در این بخش، عملکرد طبقهبندها و مدلهای رگرسیون بررسی میشود. برای ارزیابی دقیق مدلها، دادهها معمولاً به دو بخش تقسیم میشوند: دادههای آموزش (Training Data) و دادههای تست (Test Data). یک روش رایج، اختصاص ۸۰ درصد دادهها به آموزش و ۲۰ درصد به تست است. از آنجایی که دادههای آموزش برچسبدار (Labeled) هستند، میتوان دقت مدل را هم در مرحله آموزش و هم در مرحله تست محاسبه کرد. در مرحله آموزش، هدف اصلی کمینه کردن خطا است، بنابراین انتظار میرود مدل روی دادههای آموزش عملکرد خوبی داشته باشد. با این حال، دقت در مرحله تست اهمیت بیشتری دارد، زیرا نشاندهنده توانایی تعمیمپذیری (Generalization) مدل به دادههای نادیده است. این تعمیمپذیری کلیدی است تا مدل در شرایط واقعی قابل اعتماد باشد.
Random Subsampling (نمونهبرداری تصادفی)
در این روش، ۸۰ درصد از دادهها به صورت تصادفی برای آموزش انتخاب میشوند و ۲۰ درصد باقیمانده برای تست استفاده میشود. هر بار اجرای این فرآیند، یک “آزمایش” یا “اجرا” (Run) نامیده میشود. برای افزایش اطمینان، میتوان این فرآیند را چندین بار (مثلاً ۱۰۰ بار) تکرار کرد و برای هر اجرا، معیارهای کارایی مانند نرخ شناسایی (Recognition Rate) را محاسبه نمود.
نرخ شناسایی با فرمول زیر محاسبه میشود:
نرخ شناسایی = (تعداد درستها) / (تعداد کل دادهها)
(رابطه ۳-۵-۱-۱: محاسبه نرخ شناسایی)
پس از محاسبه نرخ شناسایی برای همه اجراها، میانگین (Mean) و واریانس (Variance) آنها گرفته میشود تا سطح اطمینان و پایداری آزمایشها ارزیابی گردد. این روش ساده است، اما ممکن است به دلیل تصادفی بودن، نتایج متغیری تولید کند. برای بهبود، میتوان تعداد اجراها را افزایش داد.
K-Fold Validation (اعتبارسنجی متقابل K-تایی)
در این روش، دادهها به صورت تصادفی به K گروه (Fold) تقسیم میشوند. هر Fold تقریباً شامل (100/K) % از دادههاست. سپس، در هر اجرا، یکی از Foldها برای تست انتخاب میشود و باقی Foldها برای آموزش استفاده میگردند. این فرآیند برای همه K Fold تکرار میشود. برای هر اجرا، نرخ شناسایی محاسبه شده و در نهایت، میانگین و واریانس کل اجراها به دست میآید. Foldها به ترتیب انتخاب میشوند (مثلاً Fold #۱ برای تست، Fold #۲، …). این روش تعادل بهتری نسبت به Random Subsampling ایجاد میکند و از همه دادهها هم برای آموزش و هم برای تست استفاده میشود.
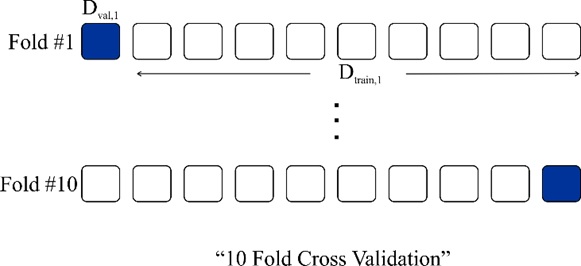
(رابطه ۳-۵-۲-۱: K-Fold Validation)
کد K-Fold Validation در زبان برنامهنویسی پایتون
در این کد نمونه، از دیتاست Fisher Iris (دادههای Iris) استفاده شده است. این دیتاست شامل اندازههای طول و عرض گلبرگ و کاسبرگ سه نوع گل (Setosa، Versicolor و Virginica) است و برای مسائل طبقهبندی مناسب است. در پایتون، از کتابخانههای scikit-learn برای تقسیم دادهها و طبقهبند KNN (نزدیکترین همسایه) و محاسبه معیارها استفاده میکنیم.
ابتدا، دادهها را لود میکنیم و Foldها را با StratifiedKFold ایجاد میکنیم (این روش تعادل کلاسها را حفظ میکند). سپس، برای هر Fold، مدل را آموزش و تست میکنیم و نرخ خطا را محاسبه میکنیم.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# لود کردن دیتاست Iris
iris = load_iris()
X = iris.data # ویژگیها (meas)
y = iris.target # برچسبها (species)
# ایجاد اندیسها برای K-Fold (K=10)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
indices = kfold.split(X, y)
# محاسبه مجموع خطاها
total_error = 0
total_correct = 0
total_samples = 0
for fold, (train_idx, test_idx) in enumerate(indices, 1):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
# طبقهبندی با KNN (مشابه classify در MATLAB)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# محاسبه نرخ درست و خطا
correct = accuracy_score(y_test, y_pred)
error = 1 - correct
total_correct += correct * len(y_test)
total_error += error * len(y_test)
total_samples += len(y_test)
print(f"Fold {fold}: نرخ درست = {correct:.4f}, نرخ خطا = {error:.4f}")
# میانگین نرخ خطا و درست
avg_error = total_error / total_samples
avg_correct = total_correct / total_samples
print(f"\nمیانگین نرخ خطا: {avg_error:.4f}")
print(f"میانگین نرخ درست: {avg_correct:.4f}")
این کد نرخ خطا را به عنوان نسبت نمونههای اشتباه طبقهبندیشده به کل نمونهها محاسبه میکند. برای جزئیات بیشتر، میتوان از confusion_matrix برای ماتریس درهمریختگی استفاده کرد.
برخی از معیارهای عملکرد
در پایتون، معیارهای عملکرد با استفاده از توابع scikit-learn محاسبه میشوند. در ادامه، معیارهای کلیدی را بررسی میکنیم (مشابه شیء classperf در MATLAB). برای سادگی، فرض میکنیم دادههای تست و پیشبینیها را داریم (از کد بالا استخراج کنید). این معیارها به درک بهتر تعادل مدل در تشخیص کلاسها کمک میکنند:
- ماتریس شمارش (Confusion Matrix):
ماتریس درهمریختگی که سطرها پیشبینیها و ستونها برچسبهای واقعی را نشان میدهد. سطر آخر برای نتایج غیرقطعی (اگر وجود داشته باشد) است، اما در KNN معمولاً همه قطعی هستند.cm = confusion_matrix(y_test, y_pred) print("ماتریس درهمریختگی:\n", cm) - نرخ تخمین درست (Correct Rate):
نسبت نمونههای درست طبقهبندیشده به کل نمونهها (بدون غیرقطعی).correct_rate = accuracy_score(y_test, y_pred) print(f"نرخ درست: {correct_rate:.4f}") - نرخ خطا (Error Rate):
نسبت نمونههای اشتباه به کل نمونهها.error_rate = 1 - correct_rate print(f"نرخ خطا: {error_rate:.4f}") -
نرخ نتایج غیرقطعی (Inconclusive Rate):
در KNN صفر است، اما اگر طبقهبند احتمالی باشد، نسبت نمونههای بدون تصمیم قطعی.
(در کد بالا، فرض بر قطعی بودن است.) - نرخ طبقهبندی (Classified Rate):
نسبت نمونههای طبقهبندیشده به کل (معمولاً ۱ در KNN).classified_rate = 1.0 # در این مورد - حساسیت (Sensitivity یا Recall):
نسبت نمونههای مثبت درست به کل مثبتهای واقعی. نتایج غیرقطعی به عنوان خطا شمرده میشوند.from sklearn.metrics import recall_score sensitivity = recall_score(y_test, y_pred, average='macro') # میانگین برای چندکلاسه print(f"حساسیت: {sensitivity:.4f}") - نرخ تشخیص (Specificity):
نسبت منفیهای درست به کل منفیهای واقعی.from sklearn.metrics import recall_score specificity = recall_score(y_test, y_pred, average='macro', pos_label=0) # برای باینری تنظیم شود # برای چندکلاسه، محاسبه دستی لازم است - مقدار پیشبینیکننده مثبت (Positive Predictive Value یا Precision):
نسبت مثبتهای درست به کل مثبتهای پیشبینیشده. غیرقطعیها به عنوان منفی شمرده میشوند.from sklearn.metrics import precision_score ppv = precision_score(y_test, y_pred, average='macro') print(f"PPV: {ppv:.4f}") - مقدار پیشبینیکننده منفی (Negative Predictive Value):
مشابه، برای منفیها. غیرقطعیها به عنوان مثبت شمرده میشوند.npv = precision_score(y_test, y_pred, average='macro', pos_label=0) # تنظیم برای باینری -
درستنمایی مثبت (Positive Likelihood):
positive_likelihood = sensitivity / (1 - specificity)
(حساسیت) / (1 - نرخ تشخیص)
- درستنمایی منفی (Negative Likelihood):
negative_likelihood = (1 - sensitivity) / specificity(1 - حساسیت) / (نرخ تشخیص)
- نرخ شیوع (Prevalence):
نسبت نمونههای مثبت واقعی به کل.prevalence = np.mean(y == 1) # برای کلاس خاص - جدول تشخیص (Diagnostic Table):
جدول ۲x۲:- سطر اول: مثبتهای پیشبینیشده (TP: مثبت درست، FP: مثبت کاذب)
- سطر دوم: منفیهای پیشبینیشده (FN: منفی کاذب، TN: منفی درست)
from sklearn.metrics import confusion_matrix tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel() print(f"TP: {tp}, FP: {fp}, FN: {fn}, TN: {tn}")درایههای قطری درستها و غیرقطریها خطاها هستند. غیرقطعیها در غیرقطریها شمرده میشوند.
این معیارها را میتوان با classification_report(y_test, y_pred) به صورت خلاصه چاپ کرد.
Leave-One-Out Cross Validation (اعتبارسنجی متقابل خارج کردن یک نمونه)
اگر تعداد دادهها کم باشد، در K-Fold هر Fold کوچک میشود (مثلاً با ۱۰۰ نمونه و K=۱۰، هر Fold ۱۰ نمونه دارد). در Leave-One-Out، هر بار یک نمونه برای تست جدا میشود و باقی برای آموزش استفاده میگردد. نرخ شناسایی برای هر نمونه محاسبه شده و میانگین/واریانس کل گرفته میشود. این روش دقیق است اما محاسباتی سنگین (برای N نمونه، N بار آموزش). هر دو روش K-Fold و Leave-One-Out، تصمیمپذیری و تعمیمپذیری را میسنجند، زیرا تست روی دادههای نادیده انجام میشود.
کد Leave-One-Out Cross-Validation در زبان برنامهنویسی پایتون
در این کد نمونه، از دیتاست carbig (دادههای خودرو) استفاده میکنیم، اما در پایتون از دادههای نمونه (Displacement و Acceleration) شبیهسازی میکنیم (مشابه MATLAB). مدل رگرسیون چندجملهای درجه ۲ فیت میشود و میانگین خطای مربعات (SSE) محاسبه میگردد. از LeaveOneOut در scikit-learn استفاده میکنیم.
import numpy as np
from sklearn.model_selection import LeaveOneOut
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt # اختیاری برای رسم
# شبیهسازی دادههای carbig (Displacement و Acceleration)
# در واقعیت، از pandas برای لود CSV استفاده کنید
np.random.seed(42)
N = 100
x = np.linspace(50, 500, N) + np.random.normal(0, 20, N) # Displacement
y = 0.001 * x**2 - 0.5 * x + np.random.normal(0, 5, N) # Acceleration (درجه ۲)
# Leave-One-Out
loo = LeaveOneOut()
sse = 0
for train_idx, test_idx in loo.split(x):
x_train, x_test = x[train_idx], x[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
# فیت مدل چندجملهای درجه ۲ (مشابه polyfit)
poly = PolynomialFeatures(degree=2)
model = LinearRegression()
pipe = Pipeline([('poly', poly), ('linear', model)])
pipe.fit(x_train.reshape(-1, 1), y_train)
y_hat = pipe.predict(x_test.reshape(-1, 1))
# جمع خطای مربعات
sse += (y_hat - y_test)**2
# میانگین خطای CV
cv_err = sse / N
print(f"میانگین خطای Cross-Validation: {cv_err:.4f}")
این کد مجموع SSE را برای همه نمونهها جمع میزند و میانگین میگیرد. توجه: هر اجرا ممکن است کمی متفاوت باشد، اما با random_state کنترل میشود. برای دادههای واقعی، فایل CSV لود کنید.