
طبقهبندی تطبیقی متن
نویسنده: پارسا سینیچی
دانشگاه فردوسی مشهد
مهندسی کامپیوتر
[لینک ویدئو](https://www.youtube.com/watch?v=mFOEYQR7HBI)
در دنیای امروز، حجم عظیمی از دادههای متنی بهصورت روزانه تولید میشود؛ از اخبار و مقالات گرفته تا نظرات کاربران، شبکههای اجتماعی و اسناد متنی سازمانی. تحلیل و سازماندهی این دادهها بهصورت دستی نهتنها زمانبر و پرهزینه است، بلکه با افزایش مقیاس دادهها عملاً غیرممکن میشود. از سوی دیگر، در بسیاری از کاربردهای واقعی، اطلاعات اولیهی اندکی دربارهی موضوعات موجود در دادهها در دسترس است و برچسبگذاری دستی نیز امکانپذیر یا مقرونبهصرفه نیست.
هدف این پروژه، طراحی و پیادهسازی یک سیستم هوشمند برای سازماندهی، خوشهبندی و طبقهبندی تطبیقی متون فارسی است؛ سیستمی که بتواند بدون نیاز به برچسبگذاری اولیه، ساختار معنایی دادههای متنی را استخراج کرده و در مواجهه با دادههای جدید، بهصورت پویا تصمیمگیری کند.
در این پروژه، ابتدا متون خام به کمک مدلهای امبدینگ معنایی به نمایشهای عددی با ابعاد ثابت تبدیل میشوند. این بردارها محتوای مفهومی متن را در خود نگه میدارند و امکان مقایسهی متون بر اساس شباهت معنایی را فراهم میکنند، حتی در شرایطی که واژگان بهکاررفته متفاوت باشند. سپس با استفاده از الگوریتمهای یادگیری بدون ناظر، متون مشابه در قالب خوشههایی گروهبندی میشوند تا ساختار پنهان دادهها آشکار شود.
از آنجا که هر خوشه میتواند شامل تعداد زیادی سند باشد، برای درک معنای کلی هر خوشه، از مدلهای زبانی بزرگ استفاده میشود تا با تحلیل نمونههایی نماینده از هر خوشه، موضوع و توضیحی قابلفهم برای آن تولید شود. این مرحله باعث میشود بدون نیاز به بررسی تکتک اسناد، دیدی کلی و سریع نسبت به محتوای کل مجموعه به دست آید.
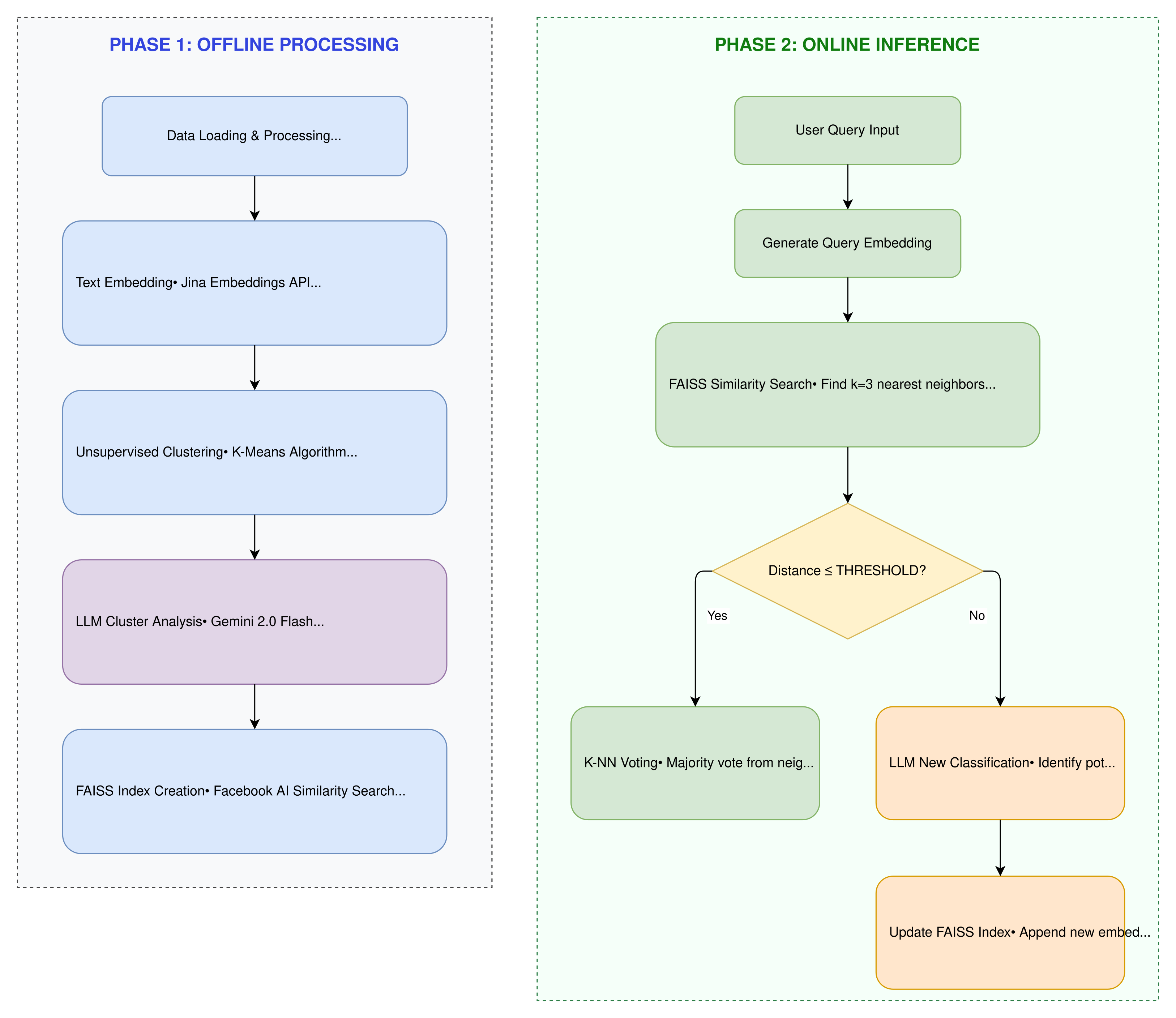
در ادامه، برای پشتیبانی از سناریوهای واقعی و دادههای ورودی جدید، از یک معماری دومرحلهای شامل پردازش آفلاین و استنتاج آنلاین استفاده شده است. در فاز آفلاین، ایندکس برداری با استفاده از FAISS ساخته میشود و خوشهها و متادیتاهای آنها ذخیره میگردند. در فاز آنلاین، هر ورودی جدید ابتدا به بردار معنایی تبدیل شده و سپس با استفاده از جستجوی شباهت و رأیگیری K-NN، به یکی از دستههای موجود تخصیص داده میشود یا در صورت عدم شباهت کافی، بهعنوان یک موضوع جدید شناسایی و به سیستم افزوده میشود.
در نهایت، این پروژه نشان میدهد که چگونه میتوان با ترکیب مدلهای امبدینگ، خوشهبندی بدون ناظر، مدلهای زبانی بزرگ و ایندکسهای برداری، یک سیستم تطبیقی و مقیاسپذیر برای تحلیل متون فارسی ایجاد کرد؛ سیستمی که هم برای تحلیل مجموعههای بزرگ متنی (مانند اخبار) و هم برای کاربردهای عملیتر مانند تحلیل احساسات مشتریان قابل استفاده است.
مطابق با شکل ۱، فرآیند کلی سیستم به دو بخش مجزا تقسیم میشود. در فاز اول (Offline Processing)، دادههای متنی خام ابتدا به بردارهای معنایی تبدیل شده و سپس با استفاده از الگوریتمهای خوشهبندی بدون ناظر سازماندهی میشوند. در فاز دوم (Online Inference)، ورودی کاربر بهصورت بلادرنگ پردازش شده و با استفاده از جستجوی شباهت در فضای برداری، دستهی مناسب برای آن تعیین میشود.
مقدمه و پیش نیاز ها
تقسیمکنندههای متن در LangChain
تقسیمکنندههای متن (Text Splitters) ابزارهایی هستند که اسناد بزرگ را به بخشهای کوچکتر تقسیم میکنند تا این بخشها بتوانند بهصورت مستقل بازیابی شوند و در محدودهٔ پنجرهٔ کانتکست مدلهای زبانی قرار بگیرند. این ابزارها یکی از اجزای پایهای در سیستمهای RAG (بازیابی-تقویتشده با تولید متن، پرسشوپاسخ روی اسناد، خلاصهسازی و ایندکسکردن محتوا در Vector Storeها هستند.
چرا به تقسیمکنندههای متن نیاز داریم؟
۱) محدودیت پنجرهٔ کانتکست
مدلهای زبانی تنها میتوانند مقدار محدودی متن را در هر درخواست پردازش کنند. با تقسیم متن، میتوان با اسنادی کار کرد که بسیار بزرگتر از ظرفیت یک پرامپت هستند.
۲) بهبود بازیابی و امبدینگ
در معماری RAG، چانکها امبد میشوند و مرتبطترین آنها بازیابی میگردند.
- اگر چانکها بیش از حد بزرگ باشند، بازیابی دچار نویز میشود.
- اگر بیش از حد کوچک باشند، معنا و زمینه از بین میرود.
تقسیمکنندهها کمک میکنند به یک نقطهٔ تعادل برسیم که هر چانک یک واحد معنایی مستقل باشد.
۳) حفظ ساختار و انسجام معنایی
برخی روشهای تقسیم، مرزهای طبیعی متن (پاراگرافها، جملات) یا ساختار اسناد (Markdown، HTML، JSON) را حفظ میکنند. این موضوع باعث میشود بخشهایی که به هم مربوط هستند، کنار هم باقی بمانند.
تقسیم کننده متن
تقسیمکنندههای متن (Text Splitters) ابزارهایی هستند که اسناد بزرگ را به بخشهای کوچکتر تقسیم میکنند تا این بخشها بتوانند بهصورت مستقل بازیابی شوند و در محدودهٔ پنجرهٔ کانتکست مدلهای زبانی قرار بگیرند. این ابزارها یکی از اجزای پایهای در سیستمهای RAG (بازیابی-تقویتشده با تولید متن، پرسشوپاسخ روی اسناد، خلاصهسازی و ایندکسکردن محتوا در Vector Storeها هستند.
چرا به تقسیمکنندههای متن نیاز داریم؟
۱) محدودیت پنجرهٔ کانتکست
مدلهای زبانی تنها میتوانند مقدار محدودی متن را در هر درخواست پردازش کنند. با تقسیم متن، میتوان با اسنادی کار کرد که بسیار بزرگتر از ظرفیت یک پرامپت هستند.
۲) بهبود بازیابی و امبدینگ
در معماری RAG، چانکها امبد میشوند و مرتبطترین آنها بازیابی میگردند.
- اگر چانکها بیش از حد بزرگ باشند، بازیابی دچار نویز میشود.
- اگر بیش از حد کوچک باشند، معنا و زمینه از بین میرود.
تقسیمکنندهها کمک میکنند به یک نقطهٔ تعادل برسیم که هر چانک یک واحد معنایی مستقل باشد.
۳) حفظ ساختار و انسجام معنایی
برخی روشهای تقسیم، مرزهای طبیعی متن (پاراگرافها، جملات) یا ساختار اسناد (Markdown، HTML، JSON) را حفظ میکنند. این موضوع باعث میشود بخشهایی که به هم مربوط هستند، کنار هم باقی بمانند.
تقسیم متن چگونه کار میکند؟
یک Text Splitter معمولاً:
- متن خام یا Documentها را دریافت میکند
- یک استراتژی تقسیم اعمال میکند (ساختاری، طولمحور و غیره)
-
خروجی میدهد:
- لیستی از رشتهها (
split_text) - یا لیستی از
Documentها بههمراه متادیتا (split_documents)
- لیستی از رشتهها (
دو پارامتر مهم:
-
chunk_size: حداکثر اندازهٔ هر چانک -
chunk_overlap: مقدار متن مشترک بین چانکهای مجاور برای حفظ پیوستگی
استراتژیهای اصلی تقسیم متن در LangChain
LangChain روشهای تقسیم را به سه دستهٔ کلی تقسیم میکند:
- مبتنی بر ساختار متن
- مبتنی بر طول
- مبتنی بر ساختار سند
تقسیم مبتنی بر ساختار متن: RecursiveCharacterTextSplitter
این تقسیمکننده ابتدا تلاش میکند واحدهای بزرگتر و طبیعی (مثل پاراگرافها) را حفظ کند. اگر یک بخش هنوز خیلی بزرگ باشد، بهصورت بازگشتی به واحدهای کوچکتر (جملات، کلمات) تقسیم میشود تا به اندازهٔ مناسب برسد.
مثال
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(document_text)
زمان مناسب استفاده:
- انتخاب پیشفرض برای متنهای ساده یا ترکیبی
- مناسب زمانی که بدون تنظیمات پیچیده، نتیجهٔ خوب میخواهید
تقسیم مبتنی بر طول
در این روش، اندازهٔ چانکها مشخص و ثابت هستند.
- مبتنی بر توکن: منطبق با نحوهٔ شمارش ورودی توسط LLM
- مبتنی بر کاراکتر: ساده و پایدار برای انواع متن
مبتنی رو توکن
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=100,
chunk_overlap=0,
)
texts = text_splitter.split_text(document_text)
تقسیم مبتنی بر ساختار/فایل
برای اسنادی که ساختار مشخصی دارند (مثل هدرهای Markdown یا تگهای HTML)، بهتر است تقسیم متن بر اساس همان ساختار انجام شود. این کار باعث میشود هر چانک یک بخش منطقی از سند باشد و کیفیت بازیابی و خلاصهسازی افزایش یابد.
تقسیم Markdown
Markdown یک نمونهٔ عالی از سند ساختاریافته است، زیرا هدرها سلسلهمراتب مشخصی دارند. LangChain برای این منظور ابزار MarkdownHeaderTextSplitter را ارائه میدهد.
تقسیم بر اساس هدرها + متادیتا
قابلیتها:
-
تقسیم متن بر اساس هدرهایی مانند
#،##،### -
خروجی بهصورت
Documentبا:-
page_content: متن بخش -
metadata: مسیر هدرها (مثلاً Header 1 = Foo، Header 2 = Bar)
-
مثال
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = """
# راهنمای برنامهنویسی پایتون
## مقدمه
پایتون یک زبان برنامهنویسی ساده و قدرتمند است.
یادگیری آن برای مبتدیان بسیار مناسب است.
### تاریخچه
پایتون توسط گیدو فان روسوم طراحی شد
و اولین بار در سال ۱۹۹۱ منتشر شد.
## کاربردها
پایتون در زمینههای مختلفی استفاده میشود.
### هوش مصنوعی
از پایتون برای یادگیری ماشین و هوش مصنوعی استفاده میشود.
### توسعه وب
فریمورکهایی مثل Django و Flask بسیار محبوب هستند.
"""
headers_to_split_on = [
("#", "عنوان اصلی"),
("##", "بخش"),
("###", "زیربخش"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
[Document(metadata={'عنوان اصلی': 'راهنمای برنامهنویسی پایتون', 'بخش': 'مقدمه'}, page_content='پایتون یک زبان برنامهنویسی ساده و قدرتمند است.\nیادگیری آن برای مبتدیان بسیار مناسب است.'),
Document(metadata={'عنوان اصلی': 'راهنمای برنامهنویسی پایتون', 'بخش': 'مقدمه', 'زیربخش': 'تاریخچه'}, page_content='پایتون توسط گیدو فان روسوم طراحی شد\nو اولین بار در سال ۱۹۹۱ منتشر شد.'),
Document(metadata={'عنوان اصلی': 'راهنمای برنامهنویسی پایتون', 'بخش': 'کاربردها'}, page_content='پایتون در زمینههای مختلفی استفاده میشود.'),
Document(metadata={'عنوان اصلی': 'راهنمای برنامهنویسی پایتون', 'بخش': 'کاربردها', 'زیربخش': 'هوش مصنوعی'}, page_content='از پایتون برای یادگیری ماشین و هوش مصنوعی استفاده میشود.'),
Document(metadata={'عنوان اصلی': 'راهنمای برنامهنویسی پایتون', 'بخش': 'کاربردها', 'زیربخش': 'توسعه وب'}, page_content='فریمورکهایی مثل Django و Flask بسیار محبوب هستند.')]
بردار های معنایی در langchain و ذخیره سازی آن ها
مقدماتی بر بردار های معنایی
مدلهای امبدینگ (Embedding) متن خام مانند یک جمله، پاراگراف یا توییت را به یک بردار عددی با طول ثابت تبدیل میکنند که معنای معنایی آن را نشان میدهد. این بردارها به ماشینها امکان میدهند متنها را بر اساس معنا، نه صرفاً تطابق دقیق کلمات، با یکدیگر مقایسه و جستوجو کنند.
در عمل، این یعنی متنهایی که ایدههای مشابهی دارند در فضای برداری به یکدیگر نزدیک قرار میگیرند. برای مثال، بهجای اینکه فقط عبارت «یادگیری ماشین» مطابقت داده شود، امبدینگها میتوانند اسنادی را پیدا کنند که درباره مفاهیم مرتبط صحبت میکنند، حتی اگر از واژهبندی متفاوتی استفاده شده باشد.
برای مطالعه بیشتر راحب نحوه عملکرد این مدل ها لینک را مطالعه کنید
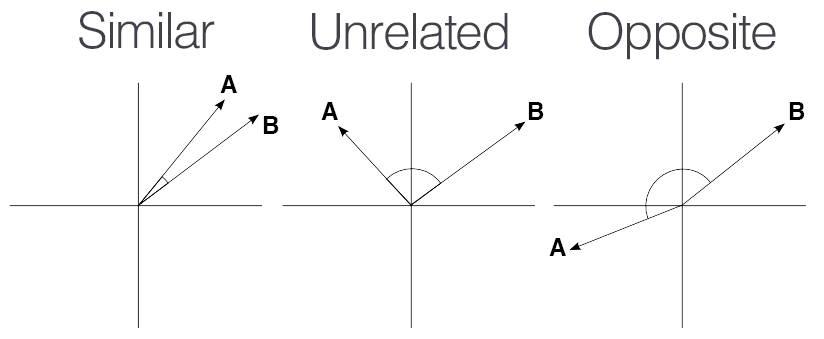
سپس برای بررسی شباهت بردار ها از معیار شباهت کسینوس استفاده میکنیم :
فرمول ریاضی شباهت کسینوسی به صورت زیر است:
\[{Cosine Similarity}(A, B) = \frac{A \cdot B}{\|A\| \times \|B\|}\]در این فرمول، $A$ و $B$ دو بردار هستند، $A \cdot B$ ضرب داخلی (dot product) آنها و $|A|$ و $|B|$ به ترتیب نرم (طول) هر بردار است. مقدار شباهت کسینوسی بین ۱ و -۱ قرار میگیرد که ۱ به معنای بیشترین شباهت و ۰ به معنای عدم شباهت (عمود بودن بردارها) است. این معیار به ویژه برای مقایسه بردارهای متنی یا معنایی بسیار پرکاربرد است.
که استفاده از آن به صورت زیر است :
def cosine_similarity(vec1, vec2):
dot = np.dot(vec1, vec2)
return dot / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
نحوه استفاده از بردار های معنایی در langchain
مدل Jina
مدل Jina Embeddings v3 سومین نسل از سامانههای چندزبانهٔ تولید بردارهای معنایی است که توسط شرکت Jina AI توسعه یافته است. این مدل برای کاربردهای عمومی در تولید امبدینگ طراحی شده و از طیف گستردهای از وظایف معنایی
در هستهٔ خود، Jina v3 یک انکودر مبتنی بر ترنسفورمر است که از معماری XLM-RoBERTa مشتق شده و بنیانی قدرتمند برای پردازش چندزبانه فراهم میکند. این مدل شامل تقریباً ۵۷۰ میلیون پارامتر است که در ۲۴ لایهٔ ترنسفورمر توزیع شدهاند
تطبیق مدل با توجه نوع مسئله
برای پشتیبانی از امبدینگهای چندوظیفهای و نقشمحور، Jina v3 از ماژولهای Low-Rank Adaptation (LoRA) در هر بلوک ترنسفورمر بهره میگیرد. این اداپتورها لایههای کوچک و قابلآموزشی هستند که بازنماییهای مدل پایه را برای نقشهای معنایی گوناگون تنظیم میکنند بدون آنکه وزنهای اصلی مدل تغییر کنند. در عمل، اداپتورهای جداگانه برای نقشهایی مانند retrieval.query، retrieval.passage، text-matching، classification و separation آموزش داده میشوند. در مرحلهٔ استنتاج، بسته به وظیفهٔ موردنظر، اداپتور مناسب فعال شده و امبدینگ بهینهٔ همان وظیفه تولید میشود.
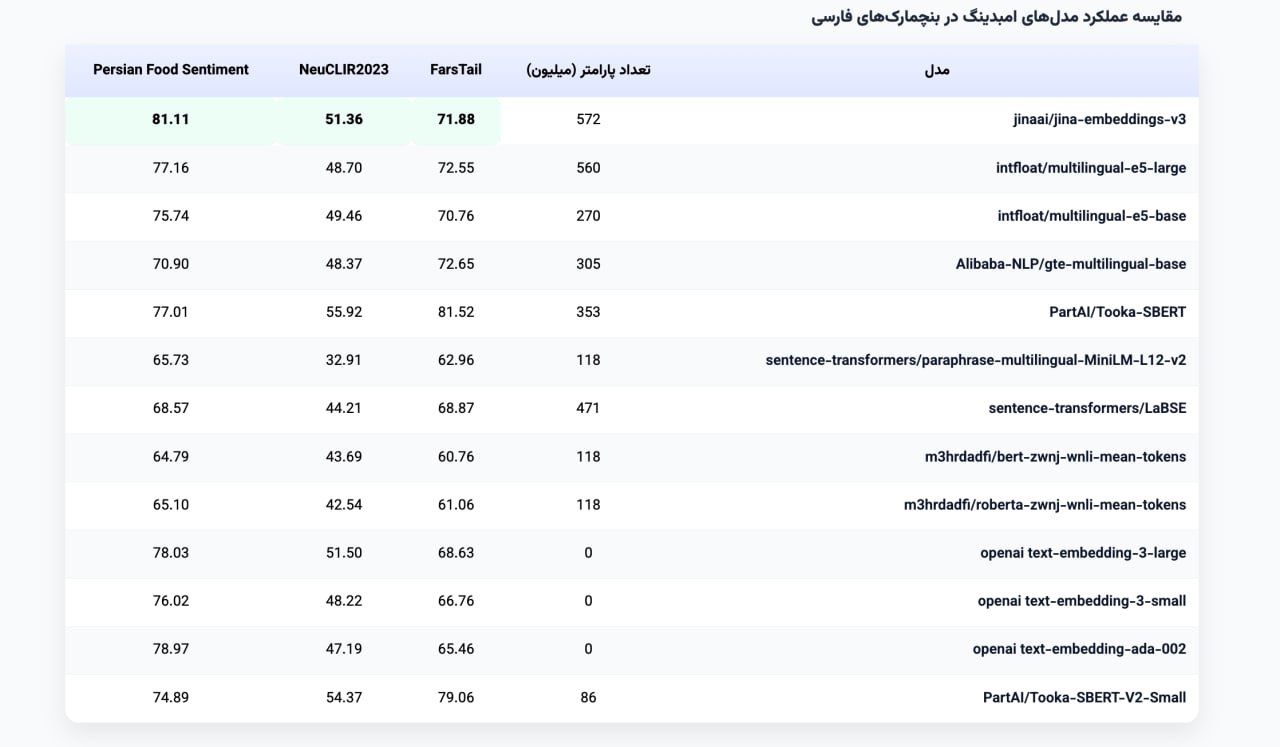
مقایسه مدل Jina در زبان فارسی با سایر مدل ها
این مدل قابلیت پشتیبانی از زبان های مختلفی از جمله فارسی را دارد، عمکلرد ای مدل نسبت به سایر مدل های موجود بهتر از و نتایج آن را در تصویر زیر میتوان مشاهده کرد.
استفاده از مدل jina در langchain
import requests
from langchain_community.embeddings import JinaEmbeddings
from numpy import dot
from numpy.linalg import norm
from PIL import Image
text_embeddings = JinaEmbeddings(
jina_api_key="", model_name="jina-embeddings-v3"
)
text1 = "علی دیروز به مدرسه رفت."
text2 = "برای اکتشاف داده ها از الگوریتم های خوشه بندی استفاده می شود."
query_result1 = text_embeddings.embed_query(text1)
query_result2 = text_embeddings.embed_query(text2)
(cosine_similarity(query_result1, query_result2))
ذخیره سازی بردار های معنایی در langchain
دلیل نیاز به دخیره سازی
مدلهای زبانی بهصورت پیشفرض به دادههای خصوصی شما دسترسی ندارند (مثل اسناد، چتها، PDFها)، چون این دادهها داخل context مدل قرار ندارند.
یک Vector Store این مشکل را حل میکند از طریق:
- Embedding کردن متن (تبدیل متن به بردارهای عددی که معنا را نمایش میدهند)
- ذخیره این بردارها
- انجام جستجوی شباهت (Similarity Search) برای پیدا کردن مرتبطترین بخشها نسبت به یک پرسش
FAISS یکی از پیادهسازیهای این ایده است: یک کتابخانهٔ بسیار سریع برای جستجوی شباهت و خوشهبندی بردارهای متراکم (dense vectors) که برای مقیاسهای بزرگ طراحی شده است.
کاربردهای رایج:
- RAG (تولید پاسخ با تکیه بر دادههای خودتان)
- جستجوی معنایی (Semantic Search)
- سیستمهای پیشنهاددهنده، تشخیص موارد مشابه یا تکراری، خوشهبندی
رابط VectorStore در LangChain
LangChain یک رابط یکسان (abstraction) ارائه میدهد تا بتوانید backendهای مختلف را بدون تغییر زیاد در کد جابهجا کنید.
عملیات اصلی:
add_documents→ افزودن اسنادdelete→ حذف با IDsimilarity_search→ جستجوی معنایی
نحوه کار با کتابخانه FAISS
1) نصب کتابخانه های مورد نیاز
ادغام FAISS در پکیج langchain-community قرار دارد و خود FAISS هم باید نصب شود (نسخهٔ CPU یا GPU).
pip install -qU langchain-community faiss-cpu
2) انتخاب یا ساخت مدل Embedding
چون FAISS فقط با بردار عددی کار میکند، ابتدا باید متن را Embedding کنیم. در مستندات از JinaEmbeddings بهعنوان مثال استفاده شده است.
from langchain_community.embeddings import JinaEmbeddings
text_embeddings = JinaEmbeddings(
jina_api_key="", model_name="jina-embeddings-v3"
)
3) مقداردهی اولیه Vector Store با FAISS
در این مرحله:
- بُعد embedding محاسبه میشود
- یک index از نوع
IndexFlatL2ساخته میشود - همهچیز داخل کلاس
FAISSدر LangChain قرار میگیرد
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
dim = len(embeddings.embed_query("hello world"))
index = faiss.IndexFlatL2(dim)
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
4) افزودن اسناد (همراه metadata و ID)
اسناد بهصورت Document اضافه میشوند (شامل متن و metadata). معمولاً برای هر سند یک UUID ساخته میشود.
from uuid import uuid4
from langchain_core.documents import Document
docs = [
Document(page_content="...", metadata={"source": "tweet"}),
Document(page_content="...", metadata={"source": "news"}),
]
ids = [str(uuid4()) for _ in docs]
vector_store.add_documents(documents=docs, ids=ids)
5) حذف اسناد با ID
vector_store.delete(ids=[ids[-1]])
6) جستجوی شباهت (Similarity Search)
یک پرسش متنی میفرستید و k نتیجهٔ نزدیکتر برگردانده میشود.
همچنین میتوانید بر اساس metadata فیلتر کنید.
results = vector_store.similarity_search(
"LangChain provides abstractions to make working with LLMs easy",
k=2,
filter={"source": "tweet"},
)
7) جستجو همراه با شباهت
در این حالت خروجی شامل (document, score) است.
results = vector_store.similarity_search_with_score(
"Will it be hot tomorrow?",
k=1,
filter={"source": "news"},
)
8) ذخیره و بارگذاری FAISS Index
برای اینکه هر بار مجبور به ساخت مجدد index نباشید.
vector_store.save_local("faiss_index")
new_vector_store = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True,
)
مثال
اضافه کردن کتابخانه های مورد نیاز
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from langchain_community.embeddings import JinaEmbeddings
import google.genai as genai
import os
import warnings
تعریف مدل ها و api
JINA_API_KEY = "API"
GOOGLE_API_KEY = "API"
embeddings_model = JinaEmbeddings(jina_api_key=JINA_API_KEY,model_name="jina-embeddings-v3")
client = genai.Client(api_key=GOOGLE_API_KEY)
لود کردن دیتا و ساخت embedding
df = pd.read_csv('per.csv')
texts = df[TEXT_COLUMN].astype(str).tolist()
embeddings_list = []
for i, text in enumerate(texts):
if (i + 1) % 10 == 0:
print(f"Processing: {i + 1}/{len(texts)}")
embedding = embeddings_model.embed_query(text)
embeddings_list.append(embedding)
embeddings_array = np.array(embeddings_list)
بررسی مثال های از داده ها
این داده ها از یک وبسایت خبری جمع آوری شده و موضوع ان ها مشخص نیست
چند نمونه از متن ها به صورت زیر است :
- طبق اعلام شبکه اسکای اسپورت محمد صلاح قبل از حضور در اردوی تیم ملی فوتبال مصر از همتیمیهایش در لیورپول عذرخواهی کرد و....
- دانشمندانی که با تلسکوپ فضایی جیمز وب کار میکنند، در اوایل سال ۲۰۲۵ سه جرم نجومی غیرمعمول را کشف کردند که ....
- محمدرضا دلپاک ( طراح صدای ایرانی عضو آکادمی اسکار ) در دانشگاه هنر توکیو حاضر شد و به تدریس پرداخت ....
خوشه بندی متن
kmeans = KMeans(n_clusters=K, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(embeddings_array)
df_sample['cluster'] = cluster_labels
انتخاب موضووع برای هر خوشه
در این قسمت با استفاده از یک مدل زبانی، موضوع هر خوشه را انتخاب میکنیم برای این کار ، مرکز هر خوشه و چند نمونه دیگر از متن های داخل خوشه را به مدل زبانی میدهیم و از آن میخواهیم که موضوع کلی خوشه را انتخاب کند برای این کار از مدل Gemini استفاده میکنیم
cluster_topics = {}
import time
print("Analyzing clusters with LLM...\n")
for cluster_id in range(optimal_k):
time.sleep(10)
cluster_texts = df_sample[df_sample['cluster'] == cluster_id]['body']
representative_sample = cluster_texts[:min(3, len(cluster_texts))]
texts_for_analysis = "\n".join([f"{i+1}. {text}..." for i, text in enumerate(representative_sample)])
prompt = f"""Analyze the following texts from a cluster and identify the main topic or theme.
Provide a concise topic name (2-4 words) and a brief description (1-2 sentences).
The possible topics are :
ورزشی
هنری و فرهنگی
علمی و فناوری
it has to be one of these, and use extact words
topic name and brief description should be in Persian
Texts:
{texts_for_analysis}
Format your response as:
Topic: [topic name]
Description: [brief description]"""
try:
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=prompt,
config={
'temperature': 0.7,
'top_p': 0.95,
'top_k': 20,
}
)
cluster_topics[cluster_id] = response.text
print(f"Cluster {cluster_id} ({len(cluster_texts)} texts):")
print(cluster_topics[cluster_id])
print("-" * 80)
except Exception as e:
cluster_topics[cluster_id] = f"Analysis error: {str(e)}"
print(f"Cluster {cluster_id}: Error - {str(e)}")
print("-" * 80)
که خروجی به صورت زیر است :
Cluster 0 (2 texts):
Topic: هنری و فرهنگی
Description: این متون به رویدادهای هنری بینالمللی مانند دوسالانه کارتون و کاریکاتور تهران و فعالیتهای هنرمندان برجسته ایرانی در عرصه سینما میپردازند. آنها بر اهمیت تبادلات فرهنگی و جایگاه هنر و هنرمندان در سطح جهانی تأکید دارند.
Cluster 1 (5 texts):
Topic: علمی و فناوری
Description: این متون به آخرین پیشرفتها و کاربردهای هوش مصنوعی توسط شرکتهای فناوری بزرگ میپردازند. توسعه مدلهای مولد، استفاده از هوش مصنوعی در بازیها و تدابیر ایمنی برای کاربران نوجوان، از جمله موضوعات اصلی مورد بحث هستند.
Cluster 2 (5 texts):
Topic: ورزشی
Description: این متون به اخبار و رویدادهای مربوط به فوتبال حرفهای، از جمله نقل و انتقالات بازیکنان، نتایج مسابقات و تحلیل عملکرد تیمها در لیگهای معتبر میپردازند.
نمایش نتایج خوشه بندی
در این قسمت به کمک PCA داده ها را به صورت دو بعدی نمایش میدهیم و مراکز خوشه ها را نیز نشان میدهیم
pca = PCA(n_components=2, random_state=42)
embeddings_pca = pca.fit_transform(embeddings_array)
plt.figure(figsize=(12, 8))
scatter = plt.scatter(
embeddings_pca[:, 0],
embeddings_pca[:, 1],
c=cluster_labels,
s=100,
alpha=0.7,
edgecolors="black",
linewidth=0.5
)
centers_pca = pca.transform(kmeans.cluster_centers_)
plt.scatter(
centers_pca[:, 0],
centers_pca[:, 1],
c="red",
marker="X",
s=500,
edgecolors="black",
linewidth=2,
label=fix_persian_text("مرکز خوشهها")
)
for cluster_id in range(optimal_k):
topic_text = cluster_topics.get(cluster_id, f"Cluster {cluster_id}")
if isinstance(topic_text, str) and "Topic:" in topic_text:
topic_name = topic_text.split("\n")[0].replace("Topic:", "").strip()
else:
topic_name = f"Cluster {cluster_id}"
label = f"C{cluster_id}: {topic_name[:30]}"
label = fix_persian_text(label)
plt.annotate(
label,
xy=(centers_pca[cluster_id, 0], centers_pca[cluster_id, 1]),
xytext=(10, 10),
textcoords="offset points",
fontsize=10,
fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", facecolor="yellow", alpha=0.7),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=0", lw=1.5)
)
plt.xlabel((xlabel), fontsize=12)
plt.ylabel((ylabel), fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
که خروجی به صورت زیر است :
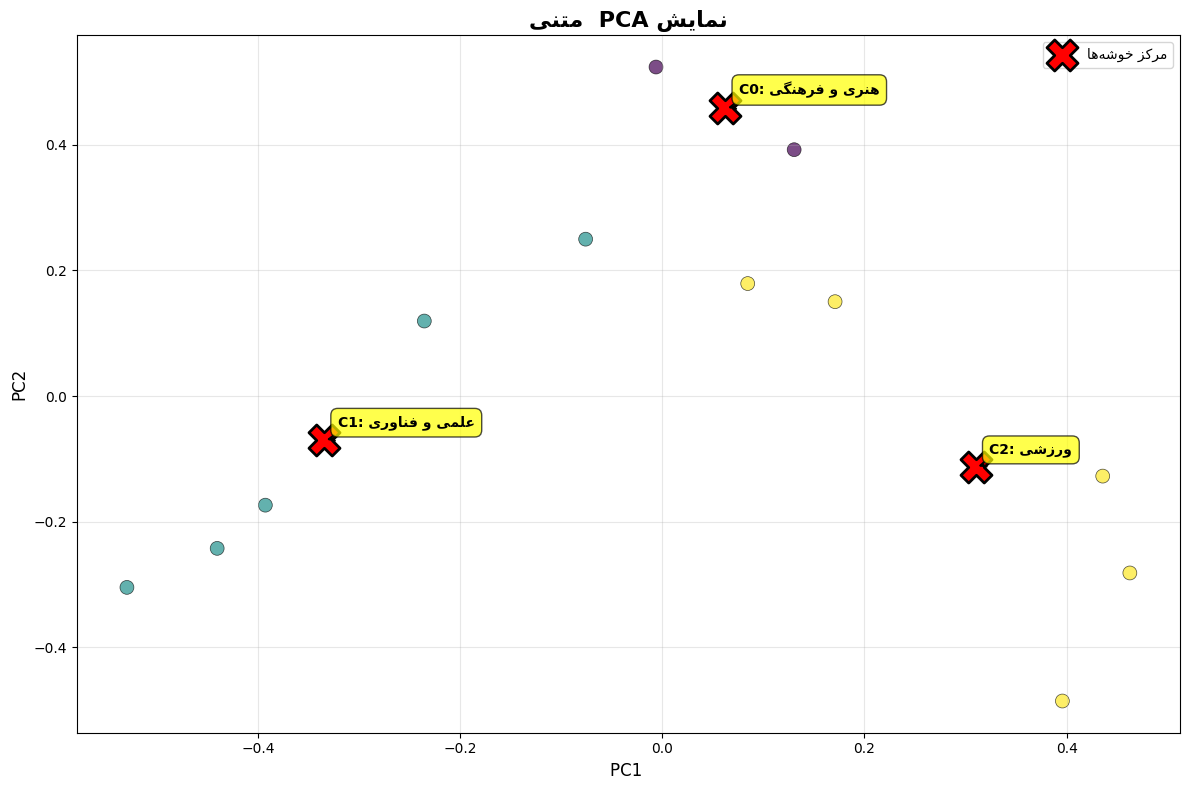
نمایش متن های مربوط به هر خوشه
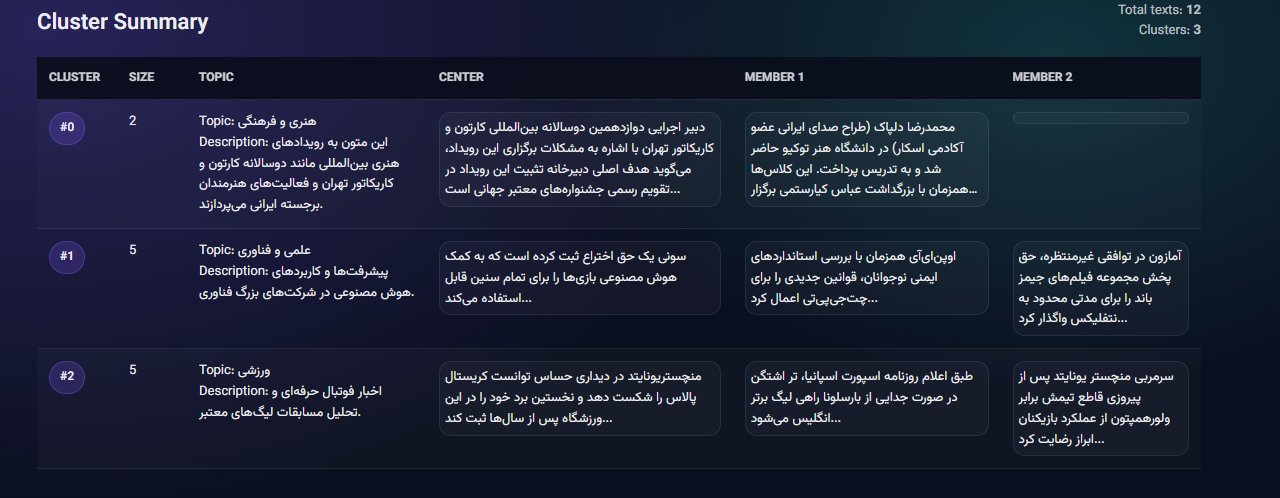
ذخیره سازی
در این قسمت پایگاه داده بردار ها را ذخیره می کنیم
import faiss
import pickle
import json
embeddings_for_faiss = embeddings_array.astype('float32')
embedding_dim = embeddings_for_faiss.shape[1]
print(f"Embedding dimension: {embedding_dim}")
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings_for_faiss)
faiss.write_index(index, 'embeddings.index')
فاز آنلاین
در فاز آنلاین، هر ورودی جدید ابتدا به بردار معنایی تبدیل شده و سپس با استفاده از جستجوی شباهت و رأیگیری K-NN، به یکی از دستههای موجود تخصیص داده میشود یا در صورت عدم شباهت کافی، بهعنوان یک موضوع جدید شناسایی و به سیستم افزوده میشود.
def classify_with_threshold(query_text, k_neighbors=3, distance_threshold=1.5):
#Generate embedding for query text
query_embedding = embeddings_model.embed_query(query_text)
query_embedding = np.array([query_embedding]).astype('float32')
# Search FAISS index
print(f" Searching FAISS index for {k_neighbors} nearest neighbors...")
distances, indices = index.search(query_embedding, k_neighbors)
# Check if distances exceed threshold
avg_distance = np.mean(distances[0])
min_distance = np.min(distances[0])
print(f" Distance metrics:")
print(f" Min distance: {min_distance:.4f}")
print(f" Avg distance: {avg_distance:.4f}")
print(f" Threshold: {distance_threshold:.4f}")
# Decide classification method
if min_distance > distance_threshold:
print(f" UNCERTAIN: Min distance ({min_distance:.4f}) exceeds threshold!")
print(f" Using LLM for classification...\n")
# Use LLM for classification
result = classify_with_llm(query_text, indices[0][:k_neighbors], distances[0][:k_neighbors])
result['classification_method'] = 'LLM'
result['reason'] = f'Min distance {min_distance:.4f} > threshold {distance_threshold:.4f}'
else:
print(f"\n CONFIDENT: Distance within threshold!")
print(f" Using FAISS k-NN voting...\n")
# Use FAISS k-NN voting
neighbor_clusters = [metadata[idx]['cluster_id'] for idx in indices[0]]
from collections import Counter
cluster_votes = Counter(neighbor_clusters)
predicted_cluster = cluster_votes.most_common(1)[0][0]
confidence = cluster_votes[predicted_cluster] / k_neighbors
result = {
'classification_method': 'FAISS',
'predicted_cluster': predicted_cluster,
'topic_name': cluster_info[str(predicted_cluster)]['topic_name'],
'description': cluster_info[str(predicted_cluster)]['description'],
'confidence': confidence,
'min_distance': float(min_distance),
'avg_distance': float(avg_distance),
'vote_distribution': dict(cluster_votes),
'nearest_neighbors': [],
'reason': f'Min distance {min_distance:.4f} <= threshold {distance_threshold:.4f}'
}
# Add neighbor details
for i, (idx, distance) in enumerate(zip(indices[0], distances[0])):
result['nearest_neighbors'].append({
'rank': i + 1,
'distance': float(distance),
'cluster_id': metadata[idx]['cluster_id'],
'topic_name': metadata[idx]['topic_name'],
'text_preview': metadata[idx]['original_text'][:150] + '...'
})
return result
منابع
- https://python.langchain.com/docs/get_started/introduction
- https://python.langchain.com/docs/modules/data_connection/document_transformers/
- https://github.com/langchain-ai/langchain
- https://github.com/facebookresearch/faiss
- https://faiss.ai/
- https://python.langchain.com/docs/integrations/vectorstores/faiss
- https://jina.ai/
- https://jina.ai/embeddings
- https://api.jina.ai/
- https://python.langchain.com/docs/integrations/text_embedding/jina
- https://python.langchain.com/docs/modules/data_connection/vectorstores/
- https://www.pinecone.io/learn/vector-database/
- https://python.langchain.com/docs/modules/data_connection/text_embedding/