
استخراج ویژگی از صوت
مقدمه
صدا در شکلهای گوناگون پیرامون ماست. از گفتار و موسیقی گرفته تا صداهای محیطی و آوای جانوران. هرکدام اطلاعات مهمی دربارهٔ رویدادها و معنا در خود دارند. چه هدف، تشخیص گفتار باشد یا شناسایی گونههای پرندگان از روی آوازشان، نخستین گام همیشه یکی است، تبدیل سیگنال خام صدا به چیزی که رایانه بتواند بفهمد و از آن بیاموزد. گرچه میتوان شکل موج خام را مستقیم به مدل داد، اما صدا ذاتاً پُربُعد و پیچیده است. چند ثانیه صدا در نرخ نمونهبرداری معمولی، صدها هزار نمونه دارد که تنها تغییرات ریز فشار هوا را نشان میدهد، نه ویژگیهای سطح بالاتری مثل زیر و بَم، رنگ صوتی یا ریتم.
اینجاست که «استخراج ویژگی» اهمیت پیدا میکند. به جای آنکه مدل همهٔ الگوهای مفید را از صفر بیابد، سیگنال به مجموعهای از توصیفهای کلیدی تبدیل میشود که محتوای طیفی، پویایی زمانی و ساختار هارمونیک را بازتاب میدهند. این کار ابعاد داده را کم میکند، یادگیری را سریعتر و تعمیم به دادههای تازه را آسانتر میسازد. همچنین، نمایشهایی مثل مقیاس مل، شبیه شنوایی انسان عمل کرده و مدل را در برابر تغییرات جزئیِ زیر و بَم یا میکروفون مقاومتر میکند.
استخراج ویژگی علاوه بر کارایی، پایداری و تفسیرپذیری مدل را هم بالا میبرد. تمرکز بر خصوصیات ثابت و معنادار باعث میشود سیستم در محیطهای پر سر و صدا یا غیرقابل پیشبینی نیز دقیق عمل کند. از طرفی، شاخصهایی مانند مرکز ثقل طیفی یا فرکانس پایه با مفاهیمی آشنا برای مهندسان صدا و موسیقیدانان مرتبطاند و امکان ارزیابی تصمیمهای مدل را برای انسان فراهم میکنند. بهطور خلاصه، استخراج ویژگی فقط یک پیشپردازش ساده نیست، بلکه حلقهٔ واسط میان فیزیک خام صدا و مدلهای آماری است که موتور بسیاری از کاربردهای نوین صوتی محسوب میشود.
تبدیل فوریه زمان کوتاه
تبدیل فوریهٔ کوتاهمدت (STFT) روشی است برای بررسی اینکه محتوای فرکانسی یک سیگنال چگونه در طول زمان تغییر میکند. به جای آنکه یک تبدیل فوریهٔ بزرگ روی کل سیگنال (که فرض میکند سیگنال ایستا است) انجام شود، STFT سیگنال را به برشهای کوتاه و همپوشان تقسیم میکند، روی هر برش یک پنجره اعمال میکند و سپس روی هر کدام تبدیل فوریهٔ سریع (FFT) را اجرا میکند. قرار دادن این طیفهای برشبهبرش در کنار هم، یک تصویر زمان–فرکانس (که معمولاً به صورت طیفنگار یا اسپکتروگرام نمایش داده میشود) فراهم میآورد تا بتوان دید که چه زمانی برخی زیر و بمیها (pitch)، فورمانتها یا جهشهای نویزی ظاهر شده و از بین میروند. این امر در حوزهٔ صوت اهمیت اساسی دارد، زیرا صداها ایستا نیستند (واجهای گفتاری، ضربات درام، آغاز نتها)؛ STFT ضمن حفظ زمانبندی، محتوای فرکانسی را آشکار میکند و به همین دلیل نقطهٔ آغاز برای کارهایی چون تشخیص گفتار، تحلیل موسیقی و کاهش نویز به شمار میآید. در مقابل، در تبدیل فوریهٔ معمولی (FT) کل سیگنال در یکباره تحلیل میشود و اطلاعات زمانی از دست میرود؛ اگرچه در بسیاری از سیگنالها اجزای فرکانسی همواره وجود دارند اما شدت آنها در طول زمان تغییر میکند، FT تنها نشان میدهد چه اجزای فرکانسی در سیگنال هست و نمیگوید چه زمانی این اجزا پدیدار یا محو میشوند. برای سیگنالهای غیراستا (non-stationary) که طیف آنها در طول زمان تغییر میکند، نیاز به روشی است که هم اطلاعات فرکانسی و هم اطلاعات زمانی را ارائه دهد؛ STFT این مشکل را حل میکند و با برشهای کوتاه سیگنال میتوان فهمید هر جزء طیفی چه زمانی ظاهر میشود، از این رو امکان تحلیل دقیقتر سیگنالهای گفتاری، موسیقی و سایر صداهای متغیر در زمان را فراهم میسازد.
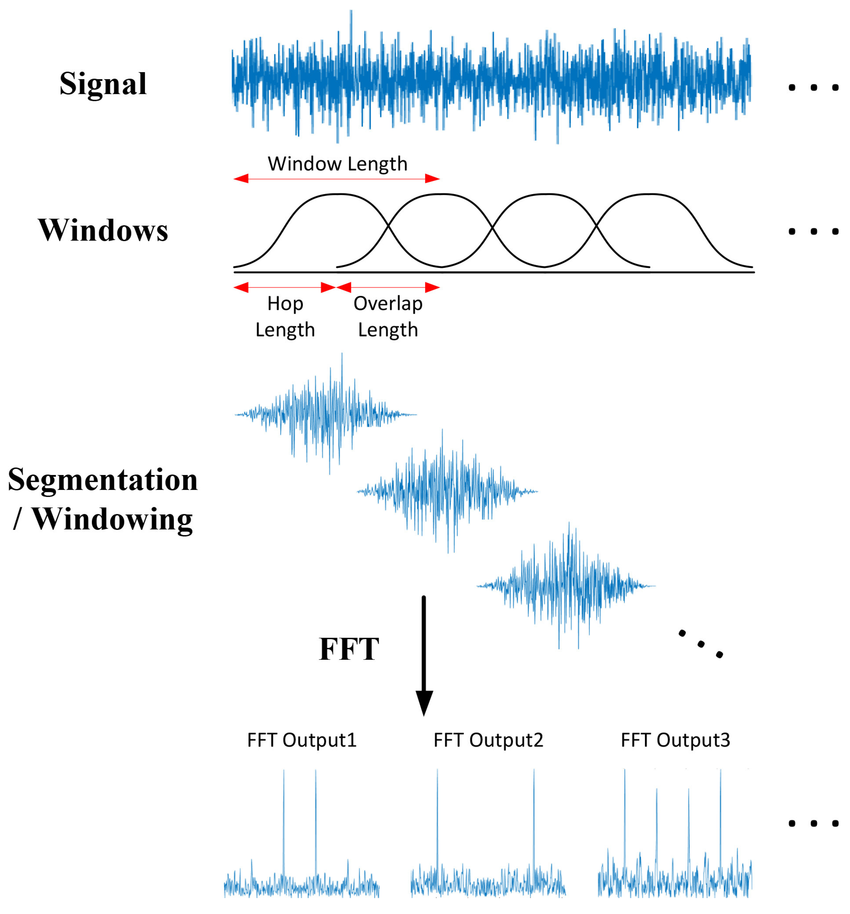
روش MFCC
روش MFCC یک تکنیک استخراج ویژگی است که بهطور گسترده در پردازش گفتار و صدا استفاده میشود. از MFCC برای نمایش ویژگیهای طیفی صدا به روشی استفاده میشود که برای وظایف مختلف یادگیری ماشین، مانند تشخیص گفتار و تحلیل موسیقی، مناسب است. به بیان سادهتر، MFCC مجموعهای از ضرایب است که شکل طیف توان (power spectrum) یک سیگنال صوتی را توصیف میکند. این ضرایب با تبدیل سیگنال صوتی خام به حوزه فرکانس (با استفاده از روشی مانند تبدیل فوریه گسسته - DFT) بهدست میآیند و سپس مقیاس مل (mel-scale) برای تقریب درک شنوایی انسان از فرکانس صدا اعمال میشود. در نهایت، ضرایب کپسترال از طیف مقیاسیافته بر اساس مل محاسبه میشوند.
این روش بهویژه مفید هست زیرا ویژگیهایی از سیگنال صوتی را برجسته میکند که برای درک گفتار انسانی مهم است، در حالی که اطلاعات کماهمیتتر را حذف میکند. به همین دلیل، این ویژگیها در کارهایی مانند شناسایی گوینده، تشخیص احساسات و تبدیل گفتار به متن بسیار مؤثرند
مراحل روش MFCC
۱. تبدیل آنالوگ به دیجیتال (A/D Conversion)
در این مرحله، سیگنال صوتی از حالت آنالوگ به دیجیتال با فرکانس نمونهبرداری ۸ کیلوهرتز یا ۱۶ کیلوهرتز تبدیل میشود.
۲. پیشتأکید (Preemphasis)
در این مرحله، انرژی فرکانسهای بالا افزایش داده میشود.
تاثیر این کار در بخشهای آوایی مانند مصوتها (مثلاً «آ»)، مشاهده میشود که انرژی در فرکانسهای بالا بسیار کمتر از فرکانسهای پایین است.
علت این مربوط به چگونگی تولید صوت توسط چینهای صوتی مرتبط است.
همچنین از دیدگاه ادراکی، انسانها زمانی که در شنیدن صداهای فرکانس بالا دچار مشکل میشوند، قدرت تمایز واجها را از دست میدهند.
از طرفی، نویز محیطی نیز غالباً در فرکانسهای بالا رخ میدهد.
تقویت انرژی در فرکانسهای بالا باعث بهبود دقت تشخیص آوا و در نتیجه بهبود عملکرد مدل میشود.
این کار توسط یک فیلتر بالاگذر(high pass) مرتبه اول انجام میشود.
۳. پنجرهگذاری (Windowing)
هدف MFCC استخراج ویژگیهایی از سیگنال صوتی است که بتوان از آنها برای تشخیص آواها (Phonemes) استفاده کرد.
چون در یک سیگنال صوتی آواهای متعددی وجود دارد، سیگنال را به قطعاتی تقسیم میکنیم که هر کدام ۲۵ میلیثانیه طول دارند و با فاصلهی ۱۰ میلیثانیه از هم قرار گرفتهاند.
از هر قطعه، ۳۹ ویژگی استخراج میشود.
برای جلوگیری از ایجاد نویز در لبههای قطعهها، بهجای پنجرهی مستطیلی از پنجرههای همینگ (Hamming) یا هنینگ (Hanning) استفاده میکنیم.
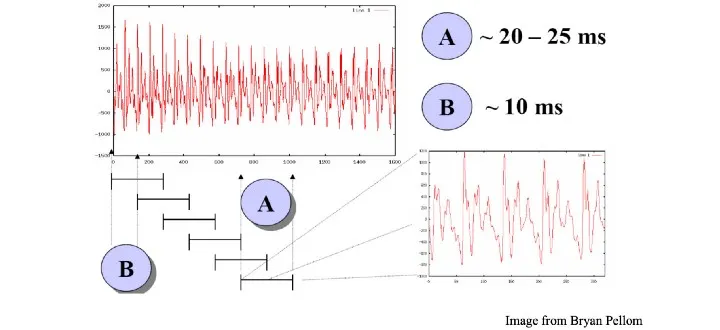
۴. تبدیل فوریه گسسته (DFT)
در این مرحله، سیگنال از حوزهی زمان به حوزهی فرکانس تبدیل میشود، زیرا تحلیل در حوزهی فرکانس برای سیگنالهای صوتی سادهتر است و به ما اجازه میدهد تا توان هر باند فرکانسی را اندازهگیری کنیم.
۵. بانک فیلتر مل (Mel-Filter Bank)
همانطور که در قسمت های قبل بیان شد، اندازهگیریهای فیزیکی با ادراک شنوایی انسان یکسان نیستند.
دراک بلندی (loudness) و تفکیکپذیری فرکانسی (frequency resolution) انسان با افزایش فرکانس کاهش مییابد. به بیان دیگر، انسانها به فرکانسهای بالاتر کمتر حساس هستند.
برای مثال، تفاوت بین ۲۰۰ و ۳۰۰ هرتز برای ما محسوستر از تفاوت بین ۱۵۰۰ و ۱۶۰۰ هرتز است، با اینکه هر دو اختلاف ۱۰۰ هرتزی دارند.
مقیاس مل (Mel Scale) تابعی غیرخطی است که فرکانسهای اندازهگیریشده را به فرکانسهای ادراکشده نگاشت میکند. در استخراج ویژگی، از مجموعهای از فیلترهای مثلثی عبور باند (triangular band-pass filters) استفاده میشود تا پاسخ ادراکی گوش انسان تقلید گردد.
ابتدا خروجی DFT به توان دوم میرسد تا طیف توان گفتار (Power Spectrum) بهدست آید. سپس فیلترهای مثلثی در مقیاس مل بر آن اعمال میشوند تا طیف توان در مقیاس مل (Mel-Scale Power Spectrum) تولید گردد.
برای شبیهسازی این ویژگی انسانی، از مقیاس مل (Mel Scale) استفاده میشود که فرکانس واقعی را به فرکانسی تبدیل میکند که انسان درک میکند.
در شکل زیر میتوان مقایسه بین مقیاس mel و log را مشاهده کرد.
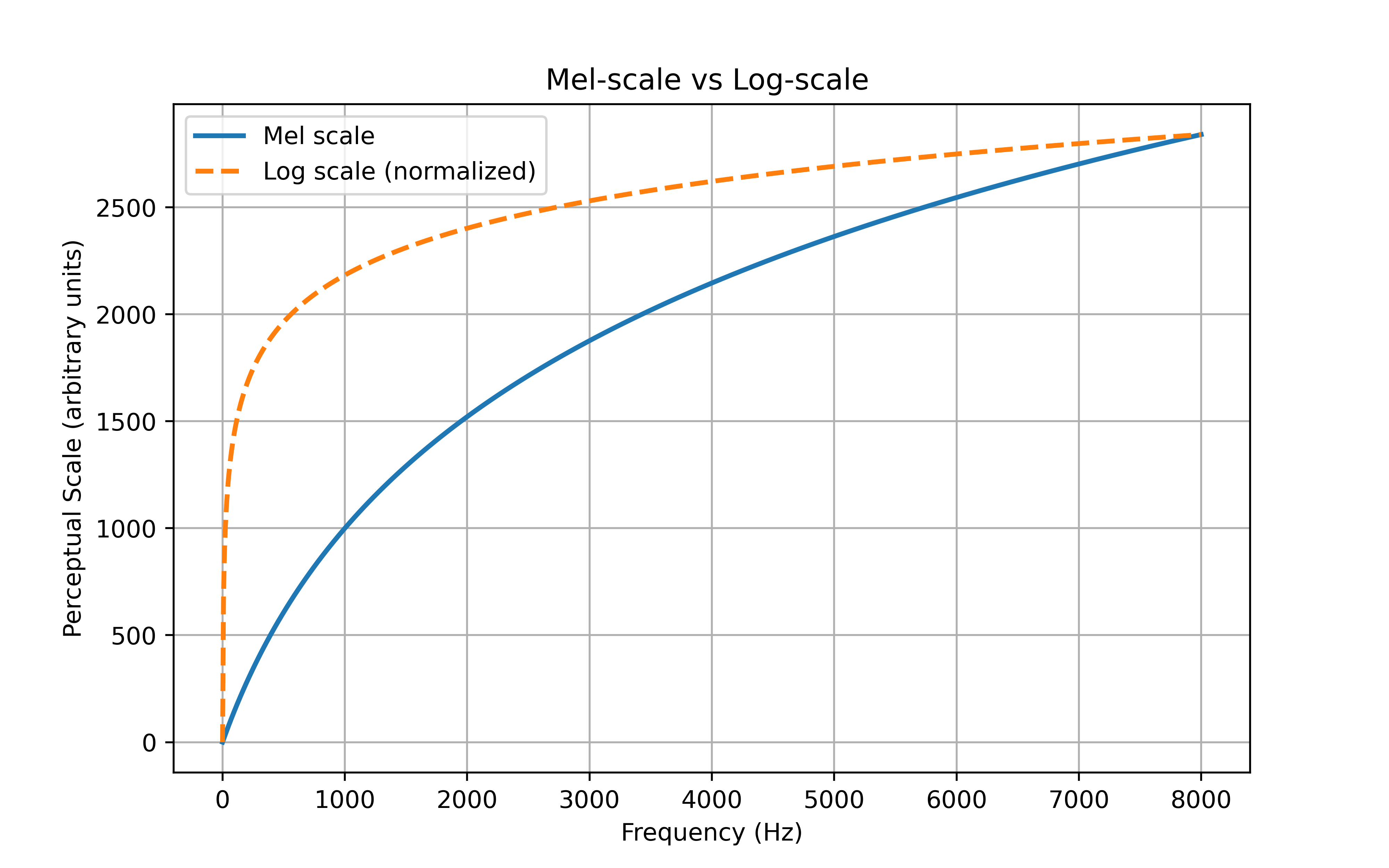
۶. اعمال تابع لگاریتم (Applying Log)
خروجی فیلتر بانک مل نمایانگر طیف توان گفتار است. از آنجا که انسانها نسبت به تغییرات کوچک در سطوح انرژی بالا حساسیت کمتری دارند (و ادراک انرژی بهصورت لگاریتمی انجام میشود)، گام بعدی گرفتن لگاریتم از خروجی فیلتر بانک مل است.
۷. تبدیل فوریه معکوس (IDFT)
در این گام، تبدیل معکوس بر خروجی مرحلهی قبل اعمال میشود تا اطلاعات مربوط به شکل طیف گفتار استخراج شود.
صدا توسط حنجره (Glottis) تولید میشود که جریان هوا را در مسیر تنفسی کنترل میکند.
ارتعاشات حاصل، فرکانس پایه (Fundamental Frequency) و هارمونیکهای آن را ایجاد میکنند.
این ارتعاشات در حفرهی صوتی (Vocal Tract) تقویت یا تضعیف میشوند، بسته به موقعیت زبان و اندامهای دیگر گفتاری.
پس از انجام IDFT، فرکانسهای مربوط به آواها شناسایی میشوند و فرکانس پایه که مربوط به زیر و بمی صدا (Pitch) است حذف میشود، چون برای تشخیص آواها کاربردی ندارد.
مدل MFCC دوازده ضریب اول حاصل از IDFT را بههمراه انرژی سیگنال بهعنوان ویژگی در نظر میگیرد.
فرمول انرژی نمونه نیز بر اساس جمع مربعات دامنهها تعریف میشود.
از نظر ریاضی، از آنجا که طیف توان لگاریتمی حقیقی و متقارن است، تبدیل فوریهی معکوس آن با تبدیل کسینوسی گسسته (DCT) معادل است.
۸. ویژگیهای پویا (Dynamic Features)
بهجز این ۱۳ ویژگی (۱۲ ضریب + انرژی)، مشتقات مرتبهی اول و دوم آنها نیز محاسبه میشود که در مجموع ۲۶ ویژگی دیگر ایجاد میکنند.
این مشتقات تغییرات بین فریمها را نشان میدهند و به درک انتقال آواها کمک میکنند.
مثال ها
در این قسمت به بررسی دو مثال می پردازیم
مثال 1: تشخیص جنسیت از روی صدا
یکی از مسائل پرکاربرد در حوزه پردازش صوت، تشخیص جنسیت، سن و سایر ویژگیهای فرد از روی صدا است. در این مثال، با استفاده از ویژگیهای استخراجشده از روش MFCC، نمایشی دوبعدی از توزیع دادهها ایجاد میکنیم.
مجموعه داده
برای این کار از مجموعه داده CommonVoice استفاده میکنیم.
نصب کتابخانههای لازم
pip install librosa datasets
دانلود دادهها
from datasets import load_dataset
ds = load_dataset("gilkeyio/AudioMNIST")
ds = ds['train']
🔉 پخش چند نمونه صوتی
انتخاب زیرمجموعه و استخراج ویژگیها (MFCC)
به دلیل حجم زیاد دادهها و زمان بالای محاسبات، تنها ۲۰۰۰ نمونه بهصورت تصادفی انتخاب میکنیم.
import numpy as np
import random
from datasets import load_dataset, Audio
import librosa
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
N_SAMPLES = 2000
SEED = 42
N_MFCC = 40
PERPLEXITY = 30
random.seed(SEED)
np.random.seed(SEED)
ds = ds.cast_column("audio", Audio(sampling_rate=16000))
ds = ds.shuffle(seed=SEED)
ds = ds.select(range(min(N_SAMPLES, len(ds))))
# فیلتر دادهها بر اساس جنسیت
valid_genders = {"male", "female"}
ds = ds.filter(lambda ex: ex.get("gender") in valid_genders)
# استخراج ویژگی MFCC
def extract_mfcc(ex):
y = ex["audio"]["array"]
sr = ex["audio"]["sampling_rate"]
if not np.isfinite(y).all():
y = np.nan_to_num(y)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=N_MFCC)
feat = np.concatenate([mfcc.mean(axis=1), mfcc.std(axis=1)], axis=0).astype(np.float32)
return {"feat": feat, "label": ex["gender"]}
ds_feat = ds.map(extract_mfcc, remove_columns=[c for c in ds.column_names if c not in ["feat", "gender"]],
desc="Extracting MFCCs")
X = np.stack(ds_feat["feat"])
y = np.array(ds_feat["label"])
🎨 نمایش دادهها با روش t-SNE
genders = np.unique(y)
markers = ["o", "s", "^", "D", "v", "P", "*"]
marker_map = {g: markers[i % len(markers)] for i, g in enumerate(genders)}
plt.figure(figsize=(8, 6))
for g in genders:
idx = (y == g)
plt.scatter(X_2d[idx, 0], X_2d[idx, 1], s=20, alpha=0.7,
marker=marker_map[g], label=g)
plt.title(f"t-SNE of MFCC features ({len(X_2d)} samples after filtering)")
plt.xlabel("t-SNE 1")
plt.ylabel("t-SNE 2")
plt.legend(title="Gender")
plt.tight_layout()
plt.show()
📈 نتیجه به صورت زیر است:
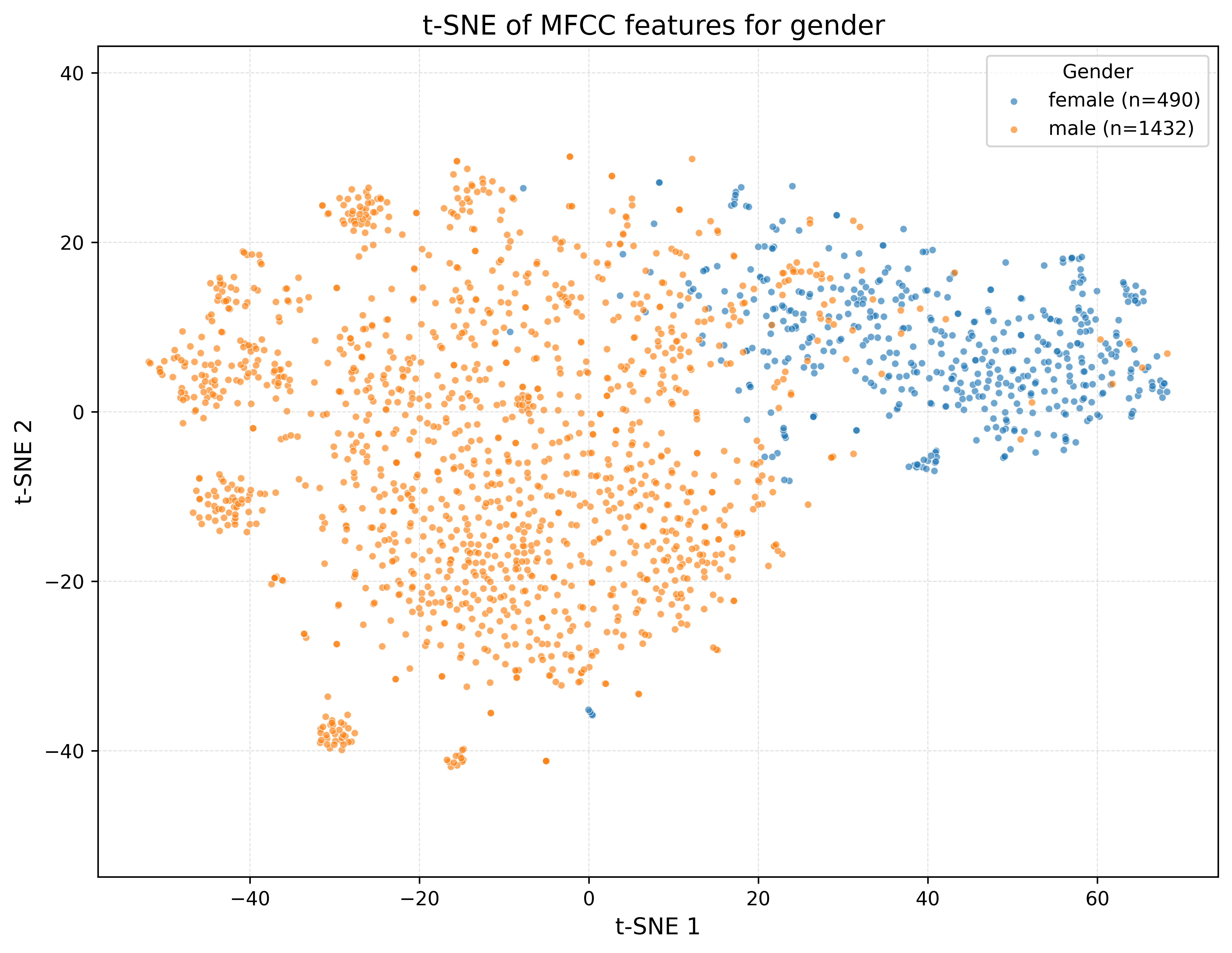
نمودار t-SNE از بازنمایی ویژگیها در دو بعد
## مثال 2 : طبقهبندی اعداد
مجموعه داده معروف MNIST شامل تصاویر اعداد دستنویس بین ۰ تا ۹ است. بهطور مشابه، مجموعه داده AudioMNIST شامل فایلهای صوتی از افراد مختلف است که اعداد بین ۰ تا ۹ را ضبط کردهاند.
🔊 نمونههایی از دادهها
لود کردن دادهها
from datasets import load_dataset
ds = load_dataset("gilkeyio/AudioMNIST") ```
---
### استخراج ویژگیها
```python
import librosa
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from datasets import load_dataset
from tqdm import tqdm
# 1. Load dataset
# 2. Extract MFCC features
mfcc_features = []
labels = []
for example in tqdm(ds['test'], desc="Extracting MFCCs"):
audio = example["audio"]["array"]
sr = example["audio"]["sampling_rate"]
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=100)
mfcc_mean = np.mean(mfcc, axis=1)
mfcc_features.append(mfcc_mean)
labels.append(example["digit"]) # or "speaker_id"
نمایش دادهها با روش t-SNE
tsne = TSNE(n_components=2, perplexity=50, random_state=42)
X_tsne = tsne.fit_transform(X)
plt.figure(figsize=(8,6))
scatter = plt.scatter(X_tsne[:,0], X_tsne[:,1], c=y, cmap="tab10", alpha=0.7)
plt.colorbar(scatter, label="Digit")
plt.title("t-SNE of MFCC features")
plt.show()
.png)
نمودار t-SNE از بازنمایی ویژگیها در دو بعد