RAG: تولید تقویتشده با بازیابی
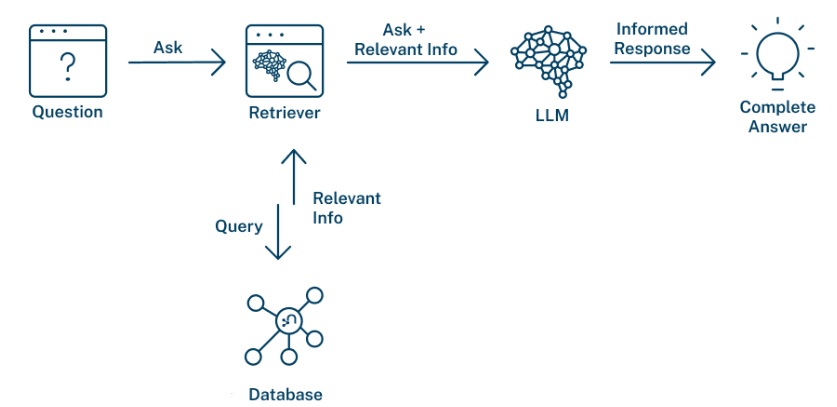
RAG یا Retrieval-Augmented Generation یک معماری پیشرفته در حوزهی هوش مصنوعی و پردازش زبان طبیعی (NLP) است که برای بهبود کیفیت و دقت مدلهای تولید زبان (مانند چتباتها) طراحی شده است.
مشکل اصلی: هذلگویی (Hallucination)
مدلهای زبانی بزرگ (LLMs) گاهی اوقات اطلاعات نادرست یا ساختگی تولید میکنند، چرا که دانش آنها تنها به دادهای که با آن آموزش دیدهاند محدود است و به منابع خارجی دسترسی ندارند.
راهحل RAG: ترکیب بازیابی و تولید
RAG این مشکل را با دو مرحله اصلی حل میکند:
- بازیابی (Retrieval):
- سوال کاربر دریافت میشود.
- سیستم با استفاده از یک موتور جستجو (مثلاً برداریشناسی یا Vector Search)، مرتبطترین اسناد و اطلاعات را از یک پایگاه دانش خارجی (مثل پایگاه داده، ویکیپدیا، اسناد داخلی شرکت و…) پیدا میکند.
- تولید تقویتشده (Augmented Generation):
- اطلاعات بازیابیشده به همراه سوال اصلی کاربر، به عنوان “زمینه” (Context) به مدل زبانی ارائه میشود.
- از مدل خواسته میشود تا پاسخی تولید کند که هم بر اساس دانش از پیش آموختهشدهی خودش و هم بر اساس اسناد ارائهشده باشد.
مزایای کلیدی
- دقت پاسخها مبتنی بر حقایق و مستندات هستند.
- بهروزرسانی آسان: برای بهروزرسانی دانش مدل، فقط کافی است پایگاه دانش را تغییر دهید (نیازی به آموزش مجدد مدل نیست).
- شفافیت: میتوان منبع اطلاعاتی که پاسخ بر اساس آن تولید شده را ردیابی کرد.
- کاهش هذلگویی: احتمال ساخت اطلاعات غیرواقعی به شدت کاهش مییابد.
کاربردها
- چتباتهای پشتیبانی مشتری
- سیستمهای پرسش و پاسخ (Q&A)
- خلاصهسازی اسناد تخصصی
- دستیارهای هوشمند بر اساس دادههای داخلی سازمان
در آموزش
این مقاله یک مرور جامع و سیستماتیک از کاربرد فناوری RAG در آموزش ارائه میدهد. نوآوری اصلی آن در ایجاد یک نقشه راه است که کاربردهای عملی، مبانی فنی و چالشهای این حوزه را دستهبندی میکند. در واقع، این بررسی نشان میدهد چگونه RAG با رفع مشکلات مدلهای زبان بزرگ (مانند توهم و دانش قدیمی)، میتواند دقت و کارایی برنامههای هوش مصنوعی آموزشی را به شدت افزایش دهد.
Li, Z., Wang, Z., Wang, W., Hung, K., Xie, H., & Wang, F.L. (2025). Retrieval-augmented generation for educational application: A systematic survey. Computers and Education: Artificial Intelligence, 8, 100417.
در دستورالعمل دارویی
این پژوهش نشان میدهد که ادغام تولید تقویتشده با بازیابی (RAG) با بروشورهای اطلاعات بیمار، کیفیت و ایمنی دستورالعملهای دارویی تولید شده توسط مدلهای زبان بزرگ را به طور قابل توجهی بهبود میبخشد. مدل تقویتشده با RAG با افزایش کفایت و وضوح و کاهش چشمگیر خطاهای حیاتی، عملکرد بهتری نسبت به مدلهای مبتنی بر مهندسی پرامپت از خود نشان داد. این رویکرد، روشی امیدوارکننده برای افزایش ایمنی بیمار در سیستمهای نسخهنویسی الکترونیکی ارائه میدهد [1].
[1] de Jesus, D. d. R., Júnior, A. P. d. S., de Albergaria, E. T., Pagano, A. S., de Oliveira, I. J. R., dos Santos Dias, C., … & Reis, Z. S. N. (2025). Enhanced LLM-supported instructions for medication use through retrieval-augmented generation. Computers in Biology and Medicine, 198, 111135.
در مراقبت بالنی بعد از جراحی
این مقاله بررسی میکند که چگونه مدلهای تولید تقویتشده با بازیابی (RAG) میتوانند با غلبه بر محدودیتهای مدلهای زبان بزرگ، دقت و شفافیت را در پشتیبانی از تصمیمگیری بالینی جراحی پلاستیک افزایش دهند. این چارچوبها با ادغام منابع پزشکی معتبر، خطاهایی مانند توهمزایی را کاهش داده و مسیرهای استدلالی شفاف ارائه میدهند. اگرچه این فناوری پتانسیل بالایی در زمینههایی مانند آموزش بیمار و مستندسازی جراحی دارد، اما اجرای آن نیازمند نظارت دقیق بر پایگاه داده، رعایت ملاحظات اخلاقی و آموزش کاربران است [1].
[1] Ozmen, B. B., & Mathur, P. (2025). Evidence-based artificial intelligence: Implementing retrieval-augmented generation models to enhance clinical decision support in plastic surgery. Journal of Plastic, Reconstructive & Aesthetic Surgery, 104, 414–416.
در همراهی با کنترلر PID
مدل MFEGPT یک مدل زبان بزرگ چندوجهی سبکوزن است که با الهام از کنترلکننده PID طراحی شده تا درک جزئیات فضایی را در مدلهای موجود بهبود بخشد. این مدل با استفاده از یک رمزگذار بصری سهشاخه و یک پروژکتور تقویتشده، با تنها ۲.۸ میلیارد پارامتر عملکردی رقابتی با مدلهای ۱۳ میلیارد پارامتری ارائه میدهد. این رویکرد، کارایی سختافزاری بالایی را تضمین کرده و امکان استقرار بر روی دستگاههای با VRAM محدود را فراهم میسازد [1].
[1] Li, H., Jia, Z., Zhang, X., Leng, C., Li, H., Gao, H., Liu, J., & Liu, Q. (2025). MFEGPT: A PID controller-inspired multimodal feature enhancement for MLLMs. Neurocomputing, 652, 131114.
تاریخچه نگری در دستیار هوشمند
این پژوهش با ارائه استراتژیهای نوآورانه، مشکل نادیده گرفتن اطلاعات تاریخی در مکالمات چندبخشی را حل میکند. این روشها با ادغام نتایج جستجوی پیشین، مدلسازی وابستگی بین بخشهای گفتگو و فیلتر هوشمندانه شواهد مفید، زمینه گفتگو را غنیتر میسازند. در نتیجه، این رویکرد کیفیت پاسخدهی را به طور قابل توجهی (حدود ۱۰ درصد) بهبود میبخشد و عملکردی به مراتب بهتر از روشهای پایهای از خود نشان میدهد [1].
[1] Mo, F., Gao, Y., Wu, Z., Liu, X., Chen, P., Li, Z., Wang, Z., Li, X., Jiang, M., & Nie, J.-Y. (2026). Leveraging historical information to boost retrieval-augmented generation in conversations. Information Processing & Management, 63(2, Part B), 104449.
اجرای سیستم RAG نمونه
فلوگرام RAG
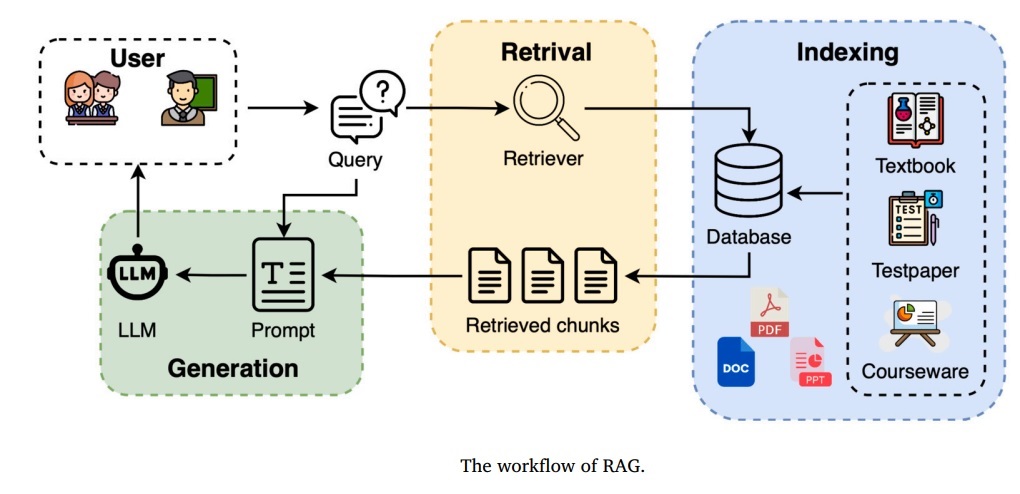
پایگاه دانش خارجی: تعریف و محتوا
پایگاه دانش خارجی به مجموعه ای ساختاریافته یا نیمهساختاریافته از اطلاعات اطلاق میشود که مدل زبانی در زمان آموزش خود آن را ندیده است.
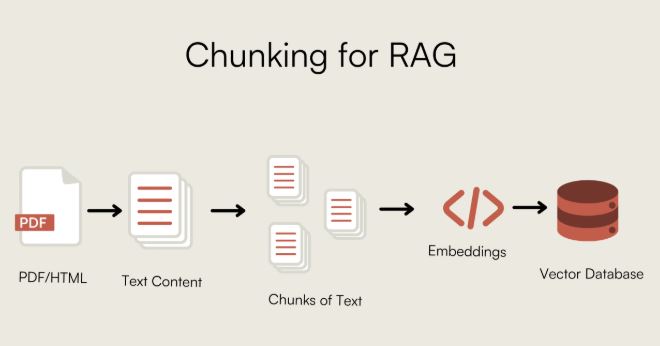
پیشپردازش و تقسیمبندی (Chunking)
قبل از نمایهسازی، دادهها باید به تکههای کوچکتر و قابل مدیریت تقسیم شوند.
نوع داده روش پیشپردازش و تقسیمبندی متون (ساختاریافته/بدون ساختار) - تقسیمبندی ساده: بر اساس تعداد توکن (مثلاً ۵۱۲ توکن).
- تقسیمبندی مبتنی بر جداگر: استفاده از جداگرهای معنایی مانند \n\n برای جدا کردن پاراگرافها.
- تقسیمبندی سلسلهمراتبی: برای مستندات طولانی، ایجاد یک درخت از بخشها، زیربخشها و پاراگرافها. سیگنالهای یکبعدی - تقسیمبندی پنجرهای (Windowing): تقسیم سیگنال به پنجرههای همپوشان یا غیر همپوشان با طول ثابت.
- تقسیمبندی بر اساس رویداد: تقسیم سیگنال بر اساس شناسایی رویدادها (مانند شروع و پایان یک انتقال داده). سیگنالهای چندبعدی (ماتریس/تانسور) - تقسیمبندی بلوکی: تقسیم تصویر یا ماتریس به بلوکهای کوچکتر (مثلاً ۲۵۶x۲۵۶ پیکسل).
- تقسیمبندی کانالی: پردازش هر کانال (مانند R, G, B در یک تصویر) به صورت جداگانه یا ترکیبی.
یک نمونه قسمت بندی متن بدون همپوشانی و فقط بر اساس تعداد حرف

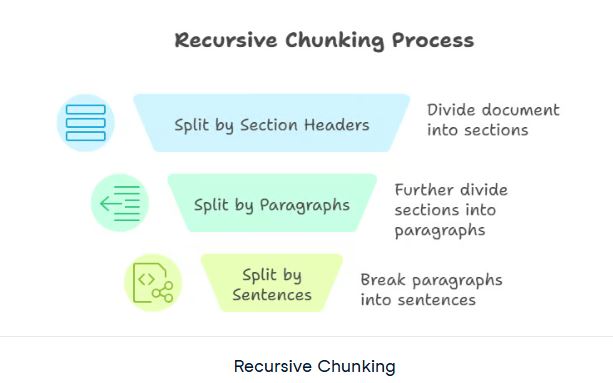
قسمت بندی بازگشتی قطعهبندی بازگشتی تکنیکی پیشرفتهتر از روشهای قبلی است. این روش، قوانین تقسیم را به صورت گام به گام اعمال میکند تا هر قطعه در یک محدوده اندازه تعریف شده قرار گیرد. به عنوان مثال، ممکن است ابتدا بر اساس سرتیترهای بخش، سپس بر اساس پاراگرافها و در نهایت بر اساس جملات تقسیمبندی کنم. این فرآیند تا زمانی که هر قطعه قابل مدیریت و در اندازه از پیش تعریف شده باشد، ادامه مییابد.
قسمت بندی معنایی در حالی که روشهای بازگشتی بر ساختار متکی هستند، قطعهبندی معنایی تمرکز را به سمت معنا تغییر میدهد و متن را بر اساس مرزهای مفهومی تقسیم میکند. قطعهبندی معنایی یک تکنیک آگاه از معنا است که از جاسازیها یا شباهت معنایی برای تقسیم متن در جایی که تغییر موضوع رخ میدهد، استفاده میکند. به جای مرزهای دلخواه، قطعات بر اساس معنا تعریف میشوند.
یک رویکرد این است که متن را به جملات تقسیم کنیم و شباهت معنایی بین آنها را اندازهگیری کنیم (مثلاً شباهت کسینوسی در جاسازیها)، و قطعات جدید را هنگام افت انسجام علامتگذاری کنیم. پیادهسازیهای پیشرفتهتر از روشهای خوشهبندی یا مدلهای تشخیص مرز تحت نظارت استفاده میکنند که تغییر موضوع را در اسناد پیچیده بهتر ثبت میکنند.
قسمت بندی با پنجره لغزان برخلاف قطعهبندی معنایی که بر انسجام معنایی تأکید دارد، قطعهبندی پنجرهای کشویی با همپوشانی قطعات و جابجایی یک پنجره در سراسر متن، بر پیوستگی تأکید میکند. به عنوان مثال، اگر از یک قطعه (پنجره) با اندازه ۵۰۰ توکن و گام ۲۵۰ استفاده کنم، هر قطعه در نیمه راه با قطعه قبلی همپوشانی دارد.
این همپوشانی، زمینه را در سراسر مرزهای قطعه حفظ میکند و خطر از دست دادن اطلاعات مهم در لبهها را کاهش میدهد. همچنین دقت بازیابی را بهبود میبخشد، زیرا چندین قطعه همپوشانی ممکن است در پاسخ به یک پرسوجو ظاهر شوند. مزیت این کار افزونگی است - همپوشانی هزینههای ذخیرهسازی و پردازش را افزایش میدهد. پنجرههای کشویی به ویژه برای متنهای بدون ساختار مانند گزارشهای چت یا رونوشتهای پادکست مفید هستند.
تقسیمبندی پویا مبتنی بر هوش مصنوعی (AI-Driven Dynamic Chunking)
فراتر از این روشهای مبتنی بر قانون و معنا، رویکردهای پیشرفتهای مانند تقسیمبندی پویا مبتنی بر هوش مصنوعی مرزها را حتی فراتر میبرند.
تقسیمبندی پویا مبتنی بر هوش مصنوعی از یک مدل زبان بزرگ (LLM) برای تعیین مستقیم مرزهای قطعهها (چانکها) استفاده میکند، نه اینکه به قوانین از پیش تعریفشده تکیه کند. مدل زبان بزرگ، سند را پویش میکند، نقاط قطع طبیعی را شناسایی کرده و اندازه قطعهها را به صورت تطبیقی تنظیم میکند.
بخشهای متراکم ممکن است به قطعات کوچکتری تقسیم شوند، در حالی که بخشهای سبکتر میتوانند در یک قطعه بزرگتر گروهبندی شوند. این امر منجر به ایجاد قطعاتی میشود که از نظر معنایی منسجم هستند و مفاهیم کامل را در بر میگیرند و در نتیجه، دقت بازیابی اطلاعات را افزایش میدهند. این روش هنگام کار با اسناد با ارزش و پیچیده—مانند قراردادهای حقوقی، راهنماهای انطباق با مقررات یا مقالات پژوهشی—که در آنها دقت بازیابی اطلاعات از سرعت پردازش یا هزینه مهمتر است، بسیار مناسب است.
Agentic chunking قسمت بندی عاملی در این روش با توجه به درخواست کاربر یا همان query تقسیم بندی صورت می گیرد بعبارتی از روی درخواست نیت کشف و سپس قسمت بندی صورت می گیرد
مثال: متن اصلی در مورد فیلترهای وفقی
«فیلترهای وفقی (Adaptive Filters) کلاسی از فیلترهای دیجیتال هستند که ضرایب خود را به صورت خودکار و بر اساس یک الگوریتم بهینهسازی، متناسب با ویژگیهای سیگنال ورودی تنظیم میکنند. هدف اصلی آنها، به حداقل رساندن یک تابع هزینه (معمولاً خطای میانگین مربعات) است که آنها را برای کاربردهایی مانند حذف نویز، اکولغاریابی و برابرسازی کانال ایدهآل میسازد.
یکی از سادهترین و پرکاربردترین الگوریتمها، الگوریتم حداقل میانگین مربعات (LMS) است. LMS از یک رویکرد کاهشی گرادیان برای بهروزرسانی ضرایب فیلتر در هر نمونه استفاده میکند. مزیت بزرگ آن پیچیدگی محاسباتی بسیار پایین و سادگی پیادهسازی است. با این حال، نرخ همگرایی آن میتواند کند باشد و به شدت به انتخاب پارامتر گام (step-size) وابسته باشد که اگر به درستی تنظیم نشود، میتواند منجر به ناپایداری شود.
در مقابل، الگوریتم حداقل مربعات بازگشتی (RLS) همگرایی بسیار سریعتری را ارائه میدهد. RLS این کار را با استفاده از تمام دادههای گذشته برای تخمین ماتریس خودهمبستگی سیگنال ورودی انجام میدهد و بهروزرسانی ضرایب را به صورت بهینه انجام میدهد. این عملکرد عالی با هزینه محاسباتی بسیار بالاتر و پیچیدگی بیشتر نسبت به LMS همراه است که استفاده از آن را در سیستمهای بلادرنگ با منابع محدود محدود میکند.
فیلتر کالمن (Kalman Filter) بر اساس اصل متفاوتی عمل میکند. این فیلتر یک تخمینگر بازگشتی بهینه برای تخمین حالت یک سیستم دینامیک است. برخلاف LMS و RLS که عمدتاً برای شناسایی سیستم یا حذف نویز استفاده میشوند، فیلتر کالمن به یک مدل دینامیکی از سیستم (مدل انتقال حالت) نیاز دارد. این فیلتر به طور گسترده در ناوبری، ردیابی و کنترل استفاده میشود و در شرایطی که نویز گوسی باشد، بهینه عمل میکند.
انتخاب فیلتر مناسب کاملاً به نیازهای کاربرد بستگی دارد. برای سیستمهایی با منابع محدود که سادگی مهم است، LMS انتخاب مناسبی است. اگر سرعت همگرایی بالا حیاتی باشد و منابع محاسباتی در دسترس باشند، RLS برتری دارد. و در نهایت، برای تخمین حالت در سیستمهای دینامیک با مدل معلوم، فیلتر کالمن ابزار قدرتمندی است.»
عمل هوشمند: تقسیمبندی متن (Chunking)
حالا فرض کنید کاربر از سیستم میپرسد:
«مقایسهای بین فیلترهای وفقی LMS و RLS و معایب و مزایای هر کدام ارائه بده.»
یک عامل هوش مصنوعی (AI Agent) با استفاده از روش تقسیمبندی عاملی (Agentic Chunking) و پویا (Dynamic)، متن بالا را به شکل زیر به قطعات (چانک) تقسیم میکند:
چانکهای تولید شده توسط سیستم هوشمند:
چانک ۱: الگوریتم LMS
«یکی از سادهترین و پرکاربردترین الگوریتمها، الگوریتم حداقل میانگین مربعات (LMS) است. LMS از یک رویکرد کاهشی گرادیان برای بهروزرسانی ضرایب فیلتر در هر نمونه استفاده میکند. مزیت بزرگ آن پیچیدگی محاسباتی بسیار پایین و سادگی پیادهسازی است. با این حال، نرخ همگرایی آن میتواند کند باشد و به شدت به انتخاب پارامتر گام (step-size) وابسته باشد که اگر به درستی تنظیم نشود، میتواند منجر به ناپایداری شود.»
چانک ۲: الگوریتم RLS
«در مقابل، الگوریتم حداقل مربعات بازگشتی (RLS) همگرایی بسیار سریعتری را ارائه میدهد. RLS این کار را با استفاده از تمام دادههای گذشته برای تخمین ماتریس خودهمبستگی سیگنال ورودی انجام میدهد و بهروزرسانی ضرایب را به صورت بهینه انجام میدهد. این عملکرد عالی با هزینه محاسباتی بسیار بالاتر و پیچیدگی بیشتر نسبت به LMS همراه است که استفاده از آن را در سیستمهای بلادرنگ با منابع محدود محدود میکند.»
چانک ۳: نتیجهگیری و مقایسه نهایی
«انتخاب فیلتر مناسب کاملاً به نیازهای کاربرد بستگی دارد. برای سیستمهایی با منابع محدود که سادگی مهم است، LMS انتخاب مناسبی است. اگر سرعت همگرایی بالا حیاتی باشد و منابع محاسباتی در دسترس باشند، RLS برتری دارد.»
دلیل و منطق تقسیمبندی هوشمند
سیستم هوشمند به این دلایل، متن را به این شکل تقسیم کرد:
- درک نیت کاربر (Agentic Chunking):
- سیستم تشخیص داد که کاربر به دنبال مقایسه LMS و RLS است.
- بنابراین، پاراگراف مربوط به فیلتر کالمن به عنوان یک موضوع متفاوت (تخمین حالت سیستم) کاملاً نادیده گرفته شد. این کار از ارائه اطلاعات اضافی و نامرتبط که ممکن است کاربر را سردرگم کند، جلوگیری میکند. این همان “استدلال در سطح بالاتر” است.
- تقسیمبندی معنایی و یکپارچه (Dynamic Chunking):
- چانک ۱ (LMS): این پاراگراف به تنهایی یک مفهوم کامل را پوشش میدهد: تعریف LMS، مزیت اصلی (سادگی و هزینه پایین) و معایب اصلی (همگرایی کند و وابستگی به پارامتر). این یک قطعه معنایی مستقل و کامل است.
- چانک ۲ (RLS): این پاراگراف نیز یک مفهوم کامل و در تقابل با چانک قبلی است: تعریف RLS، مزیت اصلی (همگرایی سریع) و عیب اصلی (هزینه محاسباتی بالا). این قطعه به گونهای طراحی شده که مستقیماً با چانک LMS قابل مقایسه باشد.
- چانک ۳ (مقایسه): این چانک، پاسخ مستقیم و خلاصهشده به سوال کاربر است. سیستم تشخیص داد که این پاراگراف نتیجهگیری، ارزش بالایی برای پاسخ نهایی دارد و آن را به عنوان یک قطعه مجزا و کلیدی استخراج کرد.
- حذف اطلاعات غیرضروری:
- پاراگراف اول متن (مقدمه کلی در مورد فیلترهای وفقی) نیز حذف شد، زیرا کاربر سوالش را مستقیماً مطرح کرده و نیازی به تعاریف اولیه ندارد. سیستم مستقیماً به سراغ اصل مطلب رفته است.
نتیجه: در اینجا، سیستم صرفاً متن را بر اساس پاراگرافها یا تعداد کلمات تقسیم نکرد. بلکه با درک هدف کاربر، یک فیلتر موضوعی اعمال کرد و سپس بخشهای مرتبط را به واحدهای معنایی مستقل و قابل مقایسه تبدیل کرد تا دقیقترین و متمرکزترین پاسخ را ارائه دهد. این همان تفاوت کلیدی بین تقسیمبندی سنتی و هوشمند است.
مباحث یادگیری ماشین مرتبط با چانکینگ
در این بخش، مجموعهای از مهمترین رویکردها و مفاهیم یادگیری ماشین که بهصورت مستقیم یا غیرمستقیم در تقسیمبندی هوشمندانهی متن و اسناد (Semantic Chunking) استفاده میشوند، مرور میشود. این روشها شامل الگوریتمهای کلاسیک، مدلهای زبانی مدرن، و رویکردهای یادگیری تقویتی هستند.
۱. خوشهبندی (Clustering)
یکی از مستقیمترین راهها برای شناسایی بخشهای معنایی مجزا در متن، استفاده از خوشهبندی است. هر جمله یا پاراگراف ابتدا به یک بردار معنایی (Embedding) تبدیل میشود، سپس الگوریتمهای خوشهبندی، گروههایی از جملات مشابه را در فضاهای برداری پیدا میکنند.
انواع الگوریتمهای خوشهبندی:
-
خوشهبندی پارامتریک (Parametric) مانند K-Means یا Gaussian Mixture Models (GMMs) که فرض میکنند دادهها از یک توزیع آماری خاص (مثلاً گاوسی) پیروی میکنند و تعداد خوشهها از پیش مشخص است.
- K-Means → بر اساس میانگین مراکز خوشه
- GMM → نسخه بیزینوارتر با احتمال تعلق هر نقطه به هر خوشه
-
خوشهبندی غیرپارامتریک (Nonparametric) مانند DBSCAN، Mean Shift یا Hierarchical Clustering که نیاز به تعیین تعداد خوشهها ندارند و بر اساس تراکم دادهها یا فاصله سلسلهمراتبی خوشهها را کشف میکنند. این نوع برای متنهای با موضوعات نامشخص یا تغییرپذیر بسیار مناسب است.
نتیجه:
هر خوشه به عنوان یک چانک معنایی در نظر گرفته میشود که شامل بخشهایی از متن با شباهت محتوایی بالا است. البته این بستگی به ترنسفورمر دارد
بحث بیشتر در کلاس درس در این زمینه با توجه به نیاز دانشجویان
۲. مدلسازی موضوع (Topic Modeling)
این روش یک گام فراتر از خوشهبندی است و به کشف موضوعات پنهان (Latent Topics) در اسناد میپردازد.
وقتی توزیع موضوعات در بخشهای متوالی متن در فضای پنهان تغییر کند، آن نقطه میتواند مرز طبیعی یک چانک جدید باشد.
۱. 🧠 درک شهودی فضای پنهان (Latent Space) در LDA
مدل LDA (Latent Dirichlet Allocation) در هسته خود، یک بازی تخصیص بیزینی انجام میدهد.
الف. متغیرهای پنهان (Latent Variables)
در تحلیل متن، شما فقط واژهها و اسناد را مشاهده میکنید. مدل LDA معتقد است که این کلمات بهصورت تصادفی تولید نشدهاند، بلکه توسط دو توزیع پنهان (که مشاهده نمیشوند) اداره میشوند:
- 🧲 $\mathbf{\Phi}$ (فی): توزیع کلمات برای هر موضوع (Topic-Word Distribution)
- تفسیر شهودی: این لیست کلمات کلیدی است که یک موضوع را تعریف میکند. اگر موضوع $k$ «فوتبال» باشد، $\phi_k$ به کلماتی مثل «گل»، «داور»، «لیگ» احتمال بالایی میدهد. (ماتریس $K \times V$ که $V$ اندازه واژگان است).
- 📈 $\mathbf{\Theta}$ (تتا): توزیع موضوعات در هر سند (Document-Topic Distribution)
- تفسیر شهودی: این ترکیببندی موضوعی هر سند است. اگر سند $d$ در مورد «فوتبال» و «سیاست» باشد، $\theta_d$ احتمال بالایی برای موضوع «ورزش» و «سیاست» و احتمال پایینی برای «آشپزی» میدهد. (ماتریس $D \times K$).
- 🏷️ $\mathbf{Z}$ (زی): تخصیص موضوع به هر کلمه (Word-Topic Assignment)
- تفسیر شهودی: پنهانترین متغیر! این نشان میدهد که هر کلمهای که در یک سند میبینیم، در واقع توسط کدام موضوع خاص تولید شده است.
نکته بیزینی: در اینجا، $\Phi$ و $\Theta$ خودشان توزیعهایی هستند که از توزیع پیشین (Prior) دیریکله ($\text{Dirichlet}(\alpha), \text{Dirichlet}(\beta)$) نمونهگیری شدهاند.
۲. 🔄 الگوریتم ساده: نمونهگیری گیبس (Collapsed Gibbs Sampling)
| از آنجا که محاسبۀ مستقیم توزیع پسین ($p(\Theta, \Phi, Z | W, \alpha, \beta)$) ناممکن است (Intractable)، از روشهای تقریب بیزینی استفاده میکنیم. نمونهگیری گیبس سادهترین روش برای درک استنتاج در فضای پنهان است. |
🔹 رویهٔ شهودی الگوریتم Gibbs Sampling
الگوریتم به صورت تکراری و گام به گام کار میکند و سعی میکند حدسهای اولیهٔ خود (تخصیصهای $Z$) را تصحیح کند:
-
شروع تصادفی: به هر کلمهای در هر سند یک موضوع تصادفی ($z_{d,n}$) تخصیص میدهیم.
-
شمارش آمار اولیه: شمارندههای زیر را بر اساس تخصیصهای تصادفی اولیه پر میکنیم:
- $n_{d,k}$ : تعداد کلمات در سند $d$ که به موضوع $k$ تخصیص یافتهاند.
- $n_{k,w}$ : تعداد دفعاتی که کلمه $w$ به موضوع $k$ تخصیص یافته است.
-
حلقهی تکرار (Iterative Sampling): برای هر کلمه $w_{d,n}$ در مجموعه سند:
-
حذف اثر: موضوع فعلی ($z_{d,n}$) را حذف میکنیم (یعنی شمارندهها را یک واحد کم میکنیم). فرض کنید اکنون کلمه شناور است و هیچ موضوعی ندارد.
-
محاسبهٔ احتمال پسین: از قانون بیز استفاده میکنیم تا ببینیم اگر این کلمه به موضوع $k$ تخصیص یابد، چقدر منطقی است. (از روی شمارندههای بهروز شده، احتمال تخصیص کلمه به موضوع $k$ را محاسبه میکنیم). این احتمال، ضرب دو بخش اصلی است:
-
تخصیص جدید (Sampling): یک موضوع جدید ($k^\star$) را بر اساس این احتمال جدید نمونهگیری (Sample) میکنیم.
-
بروزرسانی شمارندهها: شمارندهها را بر اساس تخصیص جدید $z_{d,n} = k^\star$ یک واحد اضافه میکنیم.
-
-
تکرار و همگرایی: با تکرار این فرآیند (معمولاً چند صد یا هزار بار)، تخصیصهای $Z$ به تدریج پایدار و معنادار میشوند.
🔹 شبهکد ساده Gibbs Sampling
# الف. فاز استنتاج (آموزش)
# هدف: پیدا کردن تخصیص بهینه Z
K = 20 # تعداد موضوعات
initialize counts # n_dk, n_kw, n_k
randomly assign Z
for iter in range(1000):
for each word w_dn in dataset:
# 1. حذف اثر کلمه
k_old = Z[d, n]
decrement_counts(d, k_old, w_dn)
# 2. محاسبه احتمال پسین برای هر موضوع k
P_k = {}
for k in range(K):
# قانون بیز: (احتمال موضوع در سند) * (احتمال کلمه در موضوع)
P_k[k] = (n_dk[d, k] + alpha) * \
(n_kw[k, w_dn] + beta) / (n_k[k] + V * beta)
# 3. نمونهگیری (انتخاب موضوع جدید)
k_new = sample_from(P_k)
Z[d, n] = k_new
# 4. بروزرسانی شمارندهها
increment_counts(d, k_new, w_dn)
# ب. فاز استخراج پارامترها (پس از همگرایی)
# تخمین پارامترهای پنهان با استفاده از شمارندههای نهایی (اینها پارامترهای پسین نهایی ما هستند)
# θd: توزیع موضوعات برای سند d
theta_d = (n_dk + alpha) / (sum(n_dk) + K * alpha)
# φk: توزیع کلمات برای موضوع k
phi_k = (n_kw + beta) / (n_k + V * beta)
۳. 📜 تفسیر بیزینی ریاضیات LDA (از دیدگاه پیشین-پسین)
مدل LDA یک کلاسیک بیزینی است که از توزیعهای پیشین مزدوج (Conjugate Priors) استفاده میکند.
| متغیر | توزیع پیشین (Prior) | توزیع پسین (Posterior) |
|---|---|---|
| $\mathbf{\phi}_k$ (توزیع کلمات موضوع $k$) | $\text{Dirichlet}(\beta)$ | $\text{Dirichlet}(\beta + n_{k,w})$ |
| $\mathbf{\theta}_d$ (توزیع موضوعات سند $d$) | $\text{Dirichlet}(\alpha)$ | $\text{Dirichlet}(\alpha + n_{d,k})$ |
الف. نقش توزیع دیریکله (Dirichlet Prior)
توزیع دیریکله مزدوج توزیع کاتگوریکال (Categorical) است:
- $\mathbf{\alpha}$ (پیشین $\Theta$): به عنوان یک تخمینگر بیزینی، $\alpha$ تعیین میکند که انتظار داریم هر سند چند موضوع داشته باشد.
- $\alpha$ کوچک: اسناد فقط تعداد کمی موضوع غالب دارند (اسناد تخصصی).
- $\alpha$ بزرگ: اسناد موضوعات زیادی را بهصورت یکنواخت پوشش میدهند (اسناد عمومی).
- $\mathbf{\beta}$ (پیشین $\Phi$): $\beta$ تعیین میکند که هر موضوع چقدر کلمهٔ متنوع داشته باشد.
- $\beta$ کوچک: هر موضوع فقط تعداد کمی کلمهٔ بسیار پرتکرار دارد (موضوعات متمرکز).
- $\beta$ بزرگ: کلمات بیشتری بهطور یکنواخت موضوع را تعریف میکنند.
ب. فرمول نمونهگیری گیبس (Gibbs Sampling Equation)
همانطور که در مرحلهٔ ساده دیدیم، فرمول Gibbs Sampling در واقع یک نمونه از قانون بیز است که در آن پارامترهای $\Theta$ و $\Phi$ حذف (انتگرالگیری) شدهاند:
\(\underbrace{p(z_{d,n}=k | Z_{-d,n}, W, \alpha, \beta)}_{\text{Posterior for } z_{d,n}} \propto \underbrace{\frac{n_{d,k}^{-dn} + \alpha}{\sum_{k'} (n_{d,k'}^{-dn} + \alpha)}}_{\text{Estimated }\theta_{d,k} \text{ (Document-Topic part)}} \times \underbrace{\frac{n_{k,w_{d,n}}^{-dn} + \beta_w}{\sum_{w'} (n_{k,w'}^{-dn} + \beta_{w'})}}_{\text{Estimated }\phi_{k,w} \text{ (Topic-Word part)}}\) * این فرمول به دلیل ویژگیهای توزیعهای دیریکله و کاتگوریکال، پسین (Posterior) سادهای برای تخصیص موضوع به کلمه ($z_{d,n}$) ارائه میدهد که از دو جزء پسین تخمینی ($\Theta$ و $\Phi$) تشکیل شده است.
۴. ✂️ کار با فضای پنهان در چانکینگ
پس از اجرای الگوریتم LDA، متغیرهای پنهان $\Phi$ و $\Theta$ استخراج میشوند. شما میتوانید از $\Phi$ برای درک موضوعات (کلمات کلیدی) و از $\Theta$ برای تحلیل ساختار سند استفاده کنید.
کاربرد در چانکینگ (Chunking)
ایدهٔ شما برای چانکینگ (تقسیم سند به بخشهای معنایی همگن) کاملاً بیزینی و دقیق است:
- استخراج $\theta$ محلی: سند را به بخشهای کوچک (مثلاً $seg_i, seg_{i+1}$) تقسیم کنید. با استفاده از $\Phi$ (که ثابت است)، $\theta$ جدید (توزیع موضوعی) هر بخش ($\theta_{d,seg_i}$) را تخمین بزنید (با چند گام نمونهگیری یا فرمول ساده پسین).
- اندازهگیری تغییر: با استفاده از انحراف کولبک-لایبلر (KL-Divergence)، اختلاف بین دو توزیع موضوعی مجاور را اندازه بگیرید: $$
$$\\mathrm{KL}(\\theta\_{d,seg\_i} \\parallel \\theta\_{d,seg\_{i+1}})
$$
$$
- تصمیمگیری بیزینی: اگر این تغییر بزرگتر از آستانهٔ $\tau$ باشد، نشاندهندهٔ احتمال بالای یک تغییر معنایی در ساختار پنهان است، و در نتیجه مرز چانک جدید تعیین میشود.
آیا مایلید که نحوهٔ تخمین $\theta$ برای یک سند جدید (یا یک بخش جدید) با استفاده از $\Phi$ استخراجشده را بهصورت شبهکد سادهتر توضیح دهم؟
۳. یادگیری توالی و مدلهای زبانی (Sequence Learning & Language Models)
مدلهای زبانی مدرن (مانند Transformers، BERT، GPT و Longformer) قادرند ساختار معنایی متن را بهصورت درونمتنی درک کنند. میتوان از آنها برای یادگیری مرزهای معنایی بهصورت نظارتی (Supervised) یا نظارتیضعیف (Weakly Supervised) استفاده کرد.
مثال:
مدلی را آموزش میدهیم تا با مشاهدهی هزاران سند دارای برچسبهای مرز چانک، بیاموزد که کجا تغییر معنایی یا مفهومی رخ داده است (مثلاً پایان یک بحث و آغاز بحث دیگر).
۴. تشخیص نقطه تغییر (Change Point Detection)
یک روش آماری و یادگیری ماشین برای شناسایی نقاطی که توزیع ویژگیها بهصورت ناگهانی تغییر میکند.
نحوهی استفاده در متن:
- هر جمله به ویژگیهایی مانند طول، چگالی کلمات کلیدی، یا شباهت معنایی با جملات قبلی نگاشت میشود.
- الگوریتمهایی مانند Bayesian Online Change Detection یا Kernel Change Detection، نقاطی که تغییر ناگهانی در این ویژگیها دارند را شناسایی میکنند. این نقاط معمولاً بیانگر تغییر موضوع یا سبک نوشتار هستند.
۵. یادگیری تقویتی (Reinforcement Learning)
در این رویکرد، یک عامل هوشمند (Agent) طراحی میشود که وظیفهاش تقسیمبندی بهینهی متن است. عامل با هر عمل تقسیم (Split) پاداش یا جریمه دریافت میکند.
مثال پاداش:
اگر چانکهای تولیدشده باعث بهبود عملکرد سیستم بازیابی (مثلاً RAG) شوند، عامل پاداش مثبت میگیرد. در طول زمان، عامل استراتژی بهینهی چانکینگ را یاد میگیرد.
این روش پایهای برای مفاهیم جدیدی مانند Agentic Chunking است.
۶. توصیفگرهای داده و تعبیهها (Data Descriptors & Embeddings)
در دنیای مدرن، بهترین توصیفگرهای معنایی متن Embeddingها هستند (مانند Sentence-BERT، E5 یا OpenAI Text Embeddings).
نحوهی استفاده:
با محاسبهی شباهت کسینوسی (Cosine Similarity) بین بردارهای متوالی، میتوان کاهش شدید در شباهت معنایی را به عنوان نشانهای از تغییر موضوع تشخیص داد. این کاهش معمولاً مرز طبیعی برای چانک جدید است.
۷. مدلهای ژنراتیو و خودنظارتی (Generative & Self-Supervised Models)
مدلهای جدید مانند GPT, Claude, یا Gemini با استفاده از یادگیری خودنظارتی، ساختارهای معنایی متن را بهصورت درونی میآموزند. میتوان از این مدلها برای تولید چانکهای معنایی خودکار یا پیشنهاد مرزهای احتمالی چانک استفاده کرد، بدون نیاز به دادهی برچسبدار.
۸. روشهای ترکیبی و چندوجهی (Hybrid & Multimodal Methods)
در متونی که شامل تصویر، جدول یا نمودار نیز هستند، استفاده از مدلهای چندوجهی مانند CLIP یا Multimodal Transformers به مدل اجازه میدهد مرزهای معنایی را بر اساس ترکیب محتوای متنی و تصویری تشخیص دهد.
جمعبندی
| مفهوم یادگیری ماشین | نقش مستقیم در چانکینگ |
|---|---|
| خوشهبندی | گروهبندی جملات مشابه برای تشکیل چانکهای معنایی |
| مدلسازی موضوع | کشف و جداسازی بخشهایی با موضوعات متفاوت |
| مدلهای زبانی | یادگیری مرزهای معنایی از طریق توالی و متن |
| تشخیص نقطه تغییر | شناسایی تغییرات آماری یا سبکی در متن |
| یادگیری تقویتی | یادگیری استراتژی بهینه چانکینگ بر اساس پاداش |
| Embeddingها | سنجش شباهت معنایی بین بخشهای متوالی |
| مدلهای ژنراتیو | تولید یا پیشنهاد چانکهای معنایی خودکار |
| روشهای چندوجهی | شناسایی مرزهای مفهومی با ترکیب دادههای متنی و تصویری |
FAISS چیست؟ یک راهنمای کامل
معرفی کلی
FAISS (مخفف Facebook AI Similarity Search) یک کتابخانه اوپنسورس است که توسط تیم AI Research فیسبوک (متا) توسعه داده شده است. این کتابخانه برای جستجوی شباهت بردارها (Vector Similarity Search) بهینهسازی شده است.
ابتدا پایگاه داده برداری بحث می کنیم
پایگاههای داده برداری، نسل جدیدی از سیستمهای ذخیرهسازی هستند که نه تنها دادهها را نگهداری میکنند، بلکه معنا و رابطه بین آنها را نیز درک میکنند. این فناوری در قلب تحولات هوش مصنوعی، بهویژه در کار با مدلهای زبانی بزرگ (LLM) و دادههای بدون ساختار (مانند متن، تصویر و صدا) قرار دارد. برخلاف پایگاههای داده سنتی (SQL) که بر تطابق دقیق در دادههای ساختاریافته تکیه دارند، پایگاههای داده برداری امکان جستجو بر اساس شباهت معنایی را فراهم میکنند.
چرا پایگاه داده برداری؟ مشکل چیست؟ در یک پایگاه داده سنتی، اگر دادهها به صورت بردار (تعبیه یا Embedding) ذخیره شوند، انجام یک جستجوی ساده (مثلاً یافتن مشابهترین آیتم) به دلیل دو چالش اصلی بسیار ناکارآمد خواهد بود:
- ابعاد بالا: بردارها اغلب صدها یا هزاران بعد دارند و مقایسه آنها پرهزینه است.
- مقیاسپذیری: محاسبه شباهت بین یک بردار پرسوجو و میلیونها بردار ذخیرهشده، از توان پایگاههای سنتی خارج است و پاسخدهی بلادرنگ را غیرممکن میسازد.
راهحل: پایگاه دادههای برداری این پایگاهها با استفاده از نمایههای (Indexes) ویژه و الگوریتمهای جستجوی تقریبی نزدیکترین همسایه (ANN)، فضای جستجو را بهینه کرده و امکان یافتن نزدیکترین نتایج را در کسری از ثانیه و در میان میلیاردها داده فراهم میکنند. در این سیستمها، بین سرعت و دقت یک مبادله (Trade-off) وجود دارد.
مبانی فنی: بردارها، تعبیه و جستجوی معنایی
- بردار (Vector): نمایش عددی داده (یک کلمه، تصویر یا سند) به صورت یک لیست از اعداد. کامپیوترها از این طریق میتوانند دادهها را درک و مقایسه کنند.
- تعبیه (Embedding): فرآیند تبدیل داده به بردار. این بردارها به گونهای ایجاد میشوند که دادههای مشابه از نظر معنایی (مانند “پادشاه” و “ملکه”) در فضای برداری به یکدیگر نزدیک باشند.
- جستجوی معنایی: به جای تطابق کلمه کلیدی، به دنبال درک منظور و مفهوم پرسوجو است (مثلاً تشخیص اینکه “پایتون” در یک متن برنامهنویسی به مار اشاره ندارد).
معیارهای سنجش شباهت برای مقایسه بردارها از معیارهای ریاضی مختلفی استفاده میشود، از جمله:
- شباهت کسینوسی: زاویه بین دو بردار را اندازه میگیرد (مقدار ۱ به معنای شباهت کامل).
- فاصله اقلیدسی: فاصله مستقیم بین دو نقطه را اندازه میگیرد (مقدار ۰ به معنای شباهت کامل).
پایگاههای داده برداری محبوب برخی از گزینههای شناختهشده عبارتند از:
- Pinecone: یک سرویس کاملاً مدیریتشده و کاربرپسند.
- Milvus: یک پایگاه داده منبعباز و بسیار مقیاسپذیر.
- Weaviate: پایگاه داده منبعباز با قابلیت جستجوی ترکیبی (برداری و کلمهکلیدی).
- Chroma: ساده و بهینهشده برای برنامههای مبتنی بر مدلهای زبانی بزرگ (LLM).
- FAISS: یک کتابخانه بهینهشده توسط متا برای جستجوی شباهت.
موارد استفاده کلیدی
- عوامل مکالمهای (Chatbots): ذخیرهسازی و بازیابی حافظه بلندمدت مکالمات برای پاسخدهی متنی.
- سیستمهای توصیهگر: پیشنهاد محصولات، فیلمها یا موسیقی مشابه بر اساس علایق کاربر.
- جستجوی معنایی: یافتن اسناد و محتوای مرتبط بر اساس مفهوم، نه کلمه کلیدی.
- جستجوی تصویر و ویدیو: یافتن محتوای بصری مشابه.
چالشها
- تعادل سرعت و دقت: الگوریتمهای تقریبی ممکن است همیشه دقیقترین نتیجه را برنگردانند.
- هزینه و منابع: پردازش بردارهای با ابعاد بالا به سختافزار قدرتمند نیاز دارد.
- ادغام با سیستمهای سنتی: یکپارچهسازی با پایگاههای داده رابطهای موجود میتواند پیچیده باشد.
جمعبندی نهایی پایگاههای داده برداری با امکان ذخیرهسازی و جستجوی هوشمند بر اساس معنا و شباهت، زیرساخت ضروری برای نسل جدید برنامههای هوش مصنوعی هستند. آنها با حل مشکل کار با دادههای حجیم و بدون ساختار، دنیای تعامل با ماشین را متحول کردهاند.
مشکل اصلی که FAISS حل میکند
وقتی با دادههای برداری (Vector Data) کار میکنید - مانند:
- امبدینگهای متنی
- امبدینگهای تصویری
- امبدینگهای صوتی
جستجوی مستقیم و مقایسه تمام بردارها با یکدیگر به دلیل مشکل مقیاسپذیری بسیار کند است. FAISS این مشکل را حل میکند.
چگونه کار میکند؟
الگوریتمهای اصلی
- ایندکس کردن (Indexing):
- بردارها را در ساختارهای بهینهشده ذخیره میکند
- از تکنیکهایی مانند کوانتیزاسیون (Quantization) برای فشردهسازی استفاده میکند
- جستجوی سریع:
- از الگوریتمهایی مانند IVF (Inverted File Index)
- HNSW (Hierarchical Navigable Small World)
- محاسبه فاصله (Distance Calculation) بهینهشده
انواع ایندکس در FAISS
پایهای
- IndexFlatL2: جستجوی دقیق با فاصله اقلیدسی
- IndexFlatIP: جستجوی دقیق با ضرب داخلی
بهینهشده برای حافظه
- IndexIVFFlat: ترکیب جستجوی تقریبی و دقیق
- IndexPQ: فشردهسازی پیشرفته با Product Quantization
ترکیبی
- IndexIVFPQ: ترکیب IVF و PQ برای کارایی بالاتر
نصب و راهاندازی
# برای CPU
pip install faiss-cpu
# برای GPU (اگر کارت گرافیک دارید)
pip install faiss-gpu
مثال عملی ساده
import faiss
import numpy as np
# تولید دادههای نمونه
dimension = 128 # بعد بردارها
num_vectors = 10000
# تولید بردارهای تصادفی
vectors = np.random.random((num_vectors, dimension)).astype('float32')
# ایجاد ایندکس
index = faiss.IndexFlatL2(dimension)
# افزودن بردارها به ایندکس
index.add(vectors)
# جستجوی مشابهترین بردارها
query_vector = np.random.random((1, dimension)).astype('float32')
k = 5 # تعداد نتایج
distances, indices = index.search(query_vector, k)
print("مشابهترین بردارها:", indices)
print("فاصلهها:", distances)
کاربردهای اصلی
1. سیستمهای RAG (Retrieval-Augmented Generation)
- بازیابی اسناد مرتبط برای مدلهای زبانی
- بهبود دقت پاسخهای ChatGPT-like
2. جستجوی تصویر
- پیدا کردن تصاویر مشابه
- سیستمهای توصیهگر بصری
3. جستجوی متنی
- پیدا کردن اسناد مشابه
- تشخیص محتوای تکراری
4. سیستمهای توصیهگر
- پیدا کردن آیتمهای مشابه
- توصیههای شخصیشده
مزایای کلیدی
✅ سرعت بسیار بالا
- بهینهشده برای پردازش موازی
- پشتیبانی از GPU برای سرعت بیشتر
✅ مقیاسپذیری
- توانایی مدیریت میلیونها بردار
- استفاده بهینه از حافظه
✅ انعطافپذیری
- پشتیبانی از انواع الگوریتمهای جستجو
- قابل تنظیم برای نیازهای مختلف
✅ سادگی استفاده
- API تمیز و مستندات خوب
- جامعه کاربری فعال
معایب و محدودیتها
❌ فقط ذخیرهسازی در حافظه
- دادهها با بسته شدن برنامه از بین میروند
- نیاز به مدیریت جداگانه برای ذخیرهسازی پایدار
❌ عدم پشتیبانی از متادیتا
- فقط بردارها را ذخیره میکند
- برای ذخیره اطلاعات اضافی نیاز به راهحل جانبی دارید
❌ مدیریت دستی
- نیاز به بروزرسانی دستی ایندکس
- عدم وجود قابلیتهای خودکار
مقایسه با سایر ابزارها
| ابزار | نوع | بهترین استفاده |
|---|---|---|
| FAISS | کتابخانه | نمونهسازی سریع، کاربردهای خاص |
| Pinecone | سرویس ابری | تولید، مقیاس بزرگ |
| Weaviate | دیتابیس برداری | برنامههای کامل با متادیتا |
| Chroma | دیتابیس برداری | پروژههای ساده تا متوسط |
جمعبندی نهایی
FAISS یک ابزار تخصصی و فوقالعاده کارآمد برای:
- تیمهای تحقیقاتی
- نمونهسازی سریع
- کاربردهای خاص با نیاز به عملکرد بالا
اما برای برنامههای تولیدی در مقیاس بزرگ، ممکن است نیاز به راهحلهای کاملتری مانند دیتابیسهای برداری تخصصی داشته باشید.
آزمایش
برای انجام این آزمایش ابتدا باید پایتون گونه 3.12 داشته باشید با بالاتر از آن دچار بحران! می شوید
محیط جدید
python -m venv “torch_env_fixed”
فعال کردن
torch_env_fixed\Scripts\activate
نصب ها
If you’re on CPU:
pip install faiss-cpu
If you have a CUDA GPU:
pip install faiss-gpu
pip install sentence_transformers
حالا اولین تبدیل متن به بردار
from sentence_transformers import SentenceTransformer
# Load embedding model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
docs = [
"The capital of France is Paris.",
"Machine learning is a subset of AI.",
"The Mona Lisa is in the Louvre."
]
# Encode documents into vectors
embeddings = model.encode(docs, convert_to_numpy=True)
output: [[ 0.10325696 0.03042014 0.02909579 … 0.05853157 0.08585992 -0.0056698 ] [-0.03637548 -0.02661065 0.06555219 … 0.05287919 0.06833272 -0.06037488] [ 0.00113731 -0.04676315 0.00223458 … 0.01240106 0.0471148 -0.06059993]]
import faiss
import numpy as np
# Create a FAISS index
dim = embeddings.shape[1] # vector dimension
index = faiss.IndexFlatL2(dim) # L2 distance
index.add(embeddings) # add vectors to the index
print("Number of vectors in index:", index.ntotal)
output: Number of vectors in index: 3
جستجوی 2-NN
query = "Where is the Mona Lisa located?"
query_vec = model.encode([query], convert_to_numpy=True)
# Search top-2 results
k = 2
distances, indices = index.search(query_vec, k)
for i, idx in enumerate(indices[0]):
print(f"Result {i+1}: {docs[idx]} (distance={distances[0][i]:.4f})")
output is: Result 1: The Mona Lisa is in the Louvre. (distance=0.3544) Result 2: The capital of France is Paris. (distance=1.5152)
مرحله ۵: افزودن بازیاب (Retriever) به معماری RAG
- FAISS تنها نقش بازیاب را ایفا میکند.
-
شما آن را به یک مدل مولد (مانند gpt-neo, llama.cpp یا یک فراخوان API به OpenAI/Gemini) متصل میکنید تا خط لوله کامل RAG شکل بگیرد:
۱. کاربر سوال میپرسد. ۲. بازیابی اسناد برتر (top-k) با FAISS. ۳. الحاق اسناد + سوال → ورودی به مدل زبانی بزرگ (LLM).
مثال
retrieved_docs = [docs[idx] for idx in indices[0]]
context = "\n".join(retrieved_docs)
prompt = f"Answer the question using the context:\n\n{context}\n\nQuestion: {query}"
print(prompt)
output is: Answer the question using the context:
The Mona Lisa is in the Louvre. The capital of France is Paris.
Question: Where is the Mona Lisa located?
آنچه باید از FAISS و Transformer به زبان ساده بدانیم
تشبیه ساده
Transformer
- یک مترجم متخصص که متن را به “زبان ریاضی” ترجمه میکند
- درک معنایی: متن را به بردارهای عددی تبدیل میکند
- حفظ معنا: بردارها معنای متن را حفظ میکنند
- تشابه معنایی: متون مشابه، بردارهای نزدیک دارند
- درک ظرافتهای زبانی
FAISS
- یک کتابدار فوقسریع که میداند هر کتاب (بردار) کجای کتابخانه قرار دارد
- جستجوی سریع: بردارهای مشابه را سریع پیدا میکند
- بدون درک معنایی: نمیفهمد چه چیزی شبیه چیست!
✨ نقش دقیق FAISS
۱. پایگاه داده بهینهشده برای بردارها
۲. مقیاسپذیری با دادههای بزرگ
۳. انواع الگوریتمهای بهینهشده
⚡ مقایسه سرعت
با FAISS:
- برای ۱,۰۰۰,۰۰۰ سند → ~۱۰۰-۱۰۰۰ محاسبه فاصله
- ۱۰۰۰x سریعتر!
📊 انواع Index در FAISS
| نوع Index | کاربرد | سرعت | دقت |
|---|---|---|---|
IndexFlatL2 |
دادههای کوچک | متوسط | ۱۰۰٪ |
IndexIVFFlat |
دادههای متوسط | سریع | بالا |
IndexIVFPQ |
دادههای بزرگ | بسیار سریع | خوب |
IndexHNSW |
دادههای خیلی بزرگ | فوقسریع | عالی |
🏗️ معماری RAG کامل
مرحله ۵: افزودن بازیاب (Retriever) به معماری RAG
- FAISS تنها نقش بازیاب را ایفا میکند
- آن را به یک مدل مولد متصل میکنید تا خط لوله کامل RAG شکل بگیرد
مراحل کار:
۱. کاربر سوال میپرسد
۲. بازیابی اسناد برتر (top-k) با FAISS
۳. الحاق اسناد + سوال → ورودی به مدل زبانی بزرگ (LLM)
🎯 جمعبندی نهایی
FAISS = سیستم بازیابی اطلاعات برای بردارها
- ورودی: بردار جستجو
- خروجی: نزدیکترین بردارها در پایگاه داده
- مزیت: سرعت و مقیاسپذیری
- جایگاه: بین ترنسفورمر (درک معنا) و LLM (تولید پاسخ)
Transformer = فهم معنایی
FAISS = جستجوی سریع
بدون FAISS، RAG برای دادههای واقعی غیرعملی میشود!