
معماری ترنسفورمر ها از نگاه توابع ضرر
نویسنده: صابره عسکری
ایمیل : sabereaskari14@gmail.com
دانشگاه فردوسی مشهد دانشکده مهندسی گروه کامپیوتر
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
آزمایشگاه شناسایی الگو دکتر هادی صدوقی یزدی
مقدمه
معرفی ترنسفورمر
ترنسفورمرها (Transformers) نسل جدیدی از مدلهای یادگیری عمیق هستند که نخستین بار در سال ۲۰۱۷ با مقالهٔ معروف Attention Is All You Need معرفی شدند. این معماری با اتکا به سازوکار توجه (Attention) امکان میدهد مدل بتواند بهصورت همزمان به تمام بخشهای ورودی نگاه کند و وابستگیهای کوتاهمدت و بلندمدت را با دقت بالا استخراج کند. بر خلاف معماریهای پیشین مانند RNN و LSTM که ورودی را بهصورت ترتیبی پردازش میکردند، ترنسفورمرها محاسبات موازی انجام میدهند و همین موضوع آنها را برای استفاده روی دادههای حجیم و آموزش مدلهای بزرگ بسیار کارآمد میکند.
چرا ترنسفورمر انقلاب به پا کرد؟
معماری ترنسفورمر از چند جهت نقطهٔ عطفی در حوزهٔ پردازش زبان طبیعی و بینایی کامپیوتری محسوب میشود:
-
موازیسازی کامل پردازشها برخلاف RNNها، ترنسفورمر نیازی به پردازش ترتیبی ورودی ندارد، بنابراین سرعت آموزش بسیار بالاتر است.
-
درک عمیق روابط بین اجزای ورودی مکانیزم attention به مدل اجازه میدهد ارتباط بین هر دو بخش از جمله (حتی بسیار دور) را بررسی کند؛ چیزی که معماریهای قبلی در آن مشکل داشتند.
-
مقیاسپذیری زیاد این معماری پایهٔ مدلهای غولپیکری مثل BERT، GPT و ViT شده است. افزایش اندازه مدل تقریباً همیشه منجر به افزایش دقت میشود.
-
انعطافپذیری در حوزههای مختلف ترنسفورمرها فقط به NLP محدود نیستند؛ در بینایی (Vision Transformer)، صوت، زیستپزشکی، و حتی سیستمهای مولد متن و تصویر بهکار میروند.
به همین دلایل ترنسفورمرها پایه و اساس نسل جدید هوش مصنوعی مدرن محسوب میشوند.
1) نقش تابع ضرر در یادگیری مدلهای ترنسفورمری
تابع ضرر (Loss Function) یکی از حیاتیترین بخشهای فرآیند آموزش هر مدل یادگیری عمیق است و در ترنسفورمرها نقش بسیار تعیینکنندهای دارد. تابع ضرر مشخص میکند خروجی مدل چقدر با جواب درست فاصله دارد و به مدل سیگنالی میدهد که در چه جهتی و با چه شدتی باید وزنها را بهروزرسانی کند.
در ترنسفورمرها طراحی تابع ضرر اهمیت بیشتری دارد زیرا:
- خروجی مدل معمولاً احتمال توزیع کلمات، توکنها یا ویژگیهای پیچیده است؛ بنابراین Loss باید بتواند این توزیعها را مقایسه کند.
- رفتار attention بهشدت تحت تأثیر سیگنالهایی است که از Loss دریافت میکند.
- Loss مناسب باعث پایداری آموزش و جلوگیری از overfitting یا overconfidence میشود (مثلاً با Label Smoothing).
-
در مدلهای بزرگ زبانی (Language Models)، نوع Loss تعیین میکند مدل چه نوع وظیفهای را یاد بگیرد:
- Causal Loss برای GPT
- Masked LM Loss برای BERT
- Contrastive Loss برای مدلهایی مثل CLIP
در نتیجه، معماری ترنسفورمر بدون انتخاب صحیح تابع ضرر، نمیتواند به عملکرد مطلوب و رفتار پایدار دست پیدا کند.
2)معماری کلی ترنسفورمر
معماری ترنسفورمر یک ساختار ماژولار و کاملاً مبتنی بر سازوکار Self-Attention است. این معماری بهگونهای طراحی شده که بتواند وابستگیهای کوتاهمدت و بلندمدت را در دادهها بدون استفاده از ساختارهای ترتیبی (مثل RNN) مدلسازی کند. ترنسفورمر از دو بخش اصلی تشکیل شده است: Encoder و Decoder. هر دو بخش شامل چندین لایه مشابه هستند که بهصورت پشتهای روی هم قرار میگیرند.
خروجی ترنسفورمر
در نهایت خروجی دیکودر وارد یک لایهٔ خطی (Linear Projection) و سپس Softmax میشود تا توزیع احتمال برای پیشبینی توکن بعدی یا کلمهٔ هدف ایجاد گردد. در اینجا تابع ضرر (Loss Function) وارد عمل میشود و بر اساس این توزیع احتمال، مقدار خطا محاسبه شده و گرادیانها برای بهروزرسانی وزنها تولید میشوند.
3: تابعهای ضرر مورد استفاده در ترنسفورمرها
3–1 : Cross Entropy Loss (رایجترین تابع ضرر در ترنسفورمرها)
چرا استفاده میشود؟
ترنسفورمرها معمولاً در مسائل پیشبینی توکن (مثل ترجمه، خلاصهسازی، تولید متن) استفاده میشوند. خروجی مدل یک توزیع احتمال روی واژگان (Softmax) است، و Cross-Entropy بهترین معیار برای مقایسهٔ دو توزیع احتمال است:
-
توزیع خروجی مدل:
\[\hat{y} = \text{Softmax}(z)\] \[\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}\]
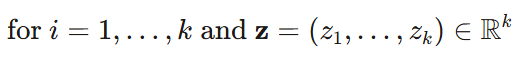
توضیح اجزای فرمول:
- ($z_i$): نمره (logit) مربوط به کلاس (i)
- ( K ): تعداد کل کلاسها
- ( e ): عدد نپر (حدود 2.718)
-
خروجی سافتمکس: عددی بین 0 و 1 برای هر کلاس، طوری که جمع همه خروجیها = 1
- توزیع هدف (Ground Truth): \(y\)
Cross Entropy اندازه میگیرد مدل چقدر از پاسخ درست فاصله دارد.
فرمول Cross Entropy Loss
برای یک نمونه و یک توزیع روی کلاسها:
\[Loss = - \sum_{i=1}^{C} y_i \cdot \log(\hat{p}_i)\]- $C$ : تعداد کلاسها
- $y_i$: برچسب واقعی (بردار one-hot)
- $\hat{p}_i$: احتمال پیشبینیشده برای کلاس $i$
نحوهٔ کار در ترنسفورمر
- دیکودر برای هر موقعیت یک توزیع احتمال میدهد.
- تابع Softmax روی واژگان اعمال میشود.
- Cross Entropy Loss با خروجی صحیح مقایسه میشود.
- گرادیانها از خروجی به سمت attention و لایههای اولیه جریان پیدا میکنند.
نکتهٔ مهم
Cross Entropy بهتنهایی باعث میشود مدل بیشازحد مطمئن شود (overconfidence). برای همین در بسیاری از ترنسفورمرها (مثل مدلهای ترجمه) همراه با Label Smoothing استفاده میشود.
3–2 : Label Smoothing
Label Smoothing یکی از تکنیکهای بسیار کاربردی در آموزش ترنسفورمرهاست که برای جلوگیری از بیشاعتماد شدن مدل (Overconfidence) و بهبود تعمیم استفاده میشود.
چرا به Label Smoothing نیاز داریم؟
در بیشتر مسائل NLP:
- هدف واقعی یک توکن به صورت one-hot است یعنی احتمال درست برای توکن هدف = 1 و برای بقیه = 0
اما مدل وقتی برای مدت طولانی با توزیع one-hot آموزش میبیند:
- تمایل دارد به خروجیهای خود اعتماد بیش از حد پیدا کند.
- گرادیانها در مراحل پایانی بسیار کوچک میشوند.
- مدل نمیتواند عدم قطعیت را درست یاد بگیرد.
- گاهی باعث آموزش ناپایدار میشود.
برای همین در تربیت ترنسفورمرها از روش “نرم کردن برچسبها” استفاده میشود.
Label Smoothing چیست؟
در این روش مقدار احتمال از حالت one-hot خارج میشود و کمی پخش میگردد.
به جای اینکه:
\[y_{target}=1 \quad\text{و}\quad y_{others}=0\]میگوییم:
\[y_{target}=1 - \epsilon\] \[y_{others}=\frac{\epsilon}{K - 1}\]- $(K)$: تعداد کلاسها (اندازه واژگان)
- $(\epsilon)$: مقدار smoothing. معمولاً 0.1 یا 0.05
این یعنی به مدل میگوییم:
به جای قطعیت ۱۰۰٪، فرض کن یک مقدار کوچک احتمال هم برای کلاسهای دیگر وجود دارد.
فرمول کلی Label Smoothing Loss
ابتدا توزیع هدف جدید را تعریف میکنیم:
\[y_i^{LS} = \begin{cases} 1 - \epsilon & \text{اگر } i = \text{کلاس صحیح} ,,, \dfrac{\epsilon}{K - 1} & \text{در غیر این صورت} \end{cases}\]سپس Cross Entropy روی این برچسب جدید اعمال میشود:
\[\mathcal{L}_{LS} = - \sum_{i=1}^{K} y_i^{LS} \log(\hat{y}_i)\]یعنی همان Cross Entropy است، فقط $(y)$ عوض شده است.
تأثیر Label Smoothing روی ترنسفورمرها
- باعث آموزش پایدارتر میشود
- توجه $(Attention)$ با نویز کمتر و توزیع متعادلتر یاد گرفته میشود
- مدل از اعتماد بیش از حد خودداری میکند
- کاهش overfitting
- افزایش BLEU score در ترجمه (ثابت شده در مقالهٔ اصلی Transformer)
در معماریهای بزرگتر (T5، Transformer-XL، BERT اولیه) یک تنظیم بسیار کلیدی است.
3–3 : Causal Language Modeling Loss (CLM Loss)
این تابع ضرر، پایهٔ آموزش تمام مدلهای GPT (GPT-1 تا GPT-4 و تمام LLMها) است. در CLM، مدل یاد میگیرد توکن بعدی را فقط بر اساس توکنهای قبلی پیشبینی کند.
ایدهٔ اصلی
در مدلهای مولد متن، ترتیب بسیار مهم است. مدل نباید آینده را “ببیند”. برای همین ترنسفورمرهای مولد از Masked Self-Attention استفاده میکنند، و تابع ضرر هم مطابق این معماری طراحی میشود.
در هر موقعیت $(t)$:
\[\hat{y}_t = P(x_t \mid x_1, x_2, \ldots, x_{t-1})\]هدف این است که مدل احتمال توکن درست را در هر مرحله بیشینه کند.
فرمول کلی Causal LM Loss
به ازای یک دنباله با طول $(T)$:
\[\mathcal{L}_{CLM} = - \sum_{t=1}^{T} \log P(x_t \mid x_{<t})\]به بیان ساده:
- مدل توکن $t$ را فقط با توجه به توکنهای قبلش پیشبینی میکند.
- Cross Entropy روی تکتک مراحل محاسبه میشود.
اگر بخواهیم آن را با خروجی Softmax بنویسیم:
\[\mathcal{L}_{CLM} = - \sum_{t=1}^{T} \log(\hat{y}_{t, x_t})\]در اینجا:
$(\hat{y}_{t,x_t}) =$ احتمال توکن صحیح در مرحله $t$ که Softmax پیشبینی کرده.
چرا به آن میگویند “Causal”؟
به دلیل علیت زمانی:
- گذشته → حال
- گذشته → آینده
- اما آینده → گذشته ❌
- آینده → حال ❌
این همان چیزی است که باعث میشود GPT بتواند متن را تولید کند، نه فقط تحلیل.
ویژگیهای مهم این Loss
- برای مدلهای مولد مناسب است (Autoregressive)
- خطا موقعیت به موقعیت محاسبه میشود
- ذاتاً با Masked Self-Attention سازگار است
- باعث میشود مدل ساختار جمله، گرامر، انسجام و سبک نوشتار را یاد بگیرد
- مهمترین پایهٔ آموزش مدلهای LLM امروزی است
نکتهٔ مهم در کاربرد
در GPT، ورودی و خروجی در واقع یکساناند:
ورودی: A B C D
خروجی: B C D <EOS>
مدل یاد میگیرد توکن بعدی دنباله را حدس بزند.
3–4 : Masked Language Modeling Loss (MLM Loss)
این تابع ضرر پایهٔ آموزش مدلهایی مثل BERT، RoBERTa، ALBERT و ELECTRA است. هدف MLM این است که مدل بتواند معنی یک جمله را بفهمد، حتی اگر برخی کلمات حذف یا مخفی شده باشند.
ایدهٔ اصلی
در BERT، برخلاف GPT، مدل متن را تولید نمیکند. بلکه یک بخش از ورودی را ماسک میکنیم تا مدل مجبور شود آن را بر اساس اطلاعات قبل و بعد حدس بزند.
مثال:
ورودی:
The cat [MASK] on the mat
هدف: پیشبینی کلمهٔ “sat”
نحوهٔ ماسک کردن
در مقالهٔ اصلی BERT، ۱۵٪ توکنها برای پیشبینی انتخاب میشوند:
از بین این ۱۵٪:
- 80% → با
[MASK]جایگزین میشوند - 10% → با یک توکن تصادفی جایگزین میشوند
- 10% → تغییر نمیکنند
هدف از این ترکیب: مدل باید بتواند بدون اتکا به خود [MASK] یاد بگیرد.
فرمول کلی MLM Loss
اگر در جمله T توکن باشد و M توکن ماسک شده باشند، تابع ضرر فقط روی توکنهای ماسکشده محاسبه میشود:
\[\mathcal{L}_{MLM} = - \frac{1}{M} \sum{t \in \text{masked positions}} \log(\hat{y}_{t, x_t})\]به بیان ساده:
- فقط توکنهای ماسکشده اهمیت دارند
- خروجی مدل Softmax است
- Loss همان Cross Entropy روی این موقعیتهاست
فرمول کاملتر:
\[\mathcal{L}_{MLM} = - \sum_{t=1}^{T} m_t \log P(x_t \mid x_{1:T}^{\setminus t})\]که:
- $(m_t = 1)$ → اگر توکن t ماسک شده باشد
- $(m_t = 0)$ → در غیر این صورت
- $(x_{1:T}^{\setminus t})$ → جملهٔ کامل بهجز توکن هدف
چرا MLM برای BERT ضروری است؟
زیرا BERT یک مدل Bidirectional است: به جای نگاه به گذشته فقط (مثل GPT) یا آینده فقط، به تمام جمله بهصورت همزمان نگاه میکند.
MLM باعث میشود:
- مدل روابط معنایی عمیق را در سطح جمله یاد بگیرد
- بهترین ویژگیها برای استخراج معنا، قصد، و روابط کلمات ایجاد شود
- دقت مدل در وظایف درک زبان (NLP Understanding) بسیار بالا برود
تفاوت مهم بین MLM و CLM
| ویژگی | MLM (BERT) | CLM (GPT) |
|---|---|---|
| نوع مدل | Encoder-only | Decoder-only |
| هدف | درک زبان | تولید زبان |
| دادهٔ ورودی | ماسک شده | کامل |
| نگاه مدل | دوطرفه (Bidirectional) | یکطرفه (Causal) |
| کاربرد | طبقهبندی، NER، QA | خلاصهسازی، چت، متنسازی |
3–5 : Contrastive Loss (تابع ضرر متضاد / کنتراستی)
Contrastive Loss در ترنسفورمرهای مدرن برای یادگیری نمایشهای معنایی مشترک بین دو modality (مثل تصویر و متن) یا برای یادگیری نمایشهای قوی بدون برچسب استفاده میشود.
مهمترین کاربرد:
- CLIP (OpenAI): هماهنگسازی فضای معنایی متن و تصویر
- مدلهای Self-Supervised روی Vision Transformers
ایدهٔ اصلی
Contrastive Loss مدل را مجبور میکند:
- نمونههای مرتبط → نزدیک شوند
- نمونههای نامرتبط → دور شوند
مثلاً در CLIP:
- یک تصویر و متن مربوط به آن → جفت مثبت
- تصویر و متن غیرمرتبط → جفت منفی
هدف این است که نمایشهای برداری (Embedding) در فضای مشترک معنایی قرار گیرند.
فرمول کلی (InfoNCE Loss)
معمولترین فرم Contrastive Loss، تابع InfoNCE است.
فرض کنیم:
- $( v_i )$: بردار ویژگی تصویر $i$
- $( t_i )$: بردار ویژگی متن $i$
- $( N )$: تعداد نمونهها در $batch$
- شباهت با تابع $(\text{sim}(u,v))$ (مثلاً ضرب نقطهای)
Loss برای متن→تصویر:
\[\mathcal{L}_{t \rightarrow v} = - \sum_{i=1}^{N} \log\frac{ \exp(\text{sim}(t_i, v_i) / \tau) }{ \sum_{j=1}^{N} \exp(\text{sim}(t_i, v_j) / \tau) }\]Loss برای تصویر→متن:
\[\mathcal{L}_{v \rightarrow t} = - \sum_{i=1}^{N} \log\frac{ \exp(\text{sim}(v_i, t_i) / \tau) }{ \sum_{j=1}^{N} \exp(\text{sim}(v_i, t_j) / \tau) }\]در نهایت $Loss$ کلی:
\[\mathcal{L} = \frac{1}{2} (\mathcal{L}_{t \rightarrow v} + \mathcal{L}_{v \rightarrow t})\]$(\tau)$ یک دمای (Temperature) قابل یادگیری یا ثابت است که پراکندگی احتمالات را کنترل میکند.
چرا Contrastive Loss در ترنسفورمرها مهم شد؟
به چند دلیل کلیدی:
۱) ایجاد فضای معنایی مشترک
در CLIP، متن و تصویر به همان “معنی” نگاشته میشوند. این باعث میشود مدل بتواند فقط با زبان عکسها را تشخیص دهد!
۲) مناسب برای دادهٔ عظیم ولی بدون برچسب
در self-supervised ViT، مدل بدون نیاز به labels یاد میگیرد چه چیزهایی شبیه هماند.
۳) مقیاسپذیری فوقالعاده
این روش با batchهای بزرگ بهتر کار میکند و برای مدلهای عظیم ایدهآل است.
نتیجه
Contrastive Loss یک نوع نگاه جدید به یادگیری معنایی است که در معماریهای ترنسفورمری باعث جهشهای بزرگی در حوزههای:
- بینایی کامپیوتری
- چندرسانهای
- سرچ معنایی
- مدلهای مشترک تصویر–متن
- self-supervised learning
شده است.
3–6 : Reinforcement Learning Loss (RL Loss / RLHF)
RLHF (Reinforcement Learning from Human Feedback) روشی است که در آن مدل ترنسفورمری علاوهبر یادگیری زبان، وابسته به ترجیحات انسانی نیز تنظیم میشود.
این روش در مدلهایی مثل ChatGPT، GPT-4، Claude و … استفاده شده است.
ایدهٔ اصلی
آموزش بزرگترین LLMها سه مرحله دارد:
۱) Pretraining
با Causal LM Loss (CLM): مدل زبان یاد میگیرد، اما رفتار انسانی ندارد.
۲) Supervised Fine-Tuning (SFT)
مدل روی دادههای پاسخنویسی انسانی آموزش میبیند. این مرحله از Cross Entropy ساده استفاده میکند.
۳) Reinforcement Learning from Human Feedback (RLHF)
اینجاست که RL Loss وارد میشود.
در این مرحله:
- چند پاسخ از مدل تولید میشود
- انسانها آنها را رتبهبندی میکنند
- یک مدل Reward Model ساخته میشود
- ترنسفورمر با استفاده از الگوریتم تقویتی PPO بهبود داده میشود (Proximal Policy Optimization)
دو نوع تابع ضرر در RLHF مهم است:
1) Reward Model Loss (برای آموزش مدل پاداش)
وقتی انسانها چند خروجی را رتبهبندی میکنند:
اگر پاسخ $A$ از$B$ بهتر باشد:
\[r_\theta(A) > r_\theta(B)\]Reward Model یک شبکه ترنسفورمری کوچک است که یاد میگیرد کدام خروجی بهتر است.
Loss آن از نوع Pairwise Ranking Loss است:
\[\mathcal{L}_{RM} = - \log\left( \frac{ \exp(r_\theta(A)) }{ \exp(r_\theta(A)) + \exp(r_\theta(B)) } \right)\]این Loss به مدل میگوید: «امتیاز پاسخ برتر را بیشتر کن.»
2) PPO Loss (برای فاینتیونینگ LLM)
در مرحلهٔ PPO، مدل ترنسفورمری بهعنوان policy رفتار میکند. تابع ضرر PPO شامل سه بخش است:
(1) Clipped Policy Loss
\[\mathcal{L}_{policy} = - \mathbb{E} \left[ \min\left( r_t A_t, \text{clip}(r_t, 1-\epsilon, 1+\epsilon) A_t \right) \right]\]که:
\[r_t = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)}\]- $(A_t)$: advantage
- $(\epsilon)$: معمولاً 0.1 یا 0.2
- $(\pi_\theta)$: مدل فعلی
- $(\pi_{\theta_{\text{old}}})$: مدل قبلی
این بخش مانع از تغییرات شدید در مدل میشود.
(2) Value Function Loss
\[\mathcal{L}_{value} = (V_\theta(s_t) - V_t^{target})^2\]برای یادگیری اینکه «پاسخ چقدر خوب بود؟»
(3) Entropy Bonus
\[\mathcal{L}_{entropy} = -\beta H(\pi_\theta)\]برای جلوگیری از تکجوابی شدن مدل و افزایش تنوع.
Loss نهایی PPO
\[\mathcal{L}_{PPO} = \mathcal{L}_{policy} + c_1 \mathcal{L}_{value} + c_2 \mathcal{L}_{entropy}\]این مجموعه Lossها باعث میشود مدل:
- پاسخ محترمانهتر بدهد
- رفتار مخرب نداشته باشد
- از نظر انسان قابلفهمتر باشد
- کمتر خطاهای خطرناک تولید کند
بدون این مرحله، ChatGPT هرگز «چتبات قابل استفاده» نمیشد.
اهمیت RL Loss در معماری ترنسفورمر
- مدلهای مبتنی بر Decoder (مثل GPT) با RLHF میتوانند با ارزشهای انسانی هماهنگ شوند
- باعث ایجاد ایمنی (Safety) و قابلیت اعتماد در خروجیها میشود
- کیفیت مکالمه و دنبال کردن دستورها افزایش مییابد
- سمی بودن (toxicity) کاهش مییابد
تحلیل اثر تابع ضرر بر معماری ترنسفورمر
تابع ضرر (Loss Function) نقشی بنیادی در شکلگیری رفتار ترنسفورمرها دارد. هرچند معماری ترنسفورمر از ماژولهایی مانند Attention، Feed-Forward و Normalization تشکیل شده، اما در نهایت این Loss است که تعیین میکند شبکه چه چیزی را یاد بگیرد، چگونه وزنها تغییر کنند، و کدام الگوها مهم در نظر گرفته شوند. در این بخش اثر هر گروه از Lossها را روی یادگیری و پایداری معماری تحلیل میکنیم.
1) نقش Loss در پایداری Attention
مشکل مدلهای اولیه بدون Label Smoothing
وقتی مدل با CrossEntropy معمولی و برچسبهای one-hot آموزش داده شود:
- مدل تمایل پیدا میکند احتمال کلاس صحیح را به ۱ برساند
- بهسرعت بیشاعتماد (overconfident) میشود
- مقادیر softmax بسیار شیبدار میشوند
- small gradients → کند شدن یادگیری در لایههای پایینتر
این مسئله در معماریهایی که وابسته به attention هستند شدیدتر میشود، چون:
- attention مقادیر Q/K/V را از softmax عبور میدهد
- softmax شدید → توجه فقط روی یک یا چند توکن → کاهش تنوع یادگیری
- مدل به الگوهای ساده میچسبد
با Label Smoothing:
- احتمال خروجی پخش میشود
- مدل سیگنال گرادیانی غنیتری دریافت میکند
- attention چندین مسیر وابستگی را بررسی میکند
- یادگیری پایدارتر و معنیمحورتر میشود
2) اثر CLM Loss بر ساختار Decoderهای GPT
Causal LM Loss بهطور مستقیم معماری Decoder را شکل میدهد:
توجه یکطرفه (causal mask) نتیجهٔ مستقیم نوع Loss است
از آنجا که CLM فقط به گذشته نگاه میکند:
- معماری مجبور میشود از Masked Self-Attention استفاده کند
- یعنی مدل نمیتواند توکنهای آینده را مشاهده کند
- این ویژگی باعث شکلگیری رفتار autoregressive میشود
این Loss سبب یادگیری انسجام زمانی در متن میشود
مدل یاد میگیرد:
\[P(x_t|x_1,...,x_{t-1})\]در نتیجه:
- روابط بلندمدت زبان
- گرامر و نحو
- ساختار جمله
- سبک نوشتار
- انسجام مکالمه
همگی از دل همین تابع ضرر استخراج میشوند.
3) اثر MLM Loss بر خصوصیات Encoderهای BERT
MLM باعث میشود BERT:
یک مدل کاملاً Bidirectional شود
چون برای پیشبینی توکن ماسکشده، باید:
- از قبل آن
- و بعد آن
اطلاعات بگیرد.
این Loss عملاً معماری Encoder را به سمت درک عمیق معنا سوق میدهد.
توجه روی تمام قسمتهای جمله توزیع میشود
چون مدل باید بداند:
- چه لغتی قبل از واژه ماسکشده است
- چه لغتی بعد از آن است
- رابطه نحوی چیست
- رابطه معنایی چیست
نتیجه:
- توجههای پایدار
- درک روابط پیچیده
- بهترین عملکرد در Understanding (QA, NER, classification)
4) اثر Contrastive Loss بر Vision Transformer و مدلهای چندوجهی
Contrastive Loss جهتگیری متفاوتی ایجاد میکند:
مدل بهجای پیشبینی کلاس، یاد میگیرد فاصلهٔ معنایی را اندازه بگیرد
این یعنی:
- Embeddingها باید ساختار هندسی خاصی داشته باشند
- نمونههای مرتبط → نزدیک
- نامرتبط → دور
روی معماری اثر میگذارد چون:
- attention مجبور است ویژگیهای سطح بالا را استخراج کند
- مدل باید نمایشی بسازد که در فضای مشترک معنایی قابل مقایسه باشد
- به جای یادگیری کلاسبندی، یادگیری embedding space انجام میشود
این تفاوت باعث شده CLIP بتواند فقط با متن، تصاویر را “درک” کند.
5) اثر RLHF و PPO Loss بر رفتار مکالمه و ایمنی مدل
PPO Loss معماری را مجبور میکند:
- پاسخهای محترمانهتر بدهد
- از خطاهای خطرناک دوری کند
- سازگار با ترجیحات انسانی شود
اثر روی ساختار attention
attention پس از RLHF یاد میگیرد:
- از تولید پاسخهای غیراخلاقی یا مضر فاصله بگیرد
- در مسیرهایی که انسان امتیاز مثبت داده تقویت شود
- الگوهای تنبیهی انسانمحور را در نظر بگیرد
چرا معماری بدون RLHF کافی نیست؟
LLM بدون RLHF:
- ممکن است جواب نادرست ولی روان بدهد
- گاهی بیادب یا بیقاعده عمل کند
- ممکن است به سمت الگوهای مضر منحرف شود
- خروجی غیرقابلکنترل دارد
بنابراین RLHF Loss، رفتار انسانی مدل را شکل میدهد، نه فقط توانایی زبانی مدل را.
منابع
معماری ترنسفورمر و Attention
-
Vaswani et al., Attention Is All You Need, NeurIPS 2017 https://arxiv.org/abs/1706.03762
-
Lilian Weng, Attention? Attention! (توضیح شهودی Attention و Transformer) https://lilianweng.github.io/posts/2018-06-24-attention/
Cross Entropy و Label Smoothing
-
Szegedy et al., Rethinking the Inception Architecture for Computer Vision, CVPR 2016 (معرفی Label Smoothing) https://arxiv.org/abs/1512.00567
-
PyTorch Docs — CrossEntropyLoss https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
Causal Language Modeling (GPT)
-
Radford et al., Improving Language Understanding by Generative Pre-Training, OpenAI 2018 PDF Link
-
Radford et al., Language Models are Unsupervised Multitask Learners, OpenAI 2019 https://arxiv.org/abs/1901.02860
Masked Language Modeling (BERT)
-
Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019 https://arxiv.org/abs/1810.04805
-
Hugging Face Blog — How BERT works https://huggingface.co/blog/bert-101
Contrastive Loss و CLIP
-
Radford et al., Learning Transferable Visual Models From Natural Language Supervision (CLIP), ICML 2021 https://arxiv.org/abs/2103.00020
-
Oord et al., Representation Learning with Contrastive Predictive Coding, 2018 (پایه InfoNCE Loss) https://arxiv.org/abs/1807.03748