحله اصلی انجام میشود:
مرحله اول - بازیابی (Retrieval): در این مرحله، سیستم با استفاده از الگوریتمهای جستجوی معنایی، اسناد، پاراگرافها یا قطعات اطلاعاتی مرتبط با سؤال کاربر را از یک یا چند منبع دانش خارجی بازیابی میکند. این منابع میتوانند شامل پایگاههای داده سازمانی (مانند آمارهای بلندمدت آب سطحی و زیرزمینی، گزارشهای کیفیت آب، پروژههای آبی)، اسناد حقوقی و قراردادها، دستورالعملهای فنی، گزارشهای پژوهشی شرکت آب منطقهای و یا سایر اسناد معتبر مرتبط باشند.
مرحله دوم - تولید (Generation): پس از بازیابی اطلاعات مرتبط، این اطلاعات بههمراه سؤال اصلی به LLM داده میشوند. LLM با استفاده از این زمینه غنیشده، پاسخی دقیقتر، مستندتر و مرتبطتر تولید میکند. از آنجا که LLM اکنون به اطلاعات واقعی و بهروز سازمان دسترسی دارد، احتمال تولید اطلاعات نادرست بهطور قابلتوجهی کاهش مییابد.
مزایای اصلی RAG در مقایسه با استفاده مستقیم از LLM برای سازمان آب منطقهای عبارتند از:
- کاهش توهمزایی: با تکیه بر اطلاعات بازیابیشده از اسناد و دادههای معتبر سازمانی، احتمال تولید اطلاعات نادرست کاهش مییابد.
- دسترسی به دانش بهروز: امکان استفاده از جدیدترین گزارشهای ماهانه، آمارهای لحظهای ایستگاهها، نتایج آزمایشهای کیفیت آب و تصمیمهای جلسات فنی، بدون نیاز به آموزش مجدد مدل.
- شفافیت و قابلیت ردیابی: امکان ارائه منابع و مراجع دقیق (مانند شماره گزارش، تاریخ سند، نام ایستگاه) برای هر پاسخ، که اعتماد کارشناسان و مسئولان تصمیمگیر را افزایش میدهد.
- تخصصیسازی حوزهای: با استفاده از منابع دانش تخصصی در حوزه آب (مانند هیدرولوژی، هیدرولیک، مدیریت کیفی)، سیستم میتواند دقت بالاتری در تحلیل مسائل مربوط به حوضه آبی خراسان رضوی داشته باشد.
- هزینه و کارایی: نیازی به آموزش مجدد مدلهای بزرگ و پرهزینه نیست و فقط با بهروزرسانی مخزن اسناد سازمانی (Knowledge Base) میتوان سیستم را بهبود داد.
در حوزه مدیریت منابع آب، RAG میتواند در کاربردهای متنوعی مورد استفاده قرار گیرد، از جمله پاسخ به سوالات فنی کارشناسان، تحلیل روند آمارهای تاریخی، خلاصهسازی گزارشهای پیچیده پروژههای آبی، استخراج خودکار مفاد کلیدی از قراردادها، و پشتیبانی از تصمیمگیریهای مدیریتی بر اساس شواهد مستند. استفاده از RAG در این حوزهها میتواند منجر به بهبود قابلتوجه در دقت تحلیلها، سرعت دسترسی به اطلاعات و کارایی فرآیندهای تصمیمسازی در شرکت آب منطقهای شود.
ساختار نظری پارسا
روش کار بر اساس بازیابی اطلاعات احتمالی (Probabilistic Information Retrieval) است
بازیابی اطلاعات احتمالی یک پارادایم بنیادین در علم کامپیوتر است که مسئله جستجو را نه به صورت یک مسئله بولی (مرتبط/غیرمرتبط)، بلکه به صورت یک مسئله تخمین احتمال مدل میکند. هدف اصلی این است که برای هر سند D در یک مجموعه، احتمال مرتبط بودن آن را با توجه به پرسش کاربر Q محاسبه کنیم.
این احتمال به صورت P(R=1 | D, Q) نمایش داده میشود که در آن:
R=1رویداد “سند مرتبط است” را نشان میدهد.DوQبه ترتیب سند و پرسش هستند.
اصل رتبهبندی احتمالی (Probability Ranking Principle - PRP) بیان میکند که اگر سیستم جستجو اسناد را بر اساس P(R=1 | D, Q) به صورت نزولی رتبهبندی کند، کارایی کلی سیستم برای کاربر بهینه خواهد بود. این اصل، سنگ بنای تمام الگوریتمهای رتبهبندی احتمالی است.
مدل رتبهبندی احتمالی و ظهور BM25
مدلهای اولیه احتمالی، مانند مدل استقلال دوتایی (Binary Independence Model - BIM)، فرضهای سادهکنندهای داشتند:
- وجود یا عدم وجود هر اصطلاح در یک سند (باینری).
- استقلال آماری اصطلاحات از یکدیگر.
اگرچه این مدلها پایههای نظری را بنا نهادند، اما در عمل عملکرد ضعیفی داشتند. الگوریتم BM25 (Best Match 25) یک مدل تجربی و اکتشافی (Heuristic) است که با رها کردن برخی از این فرضهای سادهکننده و افزودن پارامترهای قابل تنظیم، به طور چشمگیری عملکرد را بهبود بخشید. BM25 در واقع یک تابع امتیازدهی است که به عنوان تخمینی برای P(R=1 | D, Q) عمل میکند.
تحلیل ریاضی پیشرفته تابع BM25
تابع امتیازدهی BM25 برای یک پرسش Q شامل n اصطلاح (q_1 تا q_n) و یک سند D به صورت زیر تعریف میشود:
در اینجا، هر بخش از فرمول دارای پیچیدگی و توجیه ریاضی خاص خود است.
۱. بخش وزندهی اصطلاح (IDF)
بخش IDF در BM25 در واقع وزن Robertson-Sparck Jones (RSJ) است که از تئوری اطلاع نشأت میگیرد. این وزن، لگاریتم نسبت شانس (log-odds) مرتبط بودن یک سند در صورت وجود یک اصطلاح را تخمین میزند.
\[\text{IDF}(q_i) = \log\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5}\]تحلیل پیشرفته این بخش:
- N: تعداد کل اسناد در مجموعه.
- n(q_i): تعداد اسنادی که حاوی اصطلاح
q_iهستند. - +0.5: این مقدار یک تکنیک هموارسازی (Smoothing) است. از دو جهت حیاتی است:
- از تقسیم بر صفر جلوگیری میکند (اگر
n(q_i) = N). - برای اصطلاحاتی که در هیچ سندی دیده نشدهاند (
n(q_i) = 0)، یک وزن منفی و متناهی اختصاص میدهد که از بینهایت شدن لگاریتم جلوگیری میکند.
- از تقسیم بر صفر جلوگیری میکند (اگر
- این تابع، وزن بالایی به اصطلاحات نادر و خاص میدهد و به اصطلاحات رایج، وزن کمی (حتی منفی) اختصاص میدهد که با شهود ما از اهمیت کلمات همخوانی دارد.
۲. بخش نرمالسازی فرکانس (TF)
بخش فرکانس اصطلاح (TF) در BM25 یک تابع غیرخطی است که فرکانس خام یک اصطلاح را به یک امتیاز نرمالشده تبدیل میکند.
\[\text{TF}(q_i, D) = \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}\]تحلیل پیشرفته این بخش:
f(q_i, D): فرکانس خام اصطلاحq_iدر سندD.k_1: این پارامتر، نرخ اشباع (Saturation Rate) را کنترل میکند. این یک تابع Elo-style است که به یک مجانب (asymptote) میل میکند. با افزایشf(q_i, D)، امتیازTFبهk_1 + 1نزدیک میشود و هرگز از آن فراتر نمیرود. این ویژگی از تأثیر بیش از حد تکرار یک کلمه جلوگیری میکند.b: این پارامتر، نرمالسازی طول سند را مدیریت میکند. این یک نرمالسازی مبتنی بر محور (Pivot-based) است.|D|: طول سندD(مثلاً تعداد کلمات).avgdl: میانگین طول اسناد در کل مجموعه.- اگر
|D| = avgdlباشد، عبارت داخل پرانتز به1تبدیل میشود. - اگر
|D| > avgdlباشد (سند بلندتر از حد متوسط)، مخرج بزرگتر شده و امتیازTFکاهش مییابد (جریمه برای طول). - اگر
|D| < avgdlباشد (سند کوتاهتر از حد متوسط)، مخرج کوچکتر شده و امتیازTFافزایش مییابد (پاداش برای خلاصه بودن).
این ساختار ریاضی تضمین میکند که یک کلمه در یک سند کوتاه و متمرکز، امتیاز بالاتری نسبت به همان کلمه در یک سند طولانی و پراکنده دریافت میکند.
تعمیمها و مدلهای مرتبط
چارچوب بازیابی اطلاعات احتمالی به BM25 محدود نمیشود و مدلهای پیشرفتهتری از آن توسعه یافتهاند:
۱. BM25F (BM25 with Fields)
این تعمیم برای اسنادی با ساختار چندبخشی (Multi-field) مانند <title>, <body>, <author> طراحی شده است. BM25F به هر بخش، پارامترهای k_1 و b مجزا میدهد و سپس امتیازات را ترکیب میکند.
در اینجا w_j وزن بخش j است. این مدل برای اسناد مدرن وب و ساختارهای اطلاعاتی پیچیده بسیار قدرتمند است.
۲. چارچوب DFR (Divergence From Randomness)
این چارچوب رویکردی متفاوت اما مرتبط دارد. امتیاز یک اصطلاح بر اساس میزان واگرایی (Divergence) فرکانس مشاهدهشده آن از یک مدل احتمالی تصادفی (مانند توزیع پواسون یا هایپرجئومتریک) محاسبه میشود. الگوریتم DPH یکی از مشهورترین مدلهای این چارچوب است که عملکردی قابل رقابت با BM25 دارد.
کاربرد در معماریهای مدرن (مانند RAG)
در یک سیستم Retrieval-Augmented Generation (RAG) هیبریدی، بازیابی اطلاعات احتمالی (با پیادهسازی BM25) نقشی حیاتی ایفا میکند:
- دقت واژگانی (Lexical Precision): BM25 در یافتن اسنادی که شامل کلمات کلیدی دقیق پرسش هستند، بینظیر است. این ویژگی برای پرسشهایی که شامل اسامی اختصاصی، کدها یا اصطلاحات فنی دقیق هستند، ضروری است.
- مکمل جستجوی معنایی: جستجوی معنایی (مبتنی بر Embedding) در درک مفهوم و پارافریز قوی است اما ممکن است در تطبیق دقیق کلمات کلیدی ضعیف عمل کند. ترکیب نتایج این دو (مثلاً با الگوریتم Reciprocal Rank Fusion - RRF)، یک سیستم بازیابی جامع و قوی ایجاد میکند که هم پوشش معنایی و هم دقت واژگانی را پوشش میدهد.
مراجع
[1] Lewis, P., Perez, E., Piktus, A., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS).
[2] Gao, L., et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv preprint.
[3] S. Keshvari, F. Saeedi, H. Sadoghi Yazdi, and F. Ensan, "A Self-Distilled Learning to Rank Model for Ad Hoc Retrieval," ACM Transactions on Information Systems, vol. 42, no. 6, pp. 1-28, 2024. doi: https://doi.org/10.1145/3681784
[4] S. Keshvari, F. Ensan, and H. Sadoghi Yazdi, "ListMAP: Listwise learning to rank as maximum a posteriori estimation," Information Processing and Management, vol. 59, Art. 102962, 2022. doi: https://doi.org/10.1016/j.ipm.2022.102962