
خوشهبندی متن با ابزار FAISS
نویسنده: محمدرضا باباگلی
ايميل: MohammadRezaBabagoli.AI@gmail.com
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
آزمایشگاه شناسایی الگو دکتر هادی صدوقی یزدی
خوشهبندی متن
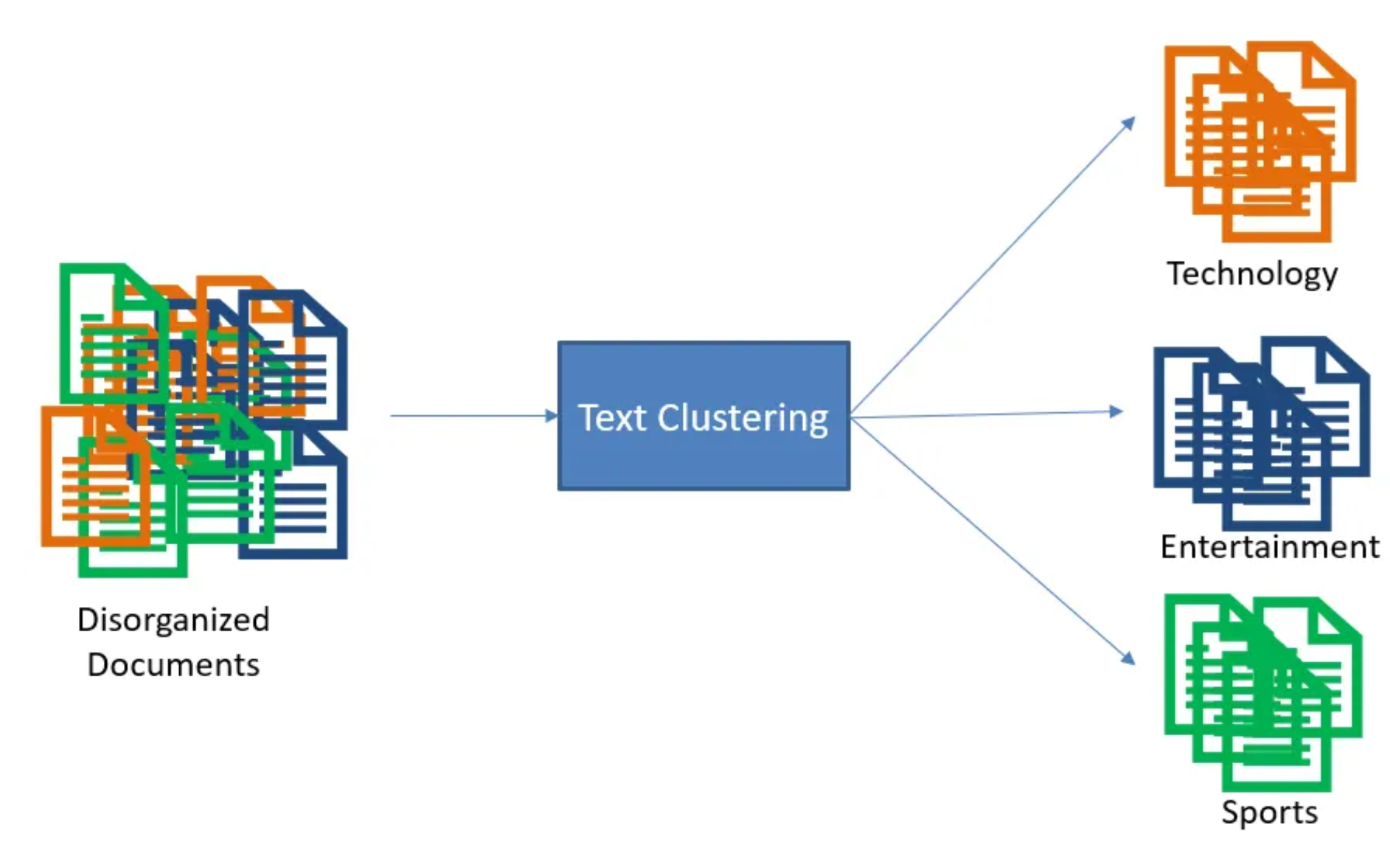
مقدمه
در عصر دیجیتال، حجم عظیمی از دادهها به صورت متن تولید و ذخیره میشود. از پستهای شبکههای اجتماعی و ایمیلهای کاری گرفته تا اسناد علمی و تیکتهای پشتیبانی مشتریان، همه اینها نمونههایی از دادههای متنی غیرساختاریافته هستند که تحلیل آنها برای به دست آوردن بینش، ارزش استراتژیک دارد. یکی از اساسیترین تکنیکها برای سازماندهی و درک این دریا از اطلاعات، خوشهبندی متن (Text Clustering) است.
خوشهبندی متن: تعریف و انواع
خوشهبندی یک وظیفه کلیدی در حوزه یادگیری بدون نظارت (Unsupervised Learning) است که هدف آن، گروهبندی اشیاء (در اينجا، مستندات متنی) به دستههایی به نام “خوشه” است. اعضای یک خوشه باید از نظر ویژگیهای معنایی یا محتوایی به یکدیگر شباهت زیادی داشته باشند، در حالی که با اعضای خوشههای دیگر تفاوت قابل توجهی نشان دهند. برخلاف طبقهبندی (Classification)، در خوشهبندی برچسبهای از پیش تعریفشدهای وجود ندارد و الگوریتم به صورت خودکار ساختار دادهها را کشف میکند.
انواع مختلفی از الگوریتمهای خوشهبندی وجود دارد که هر کدام برای سناریوهای خاصی مناسب هستند:
- خوشهبندی تقسیمی (Partitioning Clustering): مانند الگوریتم K-means که دادهها را به k خوشه تقسیم میکند و سعی میکند واریانس درونخوشهای را به حداقل برساند.

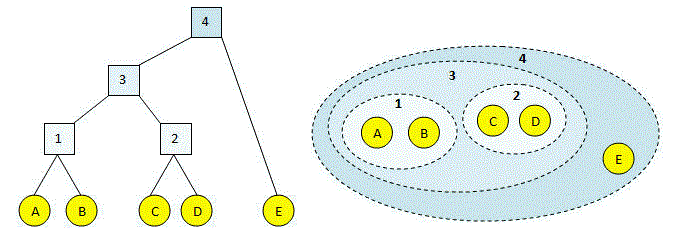
- خوشهبندی سلسلهمراتبی (Hierarchical Clustering): یک ساختار درختی از خوشهها ایجاد میکند که میتواند تجزیهشونده (Divisive) یا تجمعی (Agglomerative) باشد.
- خوشهبندی مبتنی بر چگالی (Density-Based Clustering): مانند الگوریتم DBSCAN که خوشهها را به عنوان مناطق پرتراکم از دادهها تعریف میکند و قادر به شناسایی دادههای نویز (Outlier) است.
- خوشهبندی طیفی (Spectral Clustering): از تئوری گراف برای خوشهبندی استفاده میکند و برای دادههایی با ساختار پیچیده و غیرمحدب کارآمد است.
چالشهای کلیدی در خوشهبندی متن
با وجود سادگی مفهومی، خوشهبندی متن با چالشهای منحصر به فردی روبرو است که آن را از خوشهبندی دادههای عددی متمایز میکند:
-
مشکل ابعاد بالا (High Dimensionality): هنگامی که متنها با استفاده از روشهایی مانند TF-IDF یا حتی بردارهای امروزی (Embeddings) به نمایش عددی تبدیل میشوند، ابعاد آنها به هزاران ویژگی میرسد. این “ نفرین ابعاد” (Curse of Dimensionality) میتواند عملکرد بسیاری از الگوریتمهای خوشهبندی را مختل کند، زیرا در فضاهای با ابعاد بسیار بالا، مفهوم فاصله و شباهت کممعناتر میشود.
-
چالش متنهای کوتاه (Short Text Challenge): متنهای کوتاه مانند توییتها، نظرات کاربران یا عناوین اخبار، اطلاعات کمی در خود دارند. این کمبود زمینه (Context) باعث میشود روشهای سنتی که بر اساس تکرار کلمات کار میکنند، نتوانند شباهت معنایی را به درستی تشخیص دهند. برای مثال، عبارتهای «کوهنوردی برویم»، «یک پیادهروی در جنگل» و «قدم زدن» همگی به یک مفهوم اشاره دارند، اما واژگان مشترک کمی دارند.
-
مسئله چندزبانه بودن (Multilingualism Issue): در دنیای جهانی امروز، دادهها اغلب به چندین زبان تولید میشوند. یک سیستم خوشهبندی کارآمد باید بتواند مستنداتی را که به زبانهای مختلف اما با موضوع مشابه نوشته شدهاند، در یک گروه قرار دهد. این امر نیازمند نمایشهایی از متن است که فراتر از مرزهای زبانی عمل کنند.
اهمیت و کاربردهای مهم خوشهبندی متن
غلبه بر این چالشها اهمیت حیاتی دارد، زیرا خوشهبندی متن ستون فقرات بسیاری از کاربردهای مدرن تحلیل داده است. این تکنیک به سازمانها کمک میکند تا از دادههای غیرساختاریافته خود ارزش استخراج کنند:
- تحلیل اسناد و محتوای بزرگ: سازمانها میتوانند هزاران سند داخلی، مقاله علمی یا خبر را به صورت خودکار دستهبندی کنند تا به سرعت موضوعات اصلی را شناسایی کرده و به اطلاعات مورد نظر خود دسترسی پیدا کنند.
- شبکههای اجتماعی و نظرسنجی: با خوشهبندی پستها یا نظرات کاربران، میتوان روندهای داغ (Trending Topics)، احساسات عمومی و گروههای مختلف کاربران را درک کرد. برای مثال، در یک پلتفرم آموزشی، میتوان پیشنهادهای مشابه شرکتکنندگان را به صورت خودکار گروهبندی کرد تا تحلیل آنها برای میزبان سادهتر شود.
- پشتیبانی مشتریان و خودکارسازی: تیکتهای پشتیبانی یا درخواستهای مشتریان را میتوان بر اساس مسئله اصلی خوشهبندی کرد. این کار به خودکارسازی فرآیند ارسال تیکت به بخش مربوطه، شناسایی مشکلات متداول و بهبود پاسخدهی کمک شایانی میکند.
- بهبود موتورهای جستجو: خوشهبندی اسناد به موتورهای جستجو کمک میکند تا نتایج متنوعتری ارائه دهند و درک بهتری از قصد کاربر (User Intent) داشته باشند.
با توجه به این اهمیت، نیاز به ابزارهایی قدرتمند و کارآمد احساس میشود. کتابخانههایی مانند FAISS (Facebook AI Similarity Search) که برای جستجوی سریع شباهت در مجموعه دادههای عظیم برداری طراحی شدهاند، در ترکیب با مدلهای مدرن تولید بردار از متن (Embedding Models)، راهحلهای مؤثری برای مقابله با چالشهای خوشهبندی متن ارائه میدهند. این مقاله به بررسی جامع این رویکردها و نحوه پیادهسازی آنها میپردازد.
نمایش متن (Text Representation)
اولین و بنیادیترین گام در هر فرآیند پردازش زبان طبیعی (NLP)، بهویژه خوشهبندی، تبدیل متن به فرمتی قابل فهم برای ماشینها است. کامپیوترها کلمات و جملات را درک نمیکنند، بلکه با اعداد و بردارها کار میکنند. فرآیند این تبدیل را “نمایش متن” یا “Text Representation” مینامند. کیفیت این نمایش مستقیماً بر عملکرد الگوریتمهای خوشهبندی تأثیر میگذارد، زیرا اگر شباهت معنایی دو متن در نمایش عددی آنها منعکس نشود، هیچ الگوریتمی قادر به گروهبندی صحیح آنها نخواهد بود. در طول زمان، روشهای مختلفی برای این منظور توسعه یافتهاند که میتوان آنها را به دو دسته سنتی و مدرن تقسیم کرد.
روشهای سنتی: TF-IDF و Bag-of-Words
روشهای سنتی بر اساس تکرار و توزیع کلمات در یک سند و در کل مجموعه اسناد (Corpus) عمل میکنند. این روشها ساده، سریع و قابل تفسیر هستند، اما با محدودیتهای جدی روبرو هستند.
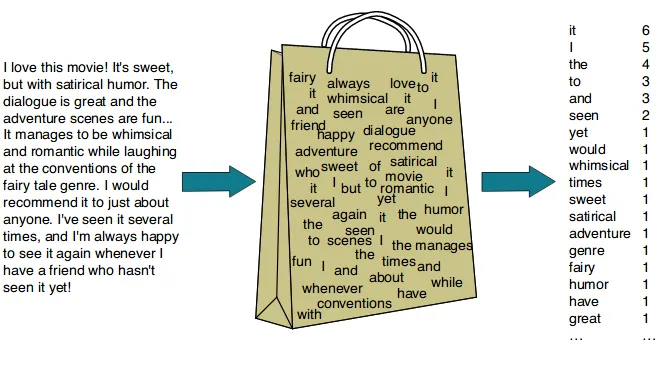
- Bag-of-Words (BoW):
در این مدل، هر سند به عنوان یک “کیسه کلمات” در نظر گرفته میشود که ترتیب و ساختار گرامری در آن نادیده گرفته میشود. فرآیند کار به این صورت است:
- یک واژگان (Vocabulary) از تمام کلمات منحصر به فرد در کل مجموعه داده ساخته میشود.
- هر سند به یک بردار عددی تبدیل میشود که طول آن برابر با اندازه واژگان است. هر عنصر در این بردار، تعداد تکرار (فرکانس) کلمه متناظر در آن سند را نشان میدهد.
محدودیت اصلی: این روش هیچ درکی از معنای کلمات ندارد. برای مثال، کلمات “خودرو” و “اتومبیل” از نظر این مدل کاملاً متفاوت هستند، در حالی که مترادف هستند. همچنین، ترتیب کلمات نادیده گرفته میشود، بنابراین جملات “سگ گربه را تعقیب کرد” و “گربه سگ را تعقیب کرد” دارای نمایش یکسانی خواهند بود.
</div>
- TF-IDF (Term Frequency-Inverse Document Frequency):
این روش یک بهبود هوشمندانه نسبت به BoW است و تلاش میکند تا اهمیت واقعی یک کلمه در یک سند را بسنجد. TF-IDF از دو جزء تشکیل شده است:
- TF (Term Frequency): فرکانس یک کلمه در یک سند (مانند BoW).
- IDF (Inverse Document Frequency): معیاری از نادر بودن یک کلمه در کل مجموعه اسناد. کلماتی که در بسیاری از اسناد تکرار میشوند (مانند حروف اضافه یا “و”، “در”)، وزن کمی دریافت میکنند، در حالی که کلمات نادرتر و معنادارتر، وزن بالاتری میگیرند.
محدودیت اصلی: با وجود اینکه TF-IDF کلمات کلیدی مهمتر را برجسته میکند، اما همچنان با مشکل فهم معنای عمیق و هممعنایی کلمات دستوپنجه نرم میکند. این روش همچنان بردارهای بسیار بزرگ و پراکنده (Sparse) تولید میکند که میتواند منجر به “نفرین ابعاد” شود.
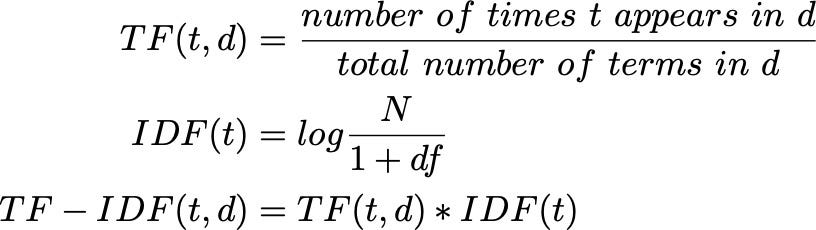
روشهای مدرن: Embedding با استفاده از مدلهای زبانی
انقلاب مدلهای زبانی، بهویژه معماری ترنسفورمر، نحوه نمایش متن را به کلی دگرگون کرد. این روشها به جای تمرکز بر فرکانس کلمات، سعی میکنند معنا و زمینه (Context) را در یک نمایش فشرده و متراکم (Dense) ثبت کنند.
- Embedding چیست؟
یک embedding روشی برای تبدیل کلمات در یک سند به یک لیست از اعداد یا یک بردار است. اگر بردار دو یا سه بعدی باشد، به راحتی میتوان تصور کرد که یک کلمه در یک فضای دوبعدی یا سهبعدی قرار میگیرد، جایی که کلمات با معانی مشابه در این “فضای برداری” به یکدیگر نزدیک خواهند بود.
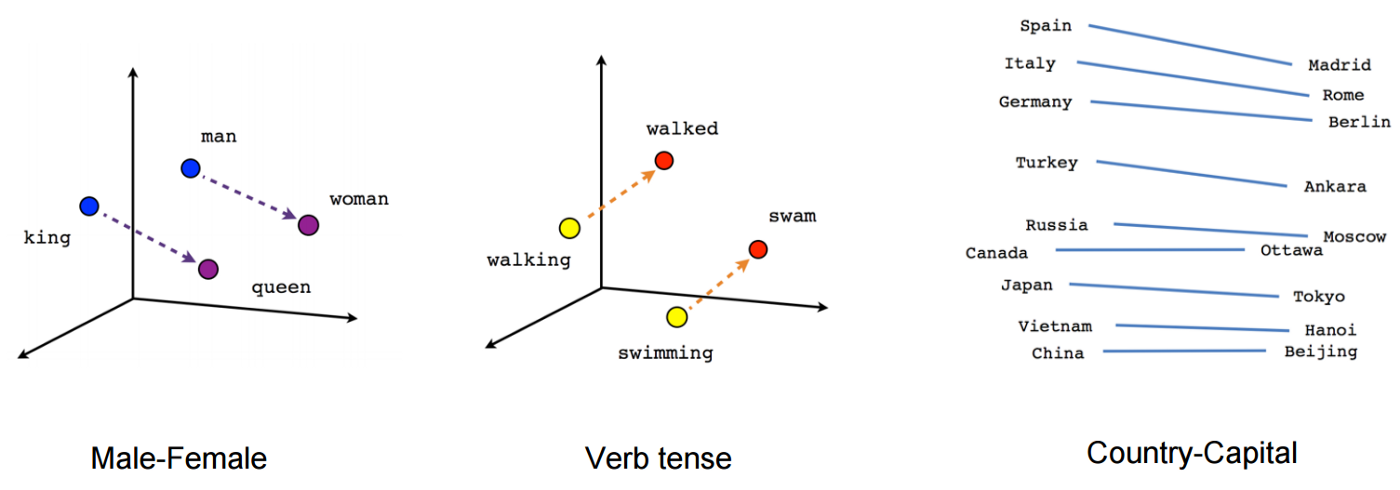
مثالی از فضای برداری
- مدلهای زبانی تولیدکننده Embedding:
- BERT (Bidirectional Encoder Representations from Transformers):
این مدل یک نقطه عطف در NLP بود که با درک دوطرفه زمینه، قادر به تولید نمایشهای متنی بسیار غنی بود. BERT برای هر کلمه بسته به جملهای که در آن قرار دارد، یک بردار منحصر به فرد تولید میکند.
- BERT (Bidirectional Encoder Representations from Transformers):
میتوانید جهت آشنایی بیشتر با BERT مقاله زیر را مطالعه کنید:
بردار ساختن از کلمات به کمک روش BERT
- Sentence Transformers:
این کتابخانه که بر پایه مدلهایی مانند BERT ساخته شده، به طور خاص برای تولید یک بردار معنایی باکیفیت برای کل جملات و پاراگرافها تنظیم (Fine-tune) شده است. این ویژگی آن را به ابزاری ایدهآل برای وظایفی مانند جستجوی معنایی و خوشهبندی تبدیل کرده است.
میتوانید جهت آشنایی بیشتر با Sentence Transformerها مقالات زیر را مطالعه کنید:
1. SentenceTransformers Documentation
2. مدل ترنسفورمر (Transformer Model) چیست؟
3. Sentence Transformer چیست؟
نقش Embedding در خوشهبندی معنایی
استفاده از Embeddingها به عنوان روش نمایش متن، خوشهبندی را از یک فرآیند مبتنی بر آمار کلمات به یک فرآیند مبتنی بر درک معنا تبدیل میکند. این نقش را میتوان در چند جنبه کلیدی خلاصه کرد:
-
غلبه بر مشکل هممعنایی و مترادفها: چون جملات “کوهنوردی برویم” و “یک پیادهروی در جنگل” بردارهای نزدیکی خواهند داشت، یک الگوریتم خوشهبندی میتواند آنها را به درستی در یک گروه قرار دهد. این مشکل در روشهای سنتی حلنشدنی بود.
-
حل چالش متنهای کوتاه: مدلهای زبانی بزرگ با استفاده از دانشی که از تریلیونها کلمه کسب کردهاند، میتوانند حتی برای عبارات کوتاه نیز بردارهای معنایی معناداری تولید کنند. این امر به طور مستقیم چالش “متن کوتاه” را که در مقدمه به آن اشاره شد، هدف قرار میدهد.
-
کاهش ابعاد مؤثر: اگرچه ابعاد بردارهای Embedding همچنان بالاست، اما این بردارها متراکم (Dense) و پر از اطلاعات معنایی هستند. برخلاف بردارهای پراکنده TF-IDF که اکثر مقادیر آنها صفر است، هر بعد در یک بردار Embedding یک ویژگی معنایی را کدگذاری میکند. این ویژگی باعث میشود الگوریتمهای مبتنی بر فاصله (مانند K-means) که هسته اصلی FAISS را تشکیل میدهند، عملکرد بسیار بهتری داشته باشند.
در نهایت، فرآیند خوشهبندی معنایی مدرن به این صورت است که ابتدا تمام متون با استفاده از یک مدل مانند Sentence Transformers به بردارهای Embedding تبدیل میشوند و سپس این بردارها به عنوان ورودی به الگوریتمهای خوشهبندی (که اغلب در FAISS پیادهسازی شدهاند) داده میشوند. نتیجه، خوشههایی است که بر اساس مفهوم و محتوای واقعی متون شکل گرفتهاند، نه صرفاً بر اساس تکرار کلمات سطحی.
FAISS: معماری، قابلیتها و الگوریتمهای کلیدی
FAISS (Facebook AI Similarity Search) یک کتابخانه متنباز و بهینهسازیشده است که توسط تیم تحقیقاتی هوش مصنوعی متا (FAIR) توسعه یافته است. هدف اصلی این کتابخانه، امکان جستجوی سریع و کارآمد شباهت و خوشهبندی بردارهای فشرده (Dense Vectors) در مجموعه دادههای بسیار بزرگ است. قابلیت کلیدی FAISS در این است که میتواند با مجموعه دادههایی کار کند که آنقدر بزرگ هستند که ممکن است در حافظه RAM یک سیستم معمولی جا نشوند.
در چارچوب خوشهبندی متن، پس از تبدیل اسناد به بردارهای معنایی (Embeddings)، FAISS به عنوان موتور محاسباتی عمل میکند که عملیات سنگین و زمانبر یابی نزدیکترین همسایهها (Nearest Neighbor Search) را که قلب بسیاری از الگوریتمهای خوشهبندی است، با سرعتی فوقالعاده انجام میدهد.
جستجوی شباهت چیست؟
با فرض داشتن مجموعهای از بردارهای xi در d بعد، FAISS یک ساختار داده بر روی آنها در حافظه RAM ایجاد میکند. پس از ساخته شدن این ساختار، هنگامی که یک بردار جدید x در d بعد به آن داده میشود، FAISS به صورت کارآمد عملیات زیر را انجام میدهد:
که در آن ‖⋅‖ فاصله اقلیدسی ($L^2$) است.
در اصطلاحات FAISS، این ساختار داده یک شاخص (index) است، یعنی یک شیء که دارای یک متد add برای اضافه کردن بردارهای $x_i$ است.
توجه داشته باشید که فرض بر این است که بردارهای $ x_i $ ثابت هستند.
محاسبه آرگمین (argmin) عملیات جستجو روی شاخص محسوب میشود.
این تمام کاری است که FAISS انجام میدهد، اما قابلیتهای دیگری نیز دارد:
- بازگرداندن نه تنها نزدیکترین همسایه، بلکه دوم، سوم، … و k-اُمین همسایهی نزدیک.
- جستجوی چندین بردار به صورت همزمان به جای یک بردار (پردازش دستهای). برای بسیاری از انواع شاخصها، این کار سریعتر از جستجوی تکتک بردارها است.
- معاوضه دقت با سرعت؛ برای مثال، ارائه یک نتیجه نادرست در ۱۰٪ مواقع با استفاده از روشی که ۱۰ برابر سریعتر است یا ۱۰ برابر حافظه کمتری مصرف میکند.
- انجام جستجوی بیشینه حاصلضرب داخلی \(\arg\max_{x_i} \langle x, x_i \rangle\) به جای جستجوی حداقل فاصله اقلیدسی. پشتیبانی از معیارهای فاصله دیگر (مانند L1، Linf و غیره) نیز به صورت محدود وجود دارد.
- ذخیره شاخص روی دیسک به جای حافظه RAM.
چرا FAISS یک نقطه عطف است؟
در یک رویکرد ساده (Brute-Force)، برای پیدا کردن نزدیکترین بردار به یک بردار پرسوجو (Query)، باید فاصله آن بردار با تمام بردارهای موجود در پایگاه داده محاسبه شود. این عملیات دارای پیچیدگی زمانی O(N) است که برای میلیونها یا میلیاردها بردار، کاملاً غیرعملی است. FAISS با ساختارهای داده و الگوریتمهای هوشمندانه، این پیچیدگی را به شدت کاهش میدهد و جستجو را در زمانی نزدیک به لگاریتمی یا حتی ثابت ممکن میسازد.
مفاهیم اصلی و معماری FAISS
۱. شاخص (Index)
مفهوم مرکزی در FAISS، “شاخص” است. یک شاخص یک ساختار داده است که از بردارهای ورودی ساخته میشود. این شاخص دو عمل اصلی دارد:
add(vector):
برای اضافه کردن بردارها به شاخص.search(query_vector, k):
برای پیدا کردنkبردار نزدیکترین به بردار پرسوجو در شاخص.
۲. معیار فاصله (Distance Metric)
FAISS عمدتاً از فاصله اقلیدسی (L2) استفاده میکند، اما از معیارهای دیگری مانند ضرب داخلی (Inner Product) که در مدلهای توصیهدهنده رایج است، و L1 نیز پشتیبانی میکند.
۳. معاوضه بین دقت، سرعت و حافظه
فلسفه اصلی FAISS بر پایه معاوضه (Trade-off) استوار است. کاربر میتواند بر اساس نیاز خود، بین دقت جستجو (پیدا کردن دقیقترین نتیجه)، سرعت اجرا و میزان مصرف حافظه یکی را انتخاب کند. برای مثال، میتوان با پذیرش ۱۰٪ خطا، به سرعتی ۱۰ برابر بیشتر دست یافت.
الگوریتمهای کلیدی و انواع شاخصها
FAISS طیف وسیعی از شاخصها را ارائه میدهد که هر کدام برای سناریوی خاصی بهینه شدهاند. در ادامه مهمترین آنها بررسی میشوند:
۱. IndexFlat (جستجوی دقیق)
این سادهترین نوع شاخص است که جستجوی دقیق (Exact) و Brute-Force انجام میدهد. تمام بردارها در حافظه ذخیره شده و فاصله پرسوجو با همه آنها محاسبه میشود.
- مزیت: بالاترین دقت ممکن.
- عیب: کند و مصرفکننده حافظه بالا. فقط برای مجموعه دادههای کوچک (چند صد هزار بردار) مناسب است.
- مثال:
IndexFlatL2برای جستجوی دقیق با فاصله L2.
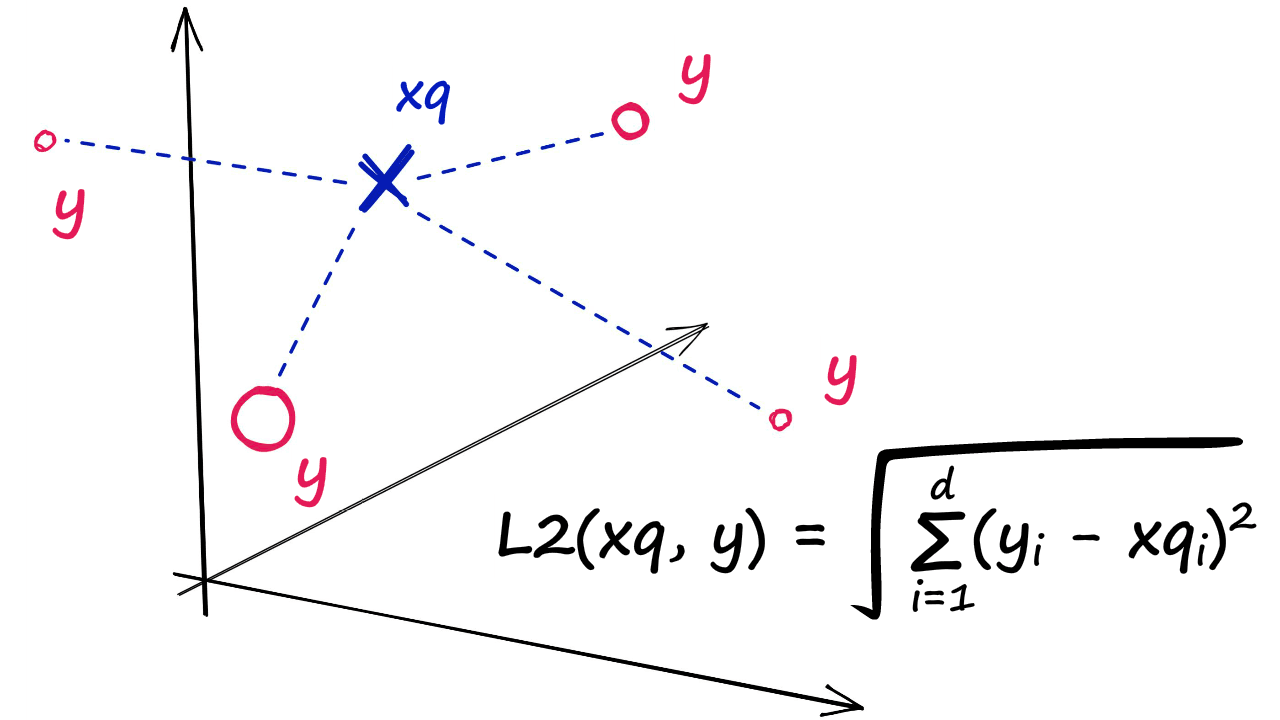
محاسبه فاصله L2 بین بردار پرسوجو xq و بردارهای indexشده (به عنوان y نشاندادهشده)
مثال كد:
import faiss
import numpy as np
dimension = 128
n = 10000
vectors = np.random.rand(n, dimension).astype('float32')
query = np.random.rand(1, dimension).astype('float32')
index = faiss.IndexFlatL2(dimension)
index.add(vectors)
k = 5
distances, indices = index.search(query, k)
print("distances:\n", distances)
print("indices:\n", indices)
distances:
[[14.145712 14.186624 14.391592 14.5573845 14.564116 ]]
indices:
[[4860 5206 7413 4846 294]]
۲. IVF (Inverted File Index)
ایندکسهای IVF فضای برداری را به چندین خوشه (Voronoi Cell) تقسیم میکنند. در زمان جستجو، فقط خوشههای نزدیک به بردار پرسوجو بررسی میشوند.
الگوریتم:
- خوشهبندی: با استفاده از K-means، بردارها به
nlistخوشه تقسیم میشوند. - جستجو: فاصله بردار پرسوجو با مراکز خوشهها محاسبه شده و فقط
nprobeخوشه نزدیک جستجو میشوند.
پارامترهای کلیدی:
nlist: تعداد خوشهها.nprobe: تعداد خوشههایی که در زمان جستجو بررسی میشوند.
ویژگیها:
- سرعت: بسیار سریعتر از Flat برای مجموعه دادههای بزرگ.
- دقت: با افزایش
nprobeدقت افزایش مییابد. - مصرف حافظه: متوسط.
موارد استفاده:
- مجموعه دادههای بزرگ که نیاز به تعادل سرعت و دقت دارند.
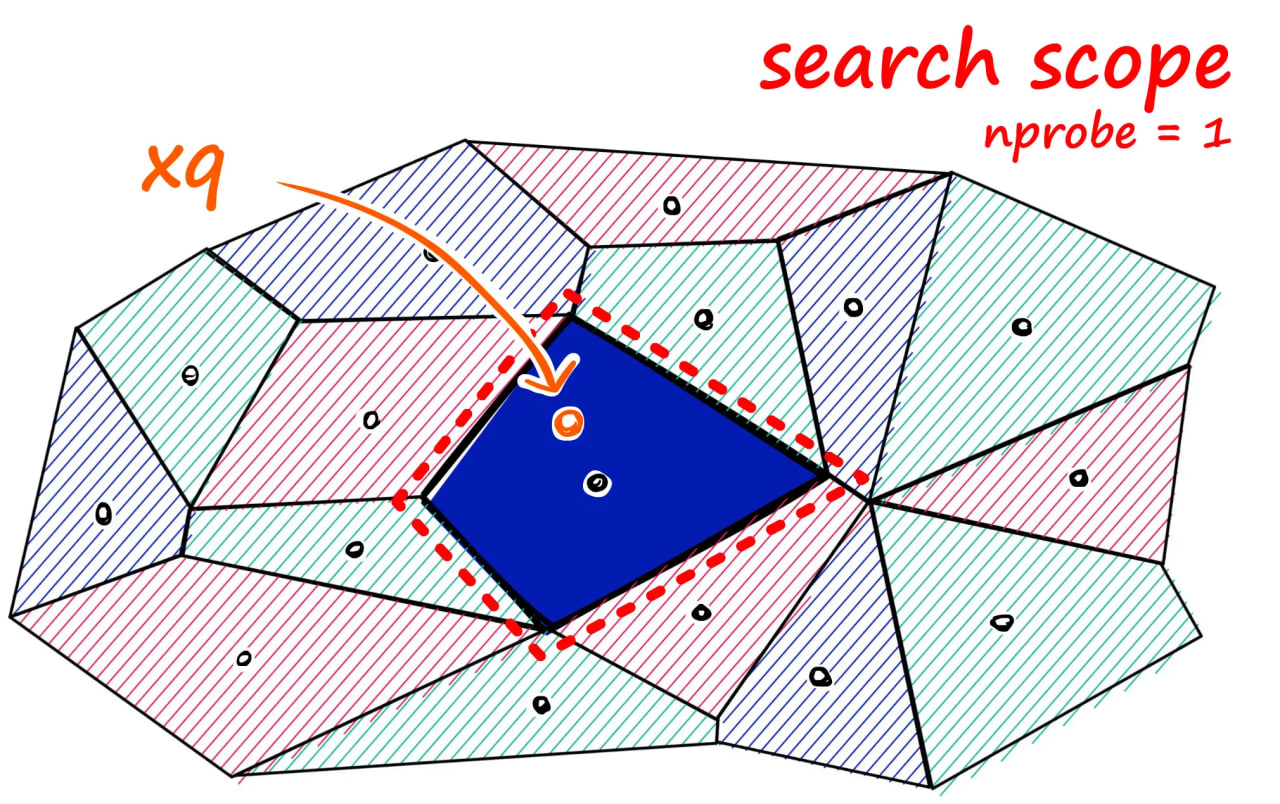
مثال کد:
quantizer = faiss.IndexFlatL2(dimension)
nlist = 100
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist, faiss.METRIC_L2)
index_ivf.train(vectors)
index_ivf.add(vectors)
distances, indices = index_ivf.search(query, k)
print("distances:\n", distances)
print("indices:\n", indices)
distances:
[[15.838599 15.847076 16.249146 16.268185 16.29538 ]]
indices:
[[3847 9148 993 7715 4171]]
PQ (Product Quantization)
PQ یک روش فشردهسازی با اتلاف (Lossy Compression) است که بردارهای ابعاد بالا را به کدهای کوتاه و نمادین تبدیل میکند. ایده اصلی این است که فضای برداری را به ضرب دکارتی زیرفضاهای با بعد پایینتر تجزیه کرده و هر زیرفضا را به صورت مستقل کوانتیزه .
نکته کلیدی: PQ تعداد بردارها را تغییر نمیدهد، بلکه هر بردار را به یک کد کوتاه (مثلاً ۸ بایت) تبدیل میکند که نماینده مرکز خوشههای مختلف در زیرفضاها است.
۲. مراحل اجرای Product Quantization
فرآیند PQ را میتوان به چند مرحله اصلی تقسیم کرد. در ادامه، این مراحل با یک مثال عملی توضیح داده میشوند.
مرحله ۱: تقسیمبندی بردارها (Segmentation)
فرض کنید برداری با بعد ۱۲۸ داریم. این بردار به ۸ بخش ۱۶ تایی تقسیم میشود:
- بردار اصلی:
[x₁, x₂, ..., x₁₂₈] - بخشها:
[seg₁, seg₂, ..., seg₈]که هرsegدارای ۱۶ مقدار است.
مرحله ۲: آموزش کوانتایزر (Training)
برای هر بخش (زیرفضا)، به صورت مستقل خوشهبندی K-means انجام میشود:
- برای هر بخش،
kمرکز خوشه (Centroid) محاسبه میشود. - مجموعه این مراکز، (Codebook) آن بخش را تشکیل میدهد.
- مثلاً اگر
k=256باشد، هر بخش ۲۵۶ centroid خواهد داشت.
مرحله ۳: کدگذاری (Encoding)
برای هر بردار در پایگاه داده:
- در هر بخش، نزدیکترین centroid پیدا شده و شناسه آن (ID) ذخیره میشود.
- نتیجه: یک کد PQ که از ترکیب IDهای centroidها تشکیل شده است.
- مثال: کد
[5, 24, 132, ..., 77]که هر عدد بین ۰ تا ۲۵۵ است (۸ بیت برای هر بخش).
مرحله ۴: فشردهسازی حافظه
- بردار اصلی ۱۲۸ بعدی: ۱۲۸ × ۳۲ بیت = ۴۰۹۶ بیت (۵۱۲ بایت)
- کد PQ: ۸ بخش × ۸ بیت = ۶۴ بیت (۸ بایت)
- نتیجه: کاهش حافظه به میزان ۶۴ برابر!
۳. جستجوی شباهت با PQ
در زمان جستجو، فاصله بین بردار پرسوجو و بردارهای فشردهشده به صورت تقریبی محاسبه میشود:
محاسبه فاصله نامتقارن (Asymmetric Distance)
- بردار پرسوجو نیز به همان ۸ بخش تقسیم میشود.
- برای هر بخش، فاصله آن با تمام ۲۵۶ centroid مربوطه محاسبه و در یک جدول فاصله ذخیره میشود.
- فاصله نهایی با جمع کردن فاصلههای بخشهای مختلف (با استفاده از جداول) تخمین زده میشود.
چرا نامتقارن؟ چون بردار پرسوجو در حالت اصلی خود باقی میماند، در حالی که بردارهای پایگاه داده فشرده شدهاند.
۴. پارامترهای کلیدی در PQ
| پارامتر | توضیح | تأثیر |
|---|---|---|
| M | تعداد زیرفضاها (بخشها) | افزایش M → دقت بالاتر اما حافظه بیشتر |
| nbits | تعداد بیت برای هر بخش (معمولاً ۸) | افزایش nbits → کدهای طولانیتر و دقت بالاتر |
| k | تعداد خوشهها در هر زیرفضا (k = 2^nbits) |
افزایش k → دقت بالاتر اما حافظه بیشتر |
- نکته: برای حافظه بهینه، مقدار
M * nbitsباید مضربی از ۸ باشد.
# Parameters
d = 128 # Vector dimension
M = 8 # Number of segments/subquantizers
nbits = 8 # Bits per segment
# Create index
index = faiss.IndexPQ(d, M, nbits)
# Train index (with similar data distribution)
index.train(training_vectors)
# Add vectors to the index
index.add(database_vectors)
# Search
distances, labels = index.search(query, k=10)
۴. HNSW (Hierarchical Navigable Small World)
یکی از مهمترین و جالبترین الگوریتمها در زمینه جستجوی شباهت در مقیاس بزرگ است. Hierarchical Navigable Small World (HNSW) یک الگوریتم پیشرفته برای پیدا کردن نزدیکترین همسایهها (Nearest Neighbor Search) در مجموعه دادههای بسیار بزرگ است.
بیایید نام آن را تجزیه کنیم تا بهتر بفهمیم:
- Hierarchical (سلسلهمراتبی): الگوریتم چندین لایه یا سطح دارد، مانند یک ساختمان چند طبقه.
- Navigable Small World (دنیای کوچک قابل پیمایش): این یک مفهوم از نظریه گراف است. دنیای کوچک به شبکهای گفته میشود که در آن اکثر گرهها (نقاط) همسایه نیستند، اما میتوان با تعداد کمی گام از هر گرهای به گرهی دیگر رسید. (مانند ایده “شش دست کجایی” در شبکههای اجتماعی).
HNSW این دو ایده را با هم ترکیب میکند تا یک ساختار داده بسیار کارآمد برای جستجو بسازد.
چگونه کار میکند؟ (یک مثال ساده)
تصور کنید میخواهید در یک شهر بسیار بزرگ (مجموعه دادهای با میلیاردها بردار) آدرس یک مکان خاص (بردار پرسوجو) را پیدا کنید. به جای اینکه خیابان به خیابان بگردید (جستجوی خطی یا کند)، از یک سیستم چندلایه نقشه استفاده میکنید.
مرحله ۱: ساختار سلسلهمراتبی (چند لایه نقشه)
HNSW یک گراف (شبکهای از نقاط و اتصالات) ایجاد میکند که چندین لایه دارد:
- لایه بالایی: این لایه نقشه کل شهر است. فقط تعداد کمی از نقاط کلیدی (مثل میادین اصلی یا ایستگاههای مترو) در آن وجود دارد و اتصالات بین آنها بسیار بلند است (شبیه اتوبانها). این لایه بسیار خلوت است.
- لایههای میانی: این لایهها نقشه مناطق مختلف شهر هستند. جزئیات بیشتری دارند و نقاط بیشتری را شامل میشوند.
- لایه پایینی: این لایه نقشه محلهای است. تمام نقاط (تمام بردارهای مجموعه داده) در این لایه وجود دارند و اتصالات بین آنها کوتاه است (شبیه کوچههای خیابان).
مرحله ۲: فرآیند جستجو (پیمایش از کل به جزء)
حالا شما بردار پرسوجوی خود را دارید و میخواهید نزدیکترین بردارها را پیدا کنید:
- شروع از بالا: جستجو از لایه بالایی (خلوت) شروع میشود. الگوریتم در این لایه، نزدیکترین نقطه به بردار پرسوجوی شما را پیدا میکند. چون این لایه نقاط کمی دارد، این کار بسیار سریع است.
- پرش به لایه پایینتر: الگوریتم از نقطهای که در لایه بالا پیدا کرده، به لایه بعدی “پرش” میکند. حالا در یک لایه با جزئیات بیشتر هستیم. دوباره در این لایه، نزدیکترین همسایه را به هدف پیدا میکند.
- تکرار تا رسیدن به پایین: این فرآیند (پرش و جستجوی محلی) لایه به لایه ادامه پیدا میکند تا به لایه پایینی (لایه محلهای) برسد.
- جستجوی نهایی در لایه پایین: وقتی به لایه پایین میرسیم، در یک محله بسیار نزدیک به هدف قرار داریم. اکنون الگوریتم در این لایه پر از جزئیات، جستجوی دقیقتری را برای پیدا کردن نزدیکترین همسایهها انجام میدهد. چون محدوده جستجو بسیار کوچک شده، این مرحله نیز بسیار سریع است.
نتیجه: به جای جستجو در کل مجموعه داده، HNSW به سرعت مسیر را از یک نقطه کلی به یک نقطه بسیار مشخص محدود میکند و در نهایت جستجوی دقیق را در یک محدوده کوچک انجام میدهد.

مثال کد:
import faiss
import numpy as np
# Generate sample data
d = 128 # Vector dimension
nb = 10000 # Number of database vectors
nq = 100 # Number of queries
xb = np.random.random((nb, d)).astype('float32') # Database vectors
xq = np.random.random((nq, d)).astype('float32') # Query vectors
# Create HNSW index
M = 16 # Maximum number of connections per node
index = faiss.IndexHNSWFlat(d, M)
# Set parameters
index.hnsw.efConstruction = 200 # Construction time parameter (higher = better recall, slower build)
index.hnsw.efSearch = 50 # Search time parameter (higher = better recall, slower search)
# Add data to the index
index.add(xb)
# Perform search
k = 5 # Number of nearest neighbors to retrieve
distances, labels = index.search(xq, k)
print(f"distances: {distances[:2]}") # Display distances for first 2 queries
print(f"labels: {labels[:2]}") # Display labels/indices for first 2 queries
distances: [[14.077484 14.57412 14.74098 14.842341 14.909969 ]
[13.139176 13.226721 14.486782 14.6202755 14.68724 ]]
labels: [[9689 9713 4913 8693 4980]
[8132 9254 9418 6248 6564]]
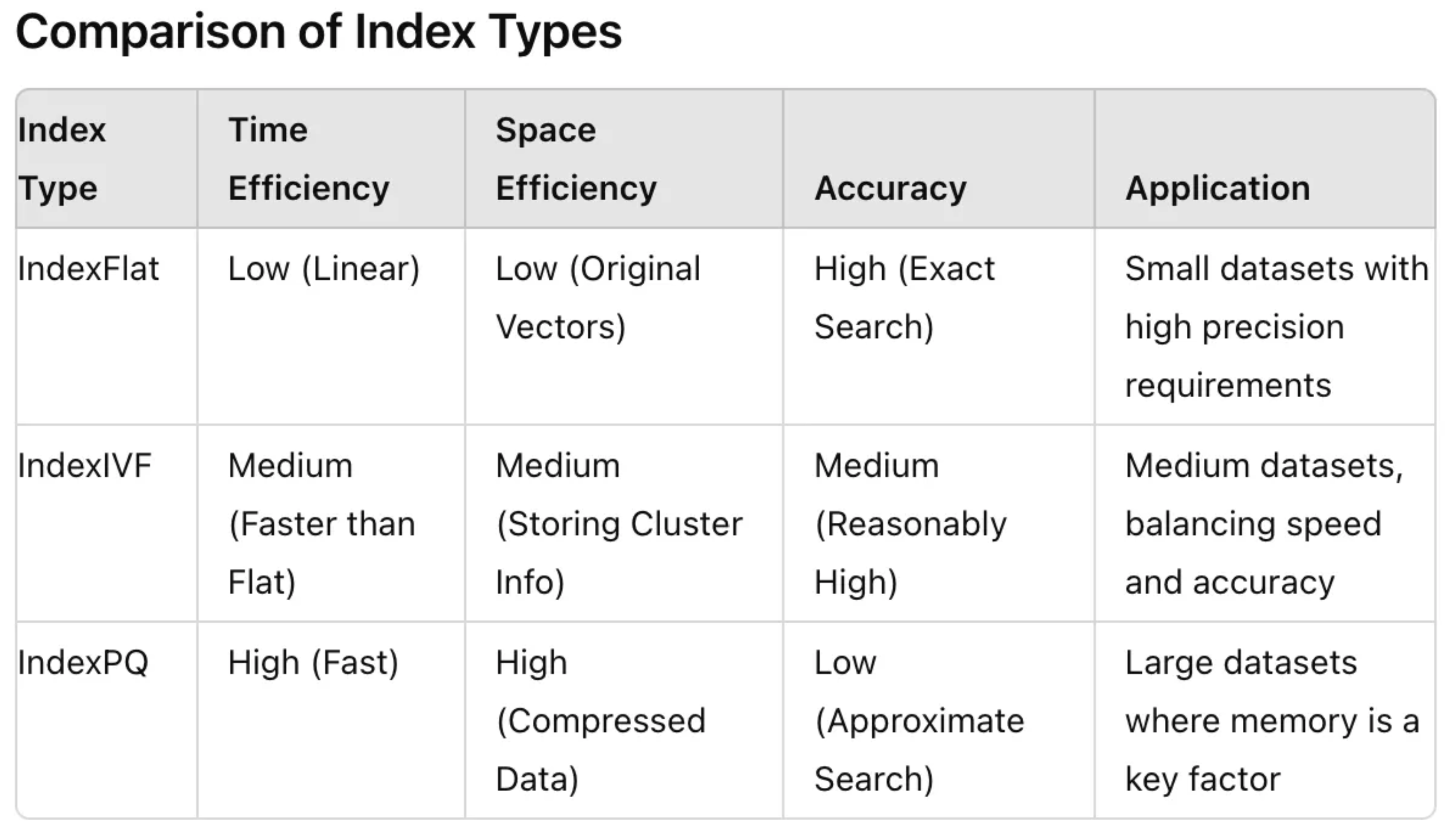
مقایسه شاخصهای متفاوت
نقش FAISS در خوشهبندی
FAISS نه تنها برای جستجوی شباهت، بلکه برای خودِ فرآیند خوشهبندی نیز ابزارهای قدرتمندی ارائه میدهد:
- پیادهسازی K-means: FAISS شامل یک پیادهسازی بسیار بهینه از الگوریتم K-means است که میتواند بر روی میلیاردها بردار اجرا شود. این پیادهسازی به شدت از عملیات ماتریسی و GPU بهره میبرد.
- شتابدهی به الگوریتمهای دیگر: الگوریتمهایی مانند DBSCAN یا خوشهبندی طیفی که به عملیات یابی نزدیکترین همسایه وابستهاند، میتوانند از شاخصهای FAISS برای سرعت بخشیدن به این مرحله حیاتی استفاده کنند.
مثال عملی: ساخت شاخص و جستجو در FAISS
در ادامه یک مثال ساده با Python برای ایجاد یک شاخص IndexFlatL2 و انجام جستجو آورده شده است:
پیشنیازها
ابتدا کتابخانههای مورد نیاز را نصب کنید:
pip install faiss-cpu
import numpy as np
import faiss
# 1. Create sample data (set of 1000 vectors with dimensions 64)
d = 64 # Vector dimensions
nb = 1000 # Number of vectors in the database
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
# 2. Create FAISS index
# IndexFlatL2 is an exact index that uses Euclidean distance
index = faiss.IndexFlatL2(d)
# 3. Add vectors to the index
print(f"Training index and adding {nb} vectors...")
index.add(xb)
print(f"Number of vectors in index: {index.ntotal}")
# 4. Perform search
nq = 5 # Number of query vectors
xq = np.random.random((nq, d)).astype('float32')
k = 4 # Find 4 nearest neighbors for each query
print(f"\nSearching for {nq} query vectors...")
D, I = index.search(xq, k) # D: distances, I: indices
# Display results
print("Search results (indices):")
print(I)
print("Matching distances:")
print(D.round(3))
Search results (indices):
[[970 250 429 856]
[932 51 483 550]
[247 632 175 473]
[214 755 856 175]
[952 516 582 238]]
Matching distances:
[[6.499 6.581 7.206 7.227]
[5.984 6.115 6.304 6.336]
[6.435 6.523 6.648 6.651]
[5.607 6.52 6.762 6.893]
[6.434 6.457 6.628 6.723]]
این مثال ساده، هسته اصلی عملکرد FAISS را نشان میدهد. در کاربردهای واقعی، از شاخصهای پیچیدهتری مانند IndexIVFFlat یا IndexHNSW برای مقیاسپذیری استفاده میشود.
مثالی از خوشهبندی متن با FAISS با استفاده از یک دیتاست ساختگی
ساخت دیتاست ساختگی
ما چهار موضوع کاملاً متفاوت را تعریف میکنیم و برای هر کدام چند جمله نمونه تولید میکنیم:
- Technology (فناوری): جملاتی مربوط به هوش مصنوعی، GPU و یادگیری ماشین.
- Cooking (آشپزی): جملاتی مربوط به دستور پخت، مواد اولیه و تکنیکهای آشپزی.
- Travel (سفر): جملاتی مربوط به رزرو پرواز، جاذبههای توریستی و ماجراجویی.
- Sports (ورزش): جملاتی مربوط به مسابقات، ورزشکاران و تمرینات.
کد کامل خوشهبندی روی دیتاست نمونه
در اینجا کد کامل برای ایجاد دیتاست، خوشهبندی و ارزیابی آن آورده شده است.
# 1. Imports
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
from sklearn.metrics import silhouette_score, adjusted_rand_score
import umap
import matplotlib.pyplot as plt
# 2. Create a Synthetic Dataset
# We define 4 distinct themes and generate sentences for each.
# The true labels are the theme index (0, 1, 2, 3).
tech_texts = [
"Artificial intelligence is transforming the tech industry.",
"The new GPU from Nvidia offers incredible performance.",
"Machine learning models require large datasets to be effective.",
"Cloud computing provides scalable and flexible solutions.",
"Quantum computing could revolutionize data processing."
]
cooking_texts = [
"Bake the cake at 350 degrees Fahrenheit for 30 minutes.",
"Chop the onions finely before sautéing them in olive oil.",
"This pasta recipe requires fresh basil and parmesan cheese.",
"A good chef knows how to balance sweet and savory flavors.",
"Knead the dough until it is smooth and elastic."
]
travel_texts = [
"We booked a flight to Paris for our summer vacation.",
"The ancient ruins are a must-see historical attraction.",
"Backpacking through Southeast Asia is an amazing experience.",
"Don't forget your passport when traveling internationally.",
"The hotel offers a stunning view of the ocean."
]
sports_texts = [
"The team won the championship game in the final seconds.",
"He scored a decisive goal in the last minute of the match.",
"Tennis requires great agility and mental stamina.",
"The marathon runners trained for months for the big race.",
"The basketball player made an incredible slam dunk."
]
# Combine all texts and create true labels
texts = tech_texts + cooking_texts + travel_texts + sports_texts
true_labels = [0] * len(tech_texts) + [1] * len(cooking_texts) + [2] * len(travel_texts) + [3] * len(sports_texts)
print(f"Created a synthetic dataset with {len(texts)} sentences across 4 themes.")
print("Sample text:", texts[0])
print("Corresponding true label:", true_labels[0])
# 3. Configuration
MODEL_NAME = 'sentence-transformers/paraphrase-multilingual-mpnet-base-v2'
N_CLUSTERS = 4 # We know there are 4 themes
# 4. Generate Embeddings
print("\nGenerating embeddings...")
model = SentenceTransformer(MODEL_NAME)
embeddings = model.encode(texts, show_progress_bar=True)
embedding_dim = embeddings.shape[1]
print("Embeddings generated.")
print("Shape of the embedding matrix:", embeddings.shape)
# 5. Build FAISS Index and Perform K-Means Clustering
print("\nBuilding FAISS index and performing K-Means clustering...")
index = faiss.IndexFlatL2(embedding_dim)
kmeans = faiss.Clustering(embedding_dim, N_CLUSTERS)
# Note: FAISS kmeans training can be sensitive to the number of iterations.
# The default is usually fine for small datasets.
kmeans.train(np.array(embeddings).astype('float32'), index)
_, cluster_labels = index.search(np.array(embeddings).astype('float32'), 1)
cluster_labels = cluster_labels.flatten()
print("Clustering finished.")
# 6. Evaluation
print("\n--- Evaluation ---")
sil_score = silhouette_score(embeddings, cluster_labels)
ari_score = adjusted_rand_score(true_labels, cluster_labels)
print(f"Silhouette Score: {sil_score:.4f}")
print(f"Adjusted Rand Index (ARI): {ari_score:.4f}")
# 7. Visualization
print("\nGenerating visualization...")
reducer = umap.UMAP(n_components=2, random_state=42)
embedding_2d = reducer.fit_transform(embeddings)
plt.figure(figsize=(12, 10))
# Plot points colored by predicted cluster labels
scatter = plt.scatter(
embedding_2d[:, 0], embedding_2d[:, 1],
c=cluster_labels, cmap='viridis', s=50, alpha=0.8
)
plt.title('Text Clustering on Data with FAISS')
plt.xlabel('UMAP Dimension 1')
plt.ylabel('UMAP Dimension 2')
plt.legend(*scatter.legend_elements(), title='Predicted Clusters')
plt.grid(True)
plt.show()
# Optional: Add text labels to the plot for better interpretation
plt.figure(figsize=(12, 10))
for i, text in enumerate(texts):
plt.text(embedding_2d[i, 0], embedding_2d[i, 1], text[:30] + '...', fontsize=10)
# Color the points based on true labels for comparison
plt.scatter(embedding_2d[:, 0], embedding_2d[:, 1], c=true_labels, cmap='viridis', s=2000, alpha=0.2)
plt.title('Text Clustering on Data (with labels)')
plt.xlabel('UMAP Dimension 1')
plt.ylabel('UMAP Dimension 2')
plt.grid(True)
plt.show()
print("Done.")
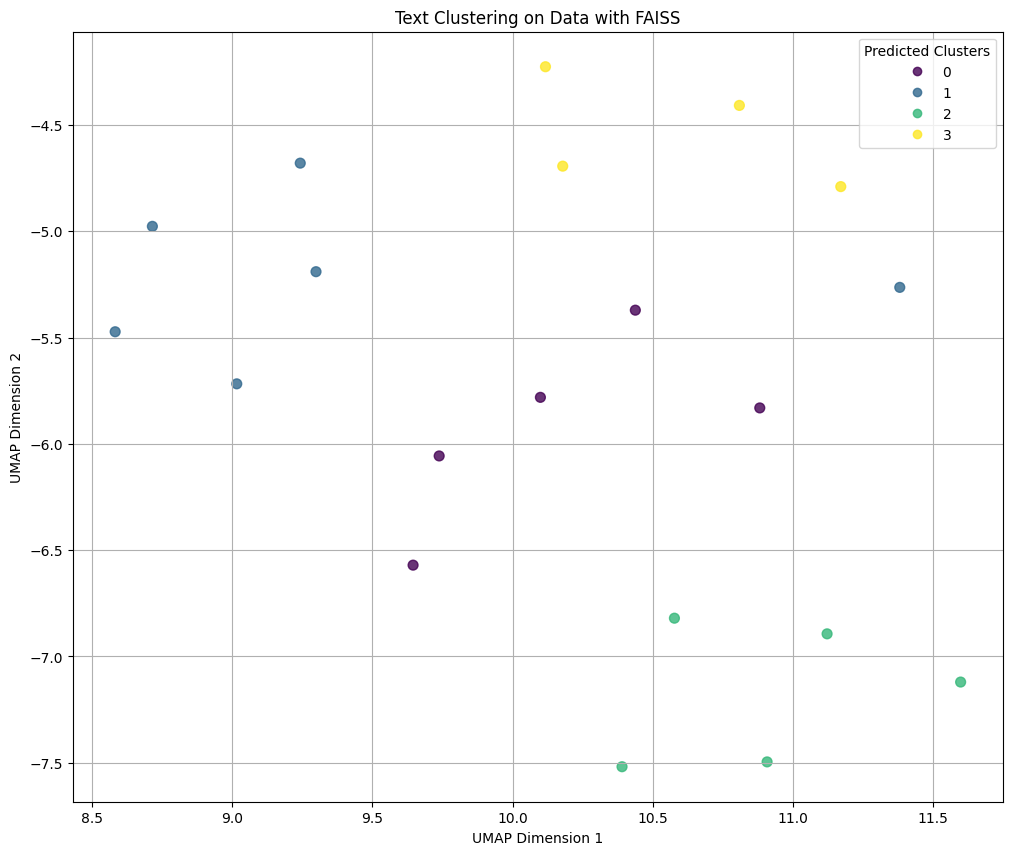
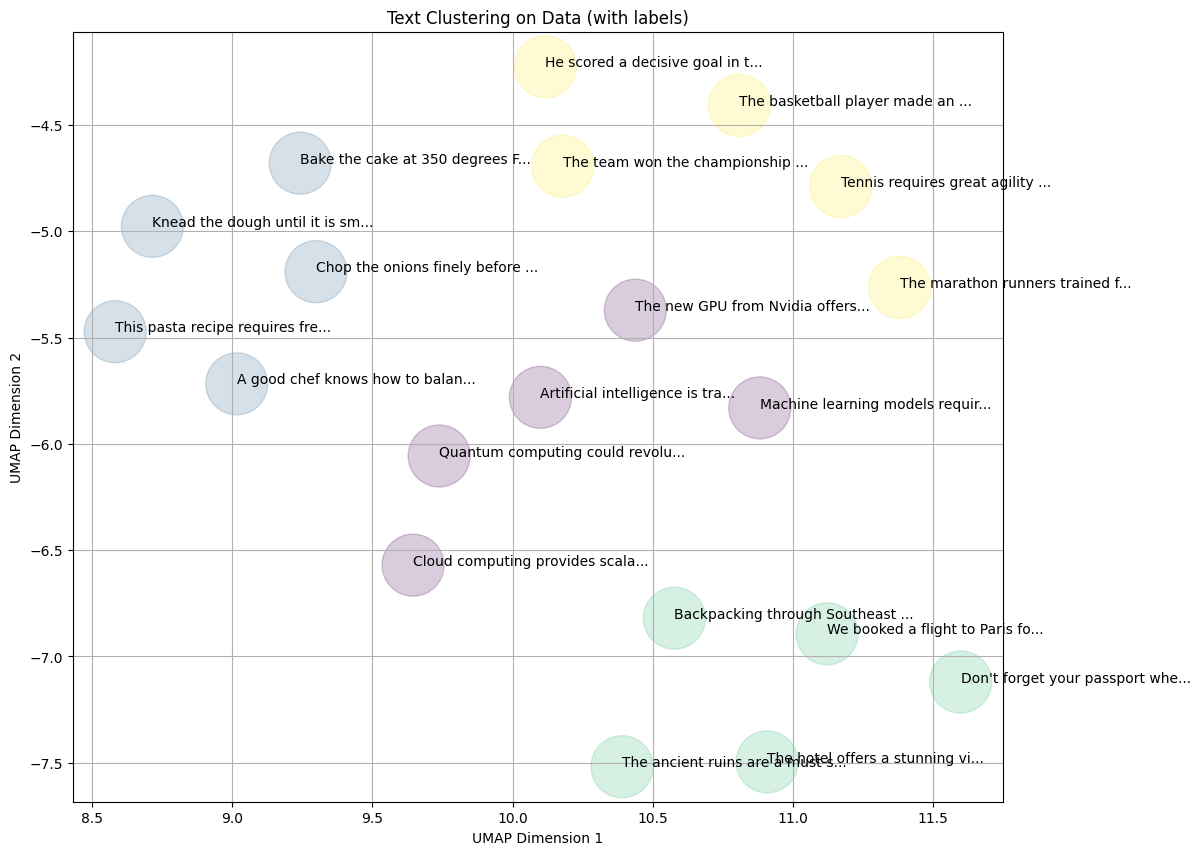
تحلیل نتایج: تفسیر امتیاز Silhouette و ARI
پس از اجرای الگوریتم خوشهبندی روی دیتاست ساختگی، نتایج زیر به دست آمدند:
--- Evaluation ---
Silhouette Score: 0.1237
Adjusted Rand Index (ARI): 0.8588
این نتایج در نگاه اول ممکن است متناقض به نظر برسند، اما در واقع یک داستان بسیار مهم و آموزنده در مورد ماهیت دادهها و عملکرد الگوریتمها روایت میکنند: خوشهبندی شما در تخصیص برچسبها بسیار موفق عمل کرده است، اما خوشههای تولید شده از نظر هندسی، مرزهای مشخص و فاصله زیادی از یکدیگر ندارند. بیایید هر کدام را به تفکیک تحلیل کنیم.
تحلیل امتیاز Silhouette Score (0.1237): مرزهای نامشخص
Silhouette Score چیست؟ این معیار برای هر نقطه داده میسنجد که چقدر به خوشه خودش نزدیک است و چقدر به خوشه نزدیک دیگر دور است. امتیاز آن بین ۱- تا ۱+ است:
- نزدیک به +1: خوشهها فشرده و به خوبی از هم جدا هستند.
- نزدیک به ۰: خوشهها در حال همپوشانی هستند و مرزهای مشخصی ندارند.
- نزدیک به -1: نقاط احتمالاً در خوشه اشتباهی قرار گرفتهاند.
که در آن:
- a(i): میانگین فاصله از نقطه (i) تا تمام نقاط دیگر در همان خوشه.
- b(i): کمترین میانگین فاصله از نقطه (i) تا نقاط در هر خوشه دیگر (نزدیکترین خوشه همسایه).
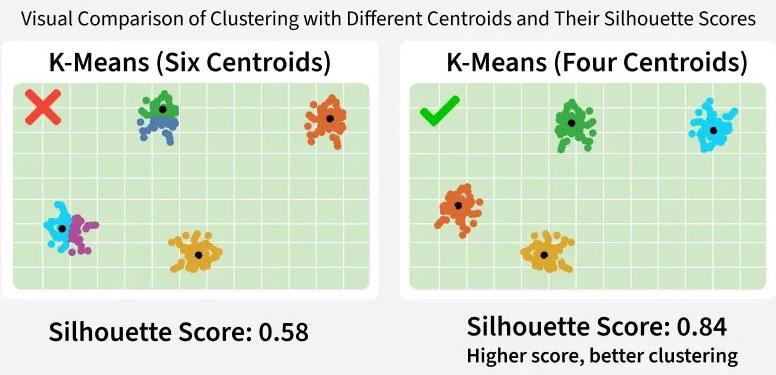
مقایسهی بصری خوشهبندی با مراکز مختلف و امتیاز Silhouette آنها
تفسیر امتیاز 0.1237: این امتیاز بسیار پایین است. این عدد به ما میگوید که خوشههای شما مرزهای بسیار مبهمی دارند. بسیاری از نقاط داده در مرز بین دو یا چند خوشه قرار دارند و فاصله آنها تا مرکز خوشه خودشان، بسیار کمتر از فاصلهشان تا مرکز خوشه مجاور نیست.
برای درک بهتر، میتوانید به چهار کشور روی نقشه فکر کنید که مرزهای طولانی و پیچیدهای با هم دارند. اگر یک شهر را در نظر بگیرید که دقیقاً روی مرز دو کشور قرار دارد، این شهر به پایتخت کشور خودش نزدیکتر است یا پایتخت کشور همسایه؟ تفاوت چندانی ندارد. این وضعیت دقیقاً چیزی است که امتیاز Silhouette پایین نشان میدهد.
تحلیل امتیاز ARI (0.8588): تطابق عالی با واقعیت
Adjusted Rand Index (ARI) چیست؟
شاخص Adjusted Rand Index - ARI یک معیار ارزیابی خوشهبندی است که شباهت بین دو خوشهبندی را میسنجد — معمولاً بین خوشههای پیشبینیشده و برچسبهای واقعی.
معیار ARI اندازهگیری میکند که الگوریتم خوشهبندی شما چقدر دادهها را در مقایسه با برچسبهای واقعی، به درستی گروهبندی کرده است. این کار را بر اساس تعداد جفتهای نمونه انجام میدهد که:
- در یک خوشه در هر دو برچسب پیشبینیشده و واقعی قرار دارند.
- در خوشههای متفاوت در هر دو برچسب پیشبینیشده و واقعی قرار دارند.
در واقع، این معیار همخوانی بین دو تقسیمبندی را بررسی میکند.
فرمول
\[\text{ARI} = \frac{\text{RI} - \text{Expected RI}}{\text{Max RI} - \text{Expected RI}}\]که در آن:
شاخص رند (Rand Index - RI) میگوید چند درصد از جفتهای دادهها (sample pairs) در هر دو خوشهبندی (partitions) (واقعی و پیشبینیشده) «توافق» دارند: یعنی یا هر دو با هم در یک گروه هستند و یا هر دو از هم جدا هستند.
این اصلاحیه (adjustment) به ما کمک میکند تا امتیازی را که ممکن است صرفاً به دلیل شانس و همزمانی تصادفی (random chance) به دست آمده، نادیده بگیریم و تنها شباهت واقعی را بسنجیم.
- نزدیک به ۱: تطابق تقریباً کامل بین خوشههای پیشبینی شده و دستهبندی واقعی وجود دارد.
- نزدیک به ۰: خوشهبندی انجام شده معادل یک دستهبندی تصادفی است.
- نزدیک به -۱: خوشهبندی کاملاً اشتباه است.
تفسیر امتیاز 0.8588: این یک امتیاز عالی و بسیار بالا است! این عدد به ما میگوید که الگوریتم K-Means به شکل فوقالعادهای توانسته است جملات را به خوشههای درست (فناوری، آشپزی، سفر، ورزش) تخصیص دهد. به عبارت دیگر، اگرچه مرزها مبهم بودند، اما الگوریتم تقریباً تمام نقاط را در سمت درست مرز قرار داده است.
چگونه این دو نتیجه میتوانند همزمان درست باشند؟
این پارادوکس ظاهری، کلید درک عمیقتر دادههای شماست. این وضعیت زمانی رخ میدهد که:
-
خوشهها از نظر مفهومی مجزا اما از نظر فضایی نزدیک هستند: موضوعات “فناوری” و “سفر” ممکن است کلمات مشترکی داشته باشند (مثلاً “اپلیکیشن رزرو پرواز”، “دوربین جدید برای سفر”). این اشتراکات باعث میشود که در فضای برداری، این دو خوشه در بخشهایی به یکدیگر نزدیک شوند و مرزهایشان مبهم شود (که منجر به Silhouette پایین میشود).
-
شکل خوشهها کروی نیست: الگوریتم K-Means فرض میکند که خوشهها کروی و هماندازه هستند. اگر شکل واقعی خوشهها کشیده یا نامنظم باشد، K-Means هنوز میتواند اکثر نقاط را به درستی دستهبندی کند (ARI بالا)، اما مرکز ثقل (Centroid) که بر اساس آن فاصلهها محاسبه میشود، ممکن است نماینده خوبی برای ساختار خوشه نباشد و نقاط مرزی را به درستی نشان ندهد (Silhouette پایین).
داستان به این صورت است:
الگوریتم با موفقیت “کشورها” را شناسایی و نقاط را به درستی به آنها اختصاص داد (ARI بالا). اما این “کشورها” در “نقشه جهان” فضای برداری، بسیار به یکدیگر نزدیک و با مرزهای پیچیدهای هستند (Silhouette پایین).
نتیجهگیری نهایی: چه چیزی مهمتر است؟
- موفقیت اصلی: ARI بالا (0.8588) نشان میدهد که هدف اصلی شما یعنی خوشهبندی معنایی و صحیح متنها با موفقیت کامل انجام شده است. این مهمترین معیار موفقیت شماست.
- نکته تشخیصی: Silhouette پایین (0.1237) یک ویژگی ذاتی دادههای شما را نشان میدهد، نه یک شکست بزرگ در الگوریتم. در کاربردهای عملی، اگر هدف شما بازیابی ساختار واقعی دادههاست، ARI معیار بسیار مهمتری است. Silhouette بیشتر یک ابزار تشخیصی برای درک کیفیت “شکلی” و “جدایی” خوشههاست. در این مثال، شما یک خوشهبندی مفید و صحیح را با موفقیت انجام دادهاید.
جستجوی معنایی (Semantic search with FAISS)
مقدمه
در این قسمت، یاد میگیریم چگونه یک موتور جستجوی معنایی (Semantic Search Engine) بسازیم که بتواند پاسخهای مرتبط را در میان اسناد مختلف پیدا کند.
منبع اصلی در این بخش، فصل 5 دوره آموزش LLM در سایت HuggingFace میباشد. جهت مطالعه بیشتر میتوانید به لینک زیر رجوع کنید:
منبع اصلی در این بخش، فصل 5 دوره آموزش LLM در سایت HuggingFace میباشد. جهت مطالعه بیشتر میتوانید به لینک مقابل رجوع کنید: مطالعه در HuggingFace
جستجوی معنایی چیست؟
برخلاف جستجوی سنتی که بر اساس تطابق کلمات کلیدی کار میکند، جستجوی معنایی بر اساس معنی و مفهوم متن عمل میکند. این نوع جستجو میتواند اسنادی را پیدا کند که از نظر معنایی شبیه پرسش ما هستند، حتی اگر کلمات یکسانی نداشته باشند.
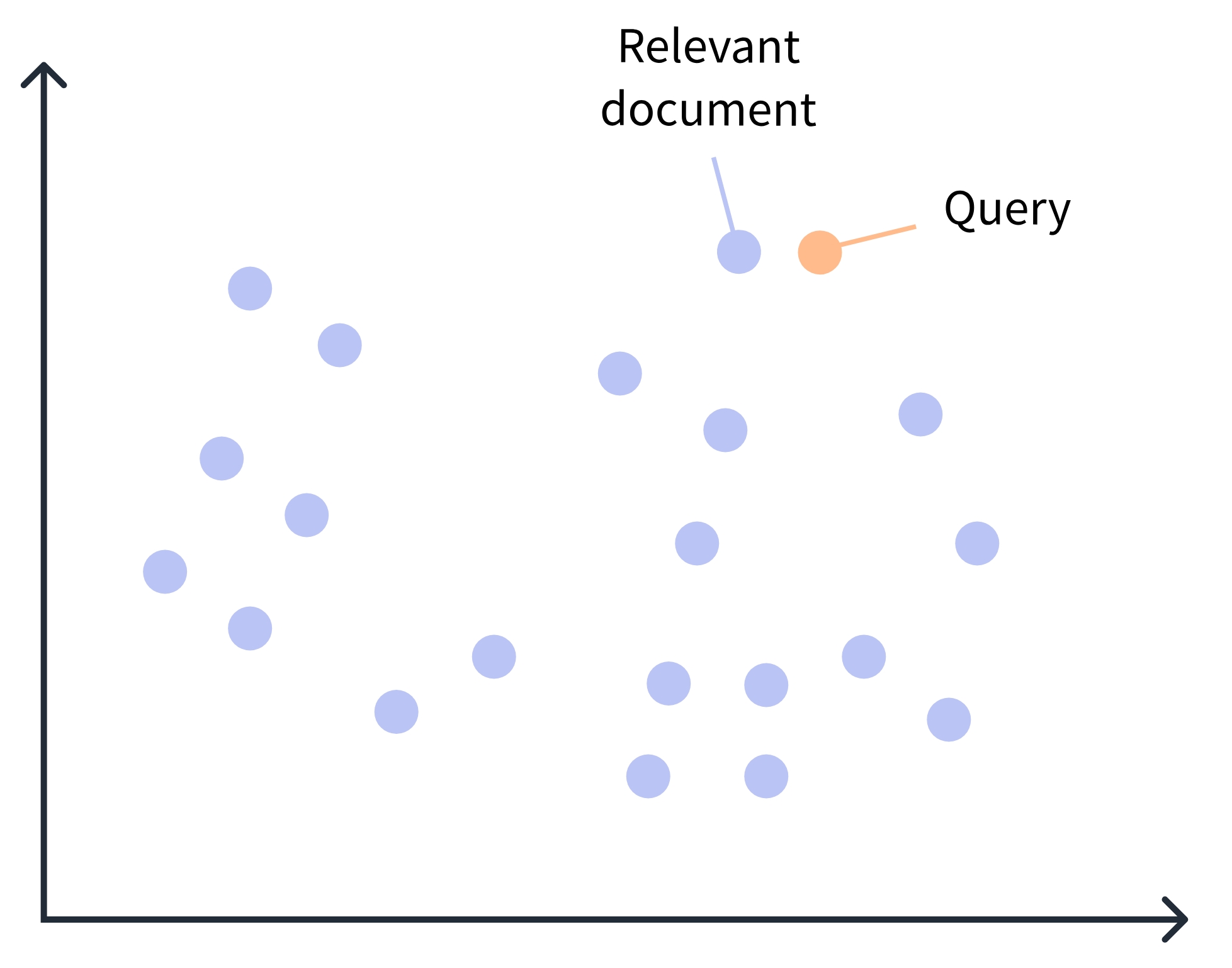
گام 1: بارگذاری و آمادهسازی داده
ابتدا دیتاست مورد نظر خود را بارگذاری میکنیم. در این مثال، از دیتاستی از GitHub issues استفاده میکنیم:
from datasets import load_dataset
# Loading and preparing the dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
print(issues_dataset)
خروجی:
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url',
'events_url', 'html_url', 'id', 'node_id', 'number',
'title', 'user', 'labels', 'state', 'locked', 'assignee',
'assignees', 'milestone', 'comments', 'created_at',
'updated_at', 'closed_at', 'author_association',
'active_lock_reason', 'pull_request', 'body',
'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
فیلتر کردن دادهها
حالا باید Pull Request ها و issue های بدون کامنت را حذف کنیم:
# Remove Pull Requests and items without comments
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
print(issues_dataset)
خروجی:
Dataset({
features: [...],
num_rows: 771
})
انتخاب ستونهای مورد نیاز
فقط ستونهایی که برای موتور جستجو نیاز داریم را نگه میداریم:
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
print(issues_dataset)
گام 2: تبدیل کامنتها به سطرهای جداگانه
هر issue ممکن است چندین کامنت داشته باشد. ما نیاز داریم هر کامنت را به یک سطر جداگانه تبدیل کنیم:
# Convert to Pandas format
issues_dataset.set_format("pandas")
df = issues_dataset[:]
استفاده از explode برای جدا کردن کامنتها
# Separate comments into separate lines
comments_df = df.explode("comments", ignore_index=True)
print(comments_df.head(4))
تبدیل به Dataset
from datasets import Dataset
comments_dataset = Dataset.from_pandas(comments_df)
print(comments_dataset)
خروجی:
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 2842
})
گام 3: فیلتر کردن کامنتهای کوتاه
کامنتهای خیلی کوتاه (مثل “Thanks!” یا “cc @user”) معمولاً اطلاعات مفیدی ندارند:
# Add comment length column
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)
# Remove comments shorter than 15 words
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
print(comments_dataset)
ترکیب متنها
برای ایجاد embedding بهتر، title، body و comments را با هم ترکیب میکنیم:
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text)
گام 4: ایجاد Embedding های متنی
حالا باید هر متن را به یک بردار عددی تبدیل کنیم. برای این کار از مدلهای sentence-transformers استفاده میکنیم:
from transformers import AutoTokenizer, AutoModel
import torch
# Choosing the right model for semantic search
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
# Transfer model to GPU (if available)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
تابع CLS Pooling
برای تبدیل token embedding ها به یک بردار واحد، از CLS pooling استفاده میکنیم:
def cls_pooling(model_output):
"""Extract embedding from token [CLS]"""
return model_output.last_hidden_state[:, 0]
تابع دریافت Embedding
def get_embeddings(text_list):
"""Convert a list of texts to embedding"""
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)
# Function test
embedding = get_embeddings(comments_dataset["text"][0])
print(f"embedding shape: {embedding.shape}") # torch.Size([1, 768])
ایجاد Embedding برای تمام دادهها
embeddings_dataset = comments_dataset.map(
lambda x: {
"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]
}
)
گام 5: ایجاد Index با FAISS
حالا که embedding ها را داریم، باید یک index بسازیم تا بتوانیم به سرعت جستجو کنیم:
# Create FAISS index
embeddings_dataset.add_faiss_index(column="embeddings")
گام 6: جستجو در دادهها
حالا میتوانیم سوال خود را بپرسیم و نزدیکترین پاسخها را پیدا کنیم:
# Define your question
question = "How can I load a dataset offline?"
# Convert question to embedding
question_embedding = get_embeddings([question]).cpu().detach().numpy()
print(f"Question embedding shape: {question_embedding.shape}")
# Search the dataset
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)
نمایش نتایج
import pandas as pd
# Convert results to DataFrame
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)
# Show best results
for _, row in samples_df.iterrows():
print(f"Comment: {row.comments[:200]}...")
print(f"Score: {row.scores}")
print(f"Title: {row.title}")
print(f"Link: {row.html_url}")
print("=" * 70)
کد کامل
در اینجا کد کامل برای ایجاد یک موتور جستجوی معنایی آورده شده است:
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
import torch
import pandas as pd
# 1. Loading and preparing the dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
# 2. Select the required columns
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
# 3. Separate comments
issues_dataset.set_format("pandas")
df = issues_dataset[:]
comments_df = df.explode("comments", ignore_index=True)
comments_dataset = Dataset.from_pandas(comments_df)
# 4. Filter and combine texts
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text)
# 5. Model preparation
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 6. Helper functions
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)
# 7. Create embeddings
embeddings_dataset = comments_dataset.map(
lambda x: {
"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]
}
)
# 8. Create FAISS index
embeddings_dataset.add_faiss_index(column="embeddings")
# 9. Search
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)
# 10. Show results
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)
for _, row in samples_df.iterrows():
print(f"Comment: {row.comments[:200]}...")
print(f"Score: {row.scores}")
print(f"Title: {row.title}")
print(f"Link: {row.html_url}")
print("=" * 70)
خروجی:
"""
COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
SCORE: 25.505046844482422
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
You can now use them offline
\`\`\`python
datasets = load_dataset("text", data_files=data_files)
\`\`\`
We'll do a new release soon
SCORE: 24.555509567260742
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
----------
> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
\`\`\`python
load_dataset("./my_dataset")
\`\`\`
and the dataset script will generate your dataset once and for all.
----------
About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
cf #1724
SCORE: 24.14896583557129
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
>
> 1. (online machine)
>
> ```
>
> import datasets
>
> data = datasets.load_dataset(...)
>
> data.save_to_disk(/YOUR/DATASET/DIR)
>
> ```
>
> 2. copy the dir from online to the offline machine
>
> 3. (offline machine)
>
> ```
>
> import datasets
>
> data = datasets.load_from_disk(/SAVED/DATA/DIR)
>
> ```
>
>
>
> HTH.
SCORE: 22.893993377685547
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
1. (online machine)
\`\`\`
import datasets
data = datasets.load_dataset(...)
data.save_to_disk(/YOUR/DATASET/DIR)
\`\`\`
2. copy the dir from online to the offline machine
3. (offline machine)
\`\`\`
import datasets
data = datasets.load_from_disk(/SAVED/DATA/DIR)
\`\`\`
HTH.
SCORE: 22.406635284423828
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
"""
جمعبندی
در این مقاله، خوشهبندی متن را از مبانی نظری تا پیادهسازی عملی بررسی کردیم. ما با تعریف این حوزه و چالشهای کلاسیک آن آغاز کردیم، سپس نحوه نمایش مدرن متن با استفاده از Embeddings را تشریح نمودیم و در ادامه، به کتابخانه FAISS به عنوان موتور محاسباتی برای پردازش بردارها در مقیاس بزرگ پرداختیم. مثال عملی ما نشان داد که این دو فناوری چگونه در کنار هم میتوانند ساختارهای معنایی پنهان در متون را آشکار سازند.
بینش کلیدی که از این بررسی به دست میآید، این است که ترکیب Embeddings معنایی با کتابخانههای جستجوی سریع شباهت مانند FAISS، پارادایم خوشهبندی متن را متحول کرده است. این رویکرد به ما اجازه میدهد تا از تطبیق کلمات کلیدی سطحی فراتر رفته و به درک عمیق مفهوم و محتوای متون، حتی در مقیاسهای بسیار بزرگ، دست یابیم.
با وجود اینکه مثال ساختگی ما پتانسیل بالای این روش را نشان داد، باید توجه داشت که دادههای دنیای واقعی پیچیده و نویزدار هستند. چالشهای آینده شامل بهبود مدلهای Embedding برای درک بهتر زمینههای پیچیده، توسعه الگوریتمهای خوشهبندی که با اشکال غیرکروی بهتر کار میکنند، و ایجاد روشهای خودکار برای تفسیر و برچسبگذاری خوشههای تولید شده است.
در نهایت، FAISS و مدلهای Embedding مدرن صرفاً ابزارهایی نیستند، بلکه بلوکهای سازندهای بنیادین برای نسل آینده سیستمهای تحلیل متن هوشمند محسوب میشوند.
منابع
- FAISS Documentation
- Semantic Search with FAISS
- An Introduction to Bag of Words (BoW)
- Introduction to Natural Language Processing — TF-IDF
- Text Clustering Using Deep Learning Language Models
- Wikimedia – K-means_convergence.gif
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- Agglomerative Clustering with Graph
- Part 2: Understanding and Using FAISS — Exploring FAISS Index Types with Practical Examples for Reading and Writing
- Hierarchical Navigable Small Worlds (HNSW) [Pinecone]
- What is Silhouette Score? [geeksforgeek]