
نویسنده: محمدرضا باباگلی
ايميل: MohammadRezaBabagoli.AI@gmail.com
دانشجوی ارشد هوشمصنوعی دانشگاه فردوسی مشهد
آزمایشگاه شناسایی الگو دکتر هادی صدوقی یزدی
راهنمای گردشگر - Tourist Assistant

مقدمه
دستیار پیشنهاددهندهی سفر برای گردشگران:
هدف، طراحی سیستمی است که کاربر در آن ویژگیها و معیارهای موردنظر خود برای مقصد سفر را وارد میکند؛ سپس سیستم بر اساس این اطلاعات، مناسبترین شهرها را پیدا کرده و گزینههای مرتبط را به او پیشنهاد میدهد.
ابزارهای مورد استفاده
- LangChain: برای ساخت موتور جستجو
مستندات LangChain: LangChain Documentation -
Google Gemini: برای ساخت embeddingها ازطریق API
دریافت API KEY برای GEMINI - FAISS: برای ذخیره سازی indexها و انجام عمل جستجو کتابخانه FAISS که توسط Facebook AI Research توسعه یافته است، یک ابزار قدرتمند و بهینه برای جستوجوی شباهت و بازیابی بردارها در مقیاس بزرگ محسوب میشود. این کتابخانه با بهرهگیری از ساختارهای داده و الگوریتمهای پیشرفته، امکان اجرای جستوجوی تقریبی یا دقیق بر روی میلیونها تا میلیاردها بردار را با سرعت و کارایی بالا فراهم میکند و بهویژه در سامانههای توصیهگر، جستوجوی معنایی و کاربردهای مرتبط با هوش مصنوعی و یادگیری عمیق مورد استفاده قرار میگیرد.
خوشهبندی متن با ابزار FAISS
- Streamlit: رابط کاربری کتابخانه Streamlit یک فریمورک متنباز در پایتون است که امکان توسعهی سریع و کارآمد برنامههای تعاملی تحت وب را، بهویژه برای پروژههای دادهمحور و یادگیری ماشین، فراهم میسازد. این کتابخانه با حداقل کدنویسی و بدون نیاز به دانش فناوریهای وب، امکان ایجاد داشبوردها و رابطهای کاربری کاربردی و حرفهای را مهیا میکند.
آموزش Streamlit
مجموعه دادهها
اطلاعات شهرها را در فایل اکسلی با نام city_data.xlsx ذخیره میکنیم.
این فایل شامل دو ستون به نامهای زیر است:
city_name: نام شهرdescription: توضیحات جامعی از شهر

ساختار مجموعهداده - شامل دو ستون: نام شهر و توضیحات شهر
همچنین برای هر شهر، تصاویر چند مکان توریستی آن شهر در پوشههای مربوطه ذخیره میشود.
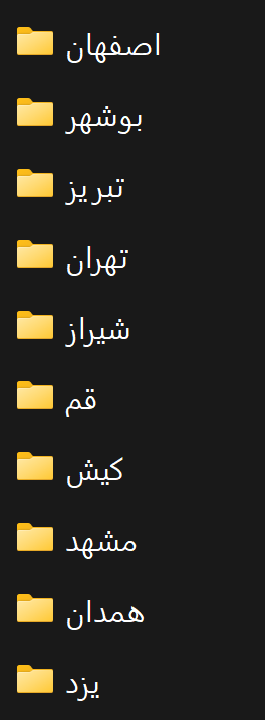
به ازای هر شهر، یک پوشه ایجاد میکنیم.
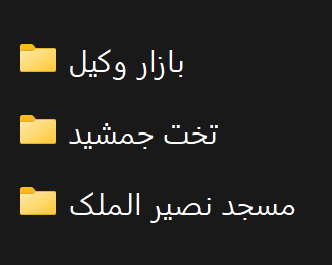
در شهر(مثلا شیراز)، برای هر مکان دیدنی پوشه در نظر میگیریم.
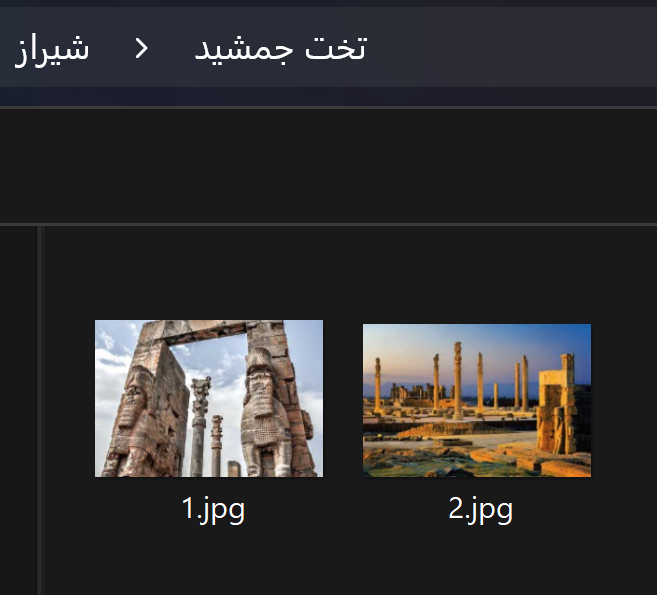
در هر پوشه برای مکان دیدنی، تصاویر مربوط به آن مکان را ذخیره میکنیم. (مثلا تخت جمشید)
معماری سیستم
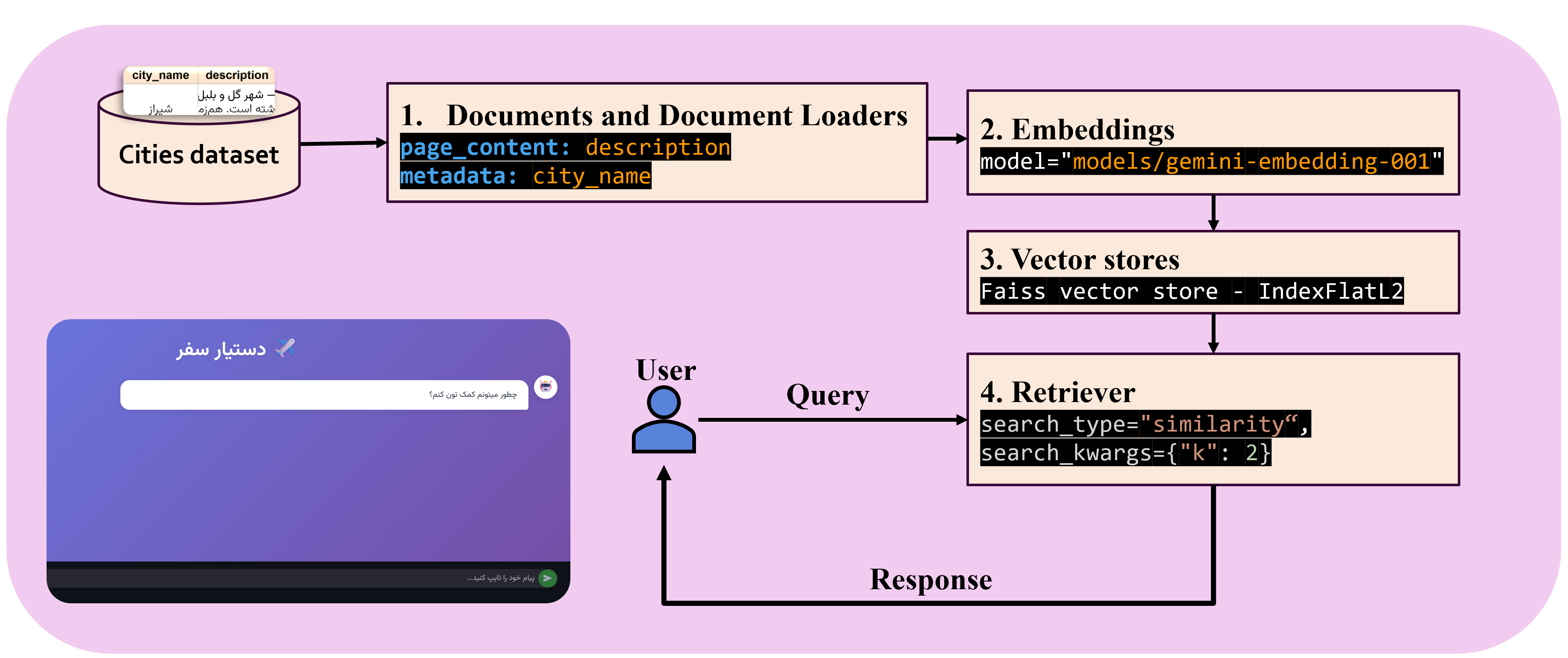
معماری سیستم
بخشهای اصلی برنامه
چهار بخش اصلی برنامه عبارت اند از:
1. Documents and Document Loaders
در این بخش، اطلاعات مجموعهداده اکسل خود را بارگزاری کرده و به نوع Document در LangChain تبدیل میکنیم. به همراه توضیحات هر شهر، متادیتا آن (نام شهر) را نیز ذخیره میکنیم، زیرا در هنگام بازیابی تصاویر مکانهای آن شهر کاربرد دارد.
#----1. Documents and Document Loaders----#
city_data = pd.read_excel("city_data.xlsx")
documents = []
print("Building Langchain Document")
for i, row in city_data.iterrows():
city_name = row['city_name']
city_description = row['description']
doc = Document(
page_content=city_description,
metadata={"city_name": city_name},
)
documents.append(doc)
2. Embeddings
ابتدا یک فایل با پسوند .env در مسیر برنامه ایجاد کنید، و کلید API خود را مانند تصویر زیر در آن قرار دهید.
محتویات فایل `.env`
در این بخش، ابتدا API KEY موجود در فایل .env بارگزاری میشود،
اگر API KEY بهدرستی بارگزاری نشود، در ابتدا اجرای برنامه میتوانید API KEY خود را وارد کنید.
زماني كه API KEY بارگزاری شد، مدل embedding فراخوانی میشود.
#-----2. Embeddings------#
print("Step 2. Embeddings")
load_dotenv()
if not os.environ.get("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter API key for Google Gemini: ")
print("API KEY Loaded.")
embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")
print("Embedding model loaded: gemini-embedding-001")
3. Vector stores
در این بخش، نوبت به ساخت index میرسد، از FAISS براس ساخت index از نوع FlatL2 استفاده میکنیم.
همچنین شما میتوانید انوع دیگری از vector store را انتخاب کنید:
انواع مختلف vector store
#----3. Vector stores----#
print("Step 3. Vector stores")
embedding_dim = len(embeddings.embed_query("hello world"))
index = faiss.IndexFlatL2(embedding_dim)
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
ids = vector_store.add_documents(documents=documents)
نکته: در صورتی که مجموعهداده شما تغییر نمیکند، بهتر است زمانی که یکبار vector store ایجاد کردید، آن را با دستور زیر در سیستم خود ذخیره کنید تا در دفعات بعد نیاز به ساخت مجدد vector store تکراری نباشد. این کار باعث صرفهجویی در هزینه و زمان شما میشود.
نحوه ذخیره vector store:
# Save to disk
vector_store.save_local("city_data_faiss_index")
با اجرای این دستور، یک پوشه شامل دو فایل به نامهای index.faiss و index.pkl ایجاد میشود.
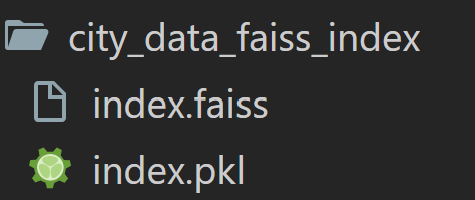
ذخیره vector store
نحوه بارگزاری مجدد vector store:
# Load from disk later
loaded_store = FAISS.load_local("city_data_faiss_index", embeddings, allow_dangerous_deserialization=True)
4. Retriever
در Retriever ،LangChain ماژولی است که بر اساس پرسش کاربر، مرتبط ترین اسناد یا بخشهای اطلاعات را از یک منبع داده بازیابی میکند.
در این بخش مشخص میکنیم عمل بازیابی چگونه انجام شود، همچنین مشخص میکنیم تعداد چند سند مشابه بازگشت داده شوند.
#----4. Retriever----#
print("Step 4. Retriever")
retriever = loaded_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 2},
)
search_type="similarity":
یعنی روش بازیابی شباهت برداری (vector similarity) استفاده شود — یعنی اسنادی پیدا میشوند که embedding آنها از نظر «شبیه بودن» به embedding پرسش (query) نزدیک باشد.
انواع ممکن برای search_type:
1. "similarity":
همان «جستجوی مبتنی بر شباهت برداری» (بردار embedding پرسش و اسناد).
در این نوع جستجو، مراحل زیر انجام میشود:
-
تبدیل پرسش به بردار embedding ابتدا پرسش کاربر با مدل embedding به یک بردار عددی تبدیل میشود.
-
مقایسه بردار پرسش با بردارهای اسناد این بردار پرسش با تمام بردارهای ذخیره شده در vector store مقایسه میشود تا شباهت محاسبه شود. معیارهای معمول برای شباهت برداری عبارتاند از:
- cosine similarity (عمومیترین معیار شباهت)،
- inner product،
- dot product یا euclidean distance
-
مرتبسازی اسناد بر اساس بیشترین شباهت بر اساس مقدار شباهت محاسبهشده، اسناد را رتبهبندی میکند.
-
بازگرداندن بهترین نتایج
kعدد از بالاترین نتایج را بازمیگرداند که درsearch_kwargs={"k": 2}تعیین میشوند (در مثال ۲ سند).
معیار شباهت در عمل، معیار شباهت به شما میگوید چقدر دو بردار همجهت یا مشابه هستند:
● Cosine similarity (رایجترین)
این معیار براساس زاویه بین دو بردار محاسبه میشود:
- مقدار +1 یعنی کاملاً مشابه؛
- مقدار 0 یعنی بیارتباط؛
- مقدار -1 یعنی مخالف مفهوم.
پایگاههای برداری (مثل FAISS، Weaviate، Milvus، Typesense و…) معمولاً همین معیار را برای شباهت سند/پرسش استفاده میکنند.
2. "mmr":
جستجوی مبتنی بر Maximal Marginal Relevance: یعنی اسنادی انتخاب میشوند که هم به پرسش شبیهاند، هم نسبت به هم تنوع دارند؛ مناسب وقتی مجموعهٔ اسناد خیلی شبیه به هم هستند و میخواهیم نتایج متنوعتر بگیریم.
هدف این روش این است که همزمان دو چیز را بهینه کند:
- ارتباط با سوال (relevance) — مثل جستجوی شباهت معمولی
- تنوع نتایج (diversity) — یعنی نتایجی که از نظر محتوایی با هم خیلی مشابه نباشند یا اطلاعات تکراری ندهند
بهعبارت دیگر، MMR تلاش میکند تا:
- نتایجی انتخاب کند که هم نزدیک به پرسش باشند،
- و هم از هر نظر قرار گرفتن چند نتیجه خیلی شبیه به هم در خروجی را کاهش دهد.
چطور MMR کار میکند؟
فرض کنید از یک پایگاه برداری (Vector Store) مثل FAISS یا Milvus استفاده میکنید.
۱) ابتدا یک مجموعهٔ اولیه از نتایج میگیرید (مثلاً با fetch_k)
۲) سپس الگوریتم MMR بهصورت تکراری بهترین سند را انتخاب میکند:
توضیحات
- $\text{MMR}(D_i)$: امتیاز ارتباط حاشیهای بیشینه برای سند $D_i$.
- $\arg\max$: آرگومانی که بیشترین مقدار را میدهد (ورودی تابع که بیشینه خروجی را تولید میکند).
- $D_i \in R \setminus S$: اسناد کاندیدا که در مجموعه $R$ (تمام اسناد) قرار دارند اما در مجموعه $S$ (اسناد انتخاب شده) نیستند.
- $\lambda$ (لامبدا): پارامتر تعادل بین ارتباط و تنوع (۰ ≤ $\lambda$ ≤ ۱).
- $\text{Sim}(D_i, Q)$: شباهت بین سند $D_i$ و پرسمان $Q$.
- $\max_{D_j \in S} \text{Sim}(D_i, D_j)$: بیشترین شباهت بین سند $D_i$ و هر سند $D_j$ در مجموعه انتخاب شده $S$.
مراحل
۱. محاسبه امتیاز ارتباط: محاسبه $\text{Sim}(D_i, Q)$ برای هر سند کاندید $D_i$ نسبت به پرسمان $Q$. ۲. محاسبه امتیاز تنوع: محاسبه $\max_{D_j \in S} \text{Sim}(D_i, D_j)$ برای هر سند کاندید $D_i$ نسبت به اسناد انتخاب شده $S$. ۳. محاسبه امتیاز MMR: محاسبه $\lambda \cdot \text{Sim}(D_i, Q) - (1 - \lambda) \cdot \max_{D_j \in S} \text{Sim}(D_i, D_j)$. ۴. انتخاب سند: انتخاب سند $D_i$ که بالاترین امتیاز MMR را دارد و افزودن آن به مجموعه انتخاب شده $S$.
در این فرمول، MMR در واقع قانون انتخاب آیتم بعدی را تعریف میکند، نه صرفاً یک نمرهی ساده. خروجی آن سند (D_i)ای است که در هر گام الگوریتم باید به مجموعه انتخابشده اضافه شود.
ابتدا مجموعهها را مشخص کنیم. (R) مجموعهی کل اسناد کاندیداست (مثلاً top-k اسنادی که با retrieval اولیه بهدست آمدهاند). (S) مجموعهی اسنادی است که تا این لحظه انتخاب شدهاند. پس $(R \setminus S)$ یعنی اسنادی که هنوز انتخاب نشدهاند و در این گام کاندیدای انتخاب هستند.
عبارت $(\arg\max)$ یعنی «آن $(D_i)$ای را انتخاب کن که مقدار داخل کروشه برایش بیشینه است». بنابراین MMR میگوید در این مرحله، کدام سند باید انتخاب شود.
بخش اول عبارت داخل کروشه:
\[\lambda \cdot \text{Sim}(D_i, Q)\]این بخش ارتباط با پرسش را اندازه میگیرد. $(\text{Sim}(D_i, Q))$ میزان شباهت سند $(D_i)$ با کوئری (Q) است (اغلب cosine similarity بین embeddingها). ضریب $(\lambda)$ وزن این مؤلفه را تعیین میکند. هرچه $(\lambda)$ بزرگتر باشد، الگوریتم بیشتر به مرتبطبودن با کوئری اهمیت میدهد.
بخش دوم:
\[(1 - \lambda) \cdot \max_{D_j \in S} \text{Sim}(D_i, D_j)\]این بخش جریمهی افزونگی (redundancy penalty) است. برای سند کاندیدای $(D_i)$، شباهت آن با تکتک اسناد انتخابشده در (S) محاسبه میشود و سپس بیشترین آنها گرفته میشود. دلیل استفاده از $(\max)$ این است که اگر $(D_i)$ حتی با یکی از اسناد انتخابشده بسیار شبیه باشد، تکراری محسوب میشود و باید جریمه شود.
ضریب $((1 - \lambda))$ وزن این جریمه را کنترل میکند. هرچه $(\lambda)$ کوچکتر باشد، این جریمه قویتر میشود و تنوع اهمیت بیشتری پیدا میکند.
علامت منفی بین دو بخش بسیار مهم است. این منفی به این معناست که:
- شباهت به کوئری امتیاز مثبت است.
- شباهت به اسناد قبلی امتیاز منفی (جریمه) است.
تعبیر شهودی فرمول این است: «سندی را انتخاب کن که تا حد ممکن به کوئری شبیه باشد، اما تا حد ممکن با اسنادی که قبلاً انتخاب شدهاند متفاوت باشد.»
نکتهی مهم دیگر این است که رفتار فرمول به وضعیت (S) بستگی دارد. در گام اول که (S) تهی است، جملهی دوم عملاً وجود ندارد و انتخاب فقط بر اساس $(\text{Sim}(D_i, Q))$ انجام میشود. به همین دلیل اولین سند همیشه مرتبطترین سند با کوئری است. از گام دوم به بعد، تنوع وارد تصمیمگیری میشود.
در نهایت، این فرمول یک سازوکار greedy تعریف میکند: در هر مرحله بهترین انتخاب محلی انجام میشود، با این هدف که مجموعهی نهایی هم مرتبط و هم متنوع باشد، بدون تضمین بهینگی سراسری، اما با عملکرد عملی بسیار خوب در سیستمهای بازیابی و RAG.
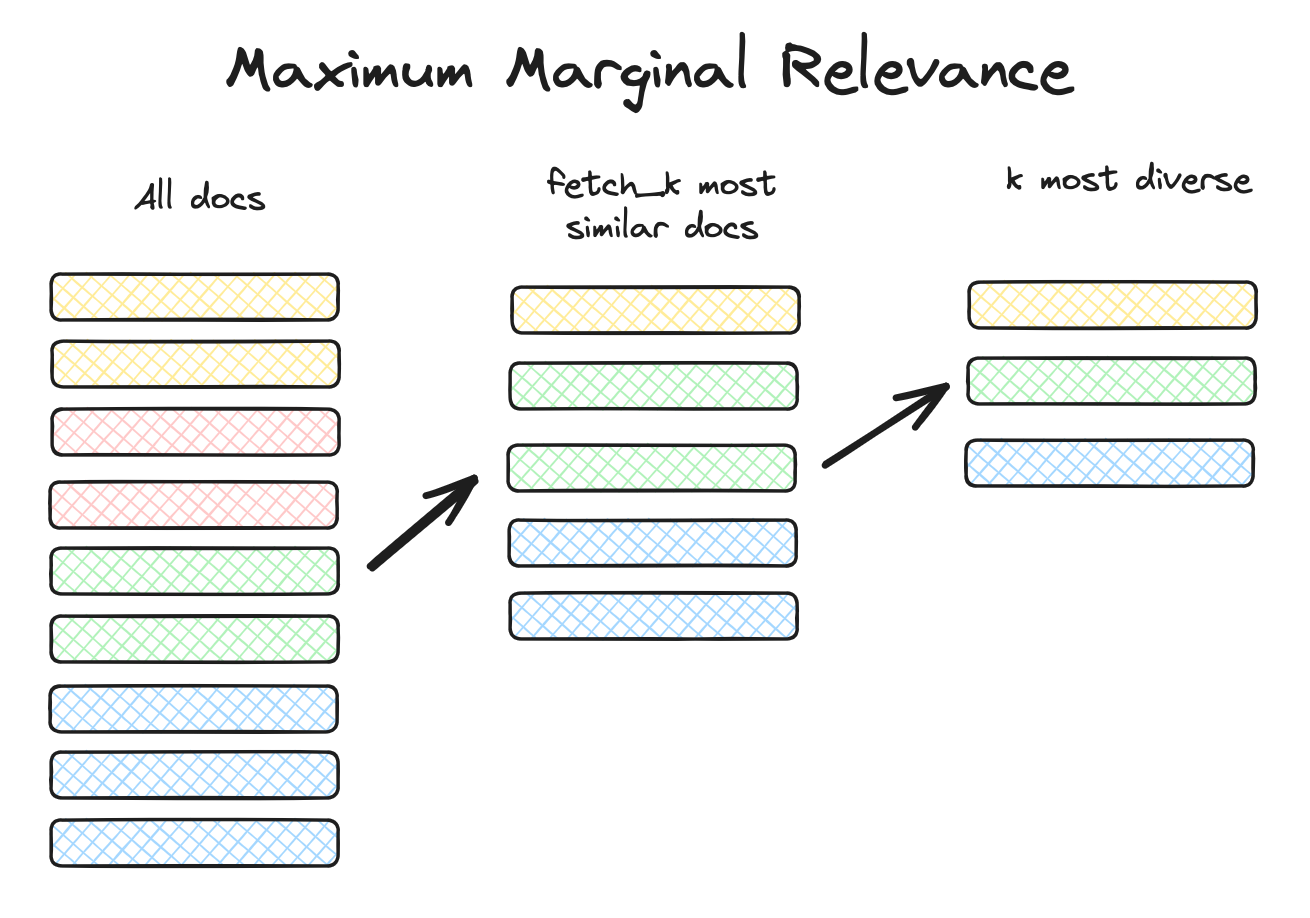
Maximum Marginal Relevance (MMR)
برای هر انتخاب:
امتیاز نهایی سند D_i برابر است با:
λ * sim(query, D_i) - (1 - λ) * max(sim(D_i, selected_docs))
که در آن:
sim(query, D_i)نشاندهنده شباهت سند به پرسش استsim(D_i, selected_docs)نشاندهنده شباهت با اسنادی است که قبلاً انتخاب شدهاندλ(lambda_mult) عددی بین 0 و 1 است که میزان اولویت بین شباهت و تنوع را تعیین میکند
نقش پارامترهای مهم در search_kwargs
پارامترهایی که میتوانید برای MMR تنظیم کنید عبارتاند از:
ستون آخر جدول حذف شد:
| پارامتر | معنای تخصصی |
|---|---|
| k | تعداد نهایی اسنادی که میخواهید خروجی داده شود |
| fetch_k | تعداد اولیه اسناد که قبل از اعمال الگوریتم MMR بازیابی میشوند (حوضه انتخاب) |
| lambda_mult (یا lambda) | وزن ارتباط با پرسش در مقابل تنوع: ● نزدیک به 1 → تمرکز بیشتر روی شباهت ● نزدیک به 0 → تمرکز بیشتر روی تنوع |
مثال:
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 5, "fetch_k": 20, "lambda_mult": 0.5},
)
یعنی:
- از ابتدا ۲۰ سند مشابه سؤال گرفته میشود
- سپس ۵ مورد از بین آنها انتخاب میشود
- طوری که نسبت تعادل بین ارتباط و تنوع برابر ۰٫۵ باشد.
● RAG: MMR Search in LangChain (Kaggle)
● Maximal Marginal Relevance to Re-rank results in Unsupervised KeyPhrase Extraction (Medium)
● Diversifying search results with Maximum Marginal Relevance (elastic search labs)
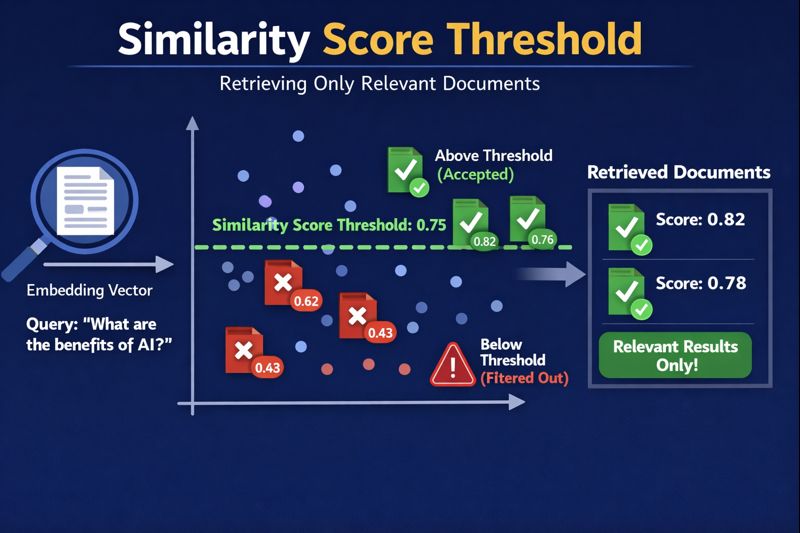
3. "similarity_score_threshold":
جستجو با آستانهٔ شباهت: فقط اسنادی برگردانده میشوند که شباهتشان نسبت به پرسش بالاتر از یک آستانه (threshold) مشخص باشد.
در LangChain وقتی search_type="similarity_score_threshold" را برای retriever انتخاب میکنید، الگوریتم بازیابی اسناد از بردارها نه فقط براساس شباهت (مثل حالت “similarity”) بلکه با فیلتر کردن نتایج بر اساس یک آستانهٔ حداقل شباهت (similarity score) انجام میشود. یعنی نتایجی که از نظر معنایی یا برداری به اندازه کافی نزدیک به پرسش نباشند، اصلاً بازگردانده نمیشوند.
مفهوم و هدف “similarity_score_threshold”
در جستجوی معمولی «similarity»، همیشه k تعداد سند را برمیگرداند — حتی اگر خیلی کم به پرسش مرتبط باشند.
اما در similarity_score_threshold:
به retriever میگویید:
- فقط اسنادی را برگردان که score (امتیاز شباهت) ≥ یک عدد مشخص (threshold) باشند.
- اگر هیچ سندی نتواند این شرط را برآورده کند، خروجی ممکن است خالی شود.
این روش زمانی خیلی مفید است که:
- میخواهید فقط اسناد واقعاً مرتبط برگردند،
- نمیخواهید جوابهای ضعیف یا کمربط وارد RAG شوند،
- یا پاسخ باید استاندارد کیفیت بالایی داشته باشد بدون نویز ضعیف.
نحوه عملکرد:
وقتی از این نوع استفاده میکنید، LangChain در پشت صحنه چنین کاری انجام میدهد:
- شباهت برای همهٔ اسناد محاسبه میشود — مانند حالت “similarity”.
- یک لیست از (doc, similarity_score) برگردان میشود.
- سپس لیست را فیلتر میکند فقط بر اساس
score >= score_threshold. - تنها اسناد باقیمانده را به عنوان خروجی retriever تحویل میدهد.
نکته:
score_thresholdباید عددی float بین 0 تا 1 باشد و بدون آن خطا میدهد.
پارامترهای مهم
| پارامتر | معنی |
|---|---|
| score_threshold | حداقل مقدار شباهت لازم برای پذیرش سند. برای مثال: 0.8 یعنی فقط اسناد با شباهت ≥ 0.8 برگشت داده شود. |
| k (اختیاری) | حداکثر تعداد سند قبل از فیلتر یا همراه با فیلتر — بسته به پیادهسازی DB |
مثال:
retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.75, "k": 10}
)
این یعنی:
- ابتدا تا ۱۰ سند شباهت بالا را پیدا کن
- سپس فقط آنها را نگه دار که similarity ≥ 0.75 باشند.
Similarity Score Threshold
search_kwargs={"k": 2}:
یعنی «دو» سند برتر (دو Document) بازگردانده شوند.
اگر k مشخص نشود، مقدار آن بهطور پیش فرض 4 است.
نحوه استفاده از Retriever برای بازیابی اسناد مشابه به درخواست کاربر:
chatbot_response = retriever.batch(
[
user_input
],
)
نحوه اجرا
اکنون در VS Code، یک Terminal در مسیری که فایل برنامه قرار دارد ایجاد کنید (Terminal → New Terminal)، و دستور زیر را وارد کنید.
>Streamlit run filename.py
در قسمت filename.py نام برنامه خود را وارد کنید.
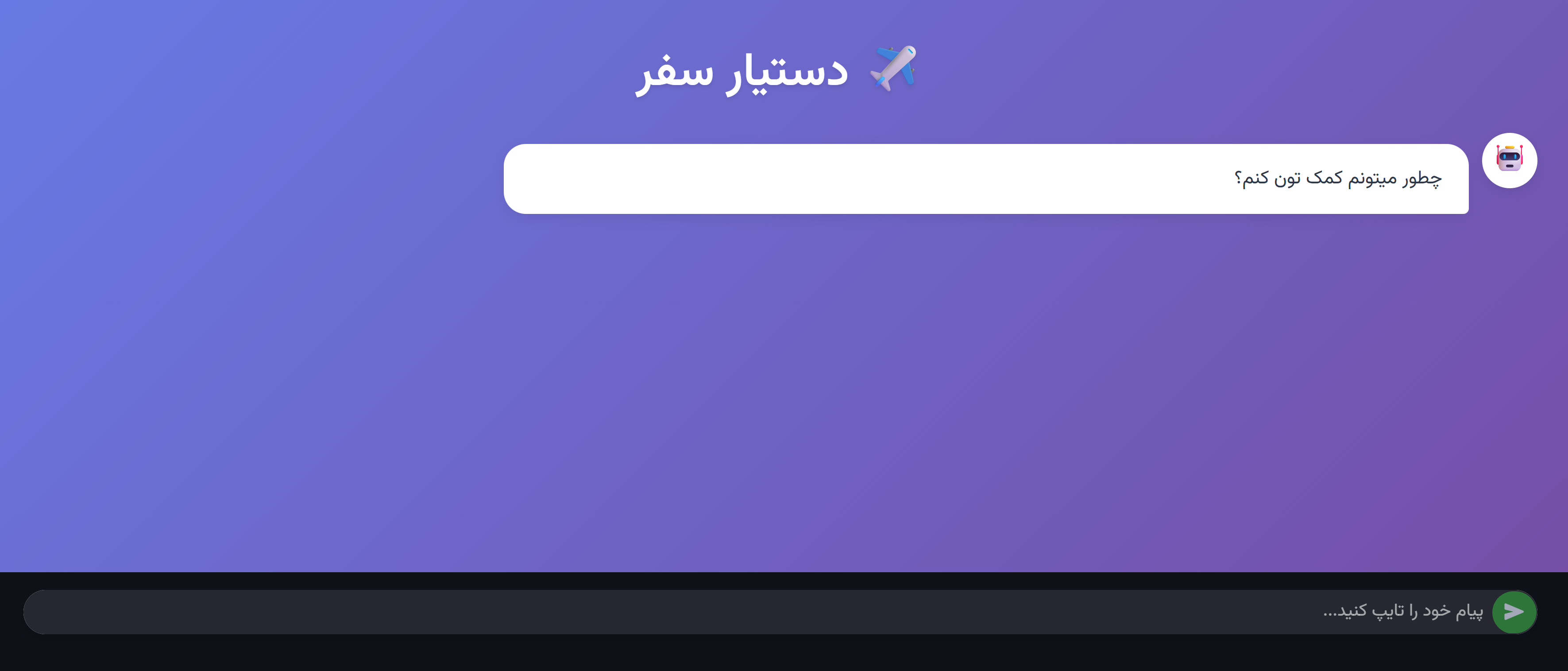
اگر برنامه بهدرستی و بدون خطا اجرا شود خروجی زیر را مشاهده میکنید:
کد تمام برنامه
import streamlit as st
import pandas as pd
from langchain_core.documents import Document
import getpass
from dotenv import load_dotenv
import os
from langchain_google_genai import GoogleGenerativeAIEmbeddings
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
#-------------------------------------------------
# Page config
st.set_page_config(page_title="چت بات سفر", layout="wide", initial_sidebar_state="collapsed")
# Custom CSS for styling
st.markdown("""
<style>
@import url('https://fonts.googleapis.com/css2?family=Vazirmatn:wght@400;500;600;700;800&display=swap');
@font-face {
font-family: 'Vazirmatn';
font-weight: normal;
font-style: normal;
}
* {
font-family: 'Vazirmatn', 'Inter', sans-serif;
}
/* Keep English text left-to-right */
.stChatInput input {
direction: rtl;
text-align: right;
}
.stApp {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
}
.main {
background: transparent;
}
.chat-container {
max-width: 900px;
margin: 0 auto;
padding: 20px;
}
.user-message {
background: #C8EDA9;
color: black;
border: none;
border-radius: 20px 20px 5px 20px;
padding: 18px 24px;
margin: 10px -60px;
font-size: 17px;
max-width: 70%;
box-shadow: 0 8px 16px rgba(102, 126, 234, 0.25);
line-height: 1.6;
margin-left: auto;
direction: rtl;
text-align: right;
}
.bot-message {
background: white;
color: #2d3748;
border: none;
border-radius: 20px 20px 5px 20px;
padding: 18px 24px;
margin: 10px -60px;
font-size: 17px;
max-width: 70%;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.08);
line-height: 1.6;
margin-left: auto;
direction: rtl;
text-align: right;
}
.bot-message-title {
background: linear-gradient(135deg, #f093fb 0%, #6c9e72 100%);
color: white;
border: none;
border-radius: 20px 20px 5px 20px;
padding: 18px 24px;
margin: 10px -60px;
font-size: 20px;
font-weight: bold;
max-width: 70%;
box-shadow: 0 8px 16px rgba(245, 87, 108, 0.25);
margin-left: auto;
direction: rtl;
text-align: right;
display: inline-block;
}
.bot-message-images {
background: #8ae6ab;
color: #2d3748;
border: none;
border-radius: 20px 20px 5px 20px;
padding: 18px 24px;
margin: 10px -60px;
font-size: 20px;
font-weight: bold;
max-width: 70%;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.08);
margin-left: auto;
direction: rtl;
text-align: center;
}
.bot-message-titleimages {
background: #faca8e;
color: black;
border: none;
border-radius: 20px 20px 5px 20px;
padding: 18px 24px;
margin: 10px -60px;
font-size: 20px;
font-weight: bold;
max-width: 70%;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.08);
margin-left: auto;
direction: rtl;
text-align: center;
}
.user-icon {
width: 50px;
height: 50px;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
color: white;
font-size: 24px;
box-shadow: 0 4px 12px rgba(102, 126, 234, 0.4);
}
.bot-icon {
width: 50px;
height: 50px;
background: white;
border: none;
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
font-size: 24px;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);
}
.stChatMessage {
background-color: transparent !important;
}
.stChatInput {
background: white;
border-radius: 25px;
border: none;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);
}
.chat-header {
text-align: center;
color: white;
padding: 30px 0 20px 0;
font-size: 42px;
font-weight: 600;
text-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}
.image-grid {
display: grid;
grid-template-columns: repeat(4, 1fr);
gap: 10px;
margin-top: 12px;
direction: rtl;
}
.image-item {
border-radius: 12px;
overflow: hidden;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}
/* Fix image columns for RTL */
.stColumns {
direction: rtl;
}
.stColumn {
direction: rtl;
}
.camera-icon {
width: 45px;
height: 45px;
background: linear-gradient(135deg, #f093fb 0%, #57ccf5 100%);
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
font-size: 20px;
box-shadow: 0 4px 8px rgba(245, 87, 108, 0.3);
}
/* Smooth animations */
.user-message, .bot-message, .bot-message-title, .bot-message-images {
animation: slideIn 0.3s ease-out;
}
@keyframes slideIn {
from {
opacity: 0;
transform: translateY(10px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
/* Input styling */
.stChatInput > div > div {
background: #2e753a;
backdrop-filter: blur(10px);
border-radius: 30px;
}
.stChatInput {
background: white;
border-radius: 25px;
border: none;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);
}
input::placeholder,
textarea::placeholder {
font-family: 'Vazirmatn', sans-serif;
font-size: 16px;
color: #888;
opacity: 1;
}
input, textarea {
font-family: 'Vazirmatn', sans-serif !important;
text-align: right;
direction: rtl;
}
input::placeholder,
textarea::placeholder {
font-family: 'Vazirmatn', sans-serif !important;
text-align: right;
direction: rtl;
}
</style>
""", unsafe_allow_html=True)
#------------------------------------------------------
#-----------------------------------------#
#----1. Documents and Document Loaders----#
city_data = pd.read_excel("city_data.xlsx")
documents = []
print("Building Langchain Document")
for i, row in city_data.iterrows():
city_name = row['city_name']
city_description = row['description']
doc = Document(
page_content=city_description,
metadata={"city_name": city_name},
)
documents.append(doc)
print("Done.")
print("number of documents:", len(documents))
print("_"*40)
#------------------------#
#-----2. Embeddings------#
print("Step 2. Embeddings")
load_dotenv()
if not os.environ.get("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter API key for Google Gemini: ")
print("API key Loaded.")
embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")
print("Embedding model loaded: gemini-embedding-001")
#------------------------#
#----3. Vector stores----#
print("Step 3. Vector stores")
embedding_dim = len(embeddings.embed_query("hello world"))
index = faiss.IndexFlatL2(embedding_dim)
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
ids = vector_store.add_documents(documents=documents)
# Save to disk
vector_store.save_local("city_data_faiss_index")
#------------------------#
#----4. Retriever----#
print("Step 4. Retriever")
# Load from disk later
loaded_store = FAISS.load_local("city_data_faiss_index", embeddings, allow_dangerous_deserialization=True)
retriever = loaded_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 2},
)
#------------------------------------------------------
# Initialize session state
if 'messages' not in st.session_state:
st.session_state.messages = [
{"role": "assistant", "content": "چطور میتونم کمک تون کنم؟", "type": "text"}
]
def get_images(city_name):
"""
Returns:
A dictionary mapping place_name -> list_of_image_paths
"""
city_path = os.path.join("dataset", "cities", city_name)
if not os.path.isdir(city_path):
raise FileNotFoundError(f"City folder not found: {city_path}")
result = {}
# iterate over place folders
for place_name in os.listdir(city_path):
place_path = os.path.join(city_path, place_name)
if os.path.isdir(place_path):
# collect all image file paths in this place folder
images = [
os.path.join(place_path, f)
for f in os.listdir(place_path)
if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff'))
]
result[place_name] = images
return result
def get_city_recommendations():
"""Return default city recommendations"""
return [CITY_DATA["city1"], CITY_DATA["city2"]]
# Header
st.markdown('<div class="chat-header"> دستیار سفر ✈️ </div>', unsafe_allow_html=True)
# Display chat messages
for i, message in enumerate(st.session_state.messages):
if message["role"] == "user":
col1, col2 = st.columns([11, 1])
with col1:
st.markdown(f'<div class="user-message">{message["content"]}</div>', unsafe_allow_html=True)
with col2:
st.markdown('<div class="user-icon">👤</div>', unsafe_allow_html=True)
else:
col1, col2 = st.columns([11, 1])
with col1:
if message.get("type") == "images":
st.markdown(f'<div class="bot-message-images">{message["content"]}</div>', unsafe_allow_html=True)
if "images" in message:
cols = st.columns(4)
for idx, img_url in enumerate(message["images"][:3]):
with cols[idx]:
st.image(img_url, width='stretch')
with cols[3]:
pass
# st.markdown('<div class="camera-icon">📷</div>', unsafe_allow_html=True)
elif message.get("type") == "titleimages":
st.markdown(f'<div class="bot-message-titleimages">{message["content"]}</div>', unsafe_allow_html=True)
elif message.get("type") == "title":
st.markdown(f'<div class="bot-message-title">{message["content"]}</div>', unsafe_allow_html=True)
else:
st.markdown(f'<div class="bot-message">{message["content"]}</div>', unsafe_allow_html=True)
with col2:
st.markdown('<div class="bot-icon">🤖</div>', unsafe_allow_html=True)
# Chat input
st.markdown("<br>", unsafe_allow_html=True)
user_input = st.chat_input("پیام خود را تایپ کنید...")
if user_input:
chatbot_response = retriever.batch(
[
user_input
],
)
city1_description = chatbot_response[0][0].page_content
city1_name = chatbot_response[0][0].metadata["city_name"]
city2_description = chatbot_response[0][1].page_content
city2_name = chatbot_response[0][1].metadata["city_name"]
# City data
CITY_DATA = {
"city1": {
"name": city1_name,
"description": city1_description,
"popular_places_info": get_images(city1_name)
},
"city2": {
"name": city2_name,
"description": city2_description,
"popular_places_info": get_images(city2_name)
}
}
# Add user message
st.session_state.messages.append({"role": "user", "content": user_input})
# Get city recommendations
cities = get_city_recommendations()
# Add bot responses for each city
for idx, city in enumerate(cities, 1):
# City name
st.session_state.messages.append({
"role": "assistant",
"content": f"شهر شماره {idx}: {city['name']}",
"type": "title"
})
# City description
st.session_state.messages.append({
"role": "assistant",
"content": city['description'],
"type": "text"
})
st.session_state.messages.append({
"role": "assistant",
"content": f"برخی مکان های دیدنی {city['name']}",
"type": "titleimages"
})
for name, images in city['popular_places_info'].items():
# City images
st.session_state.messages.append({
"role": "assistant",
"content": f" تصاویر {name} 📷",
"type": "images",
"images": images
})
st.rerun()
print('end of running')
نمونه خروجی برنامه




خروجی برنامه برای ورودی "میخواهم به سفر زیارتی بروم، چند شهر پیشنهاد بده."




خروجی برنامه برای ورودی "چند شهر توریستی و دریایی بگو"