Semantic Search & Rag System on Website Chatbot
Pattern Recognition Author : Seyyed Mohammad Mousavi
1) Semantic Search
Semantic Search یعنی «جستوجو بر اساس معنی»، نه فقط پیدا کردن کلماتِ دقیق.
در جستوجوی معمولی (Keyword Search)، موتور جستوجو بیشتر دنبال صفحاتی میگردد که همان کلماتِ شما را داشته باشند. مشکل اینجاست که ممکن است یک صفحه دقیقاً جواب شما را بدهد، اما با کلمات دیگری نوشته شده باشد و در نتایج نیاید.
در جستوجوی معنایی، متنها را به چیزی به نام Embedding تبدیل میکنیم: یک لیست عددی که «معنی» متن را نمایندگی میکند. اگر دو متن از نظر مفهوم شبیه باشند، بردارهای عددیشان هم به هم نزدیک میشود.
پس وقتی شما سؤال میپرسید، سیستم بخشهایی از متن را پیدا میکند که از نظر معنی به سؤال شما نزدیکترند.
به طور خلاصه، روند ساخت semantic search معمولاً اینطوری است:
- جمعآوری سندها (صفحات وب، PDF، یادداشتها و …)
- تمیز کردن متن
- تقسیم به قطعههای کوچکتر (Chunk)
- تبدیل هر chunk به embedding
- ذخیره کردن embeddingها داخل یک ساختار جستوجوی برداری (برای پیدا کردن سریع متنهای مشابه)
- وقتی سؤال جدید میآید، embedding سؤال ساخته میشود و نزدیکترین chunkها برگردانده میشوند
2) LangChain
LangChain یک فریمورک برای پایتون و جاوااسکریپت است که کمک میکند دور و بر مدلهای زبانی (LLM) یک سیستم واقعی بسازیم.
خودِ LLM به تنهایی فقط متن میگیرد و متن تولید میکند. ولی توی پروژههای واقعی معمولاً این کارها هم لازم است:
- خواندن داده از منابع مختلف (وبسایت، فایل، دیتابیس و …)
- خرد کردن متنهای طولانی به chunk
- ساخت embedding
- ذخیره و جستوجوی برداری (مثل FAISS یا Chroma)
- ساختن یک جریانِ قابل اعتماد برای پرسشوپاسخ
- اضافه کردن حافظه، ابزارها و promptهای مخصوص
LangChain یک سری قطعه آماده برای همین کارها میدهد تا مجبور نباشیم همهچیز را از صفر به هم وصل کنیم. در خیلی از پروژهها، LangChain نقش «مدیر خط لوله» را دارد که داده را میگیرد، retrieval انجام میدهد، به LLM میدهد و جواب نهایی را تولید میکند.
3) How Semantic Search becomes RAG
Semantic search برای پیدا کردن متنهای مرتبط عالی است، ولی خودش به تنهایی یک جواب کامل و خوشخوان تولید نمیکند. اینجاست که RAG وارد میشود.
RAG مخفف Retrieval-Augmented Generation است، یعنی:
- Retrieval: با semantic search نزدیکترین chunkها را از بین دادهها پیدا کنیم
- Generation: همان chunkها را به LLM بدهیم تا بر اساس آنها جواب نهایی را بنویسد
این روش محبوب است چون:
- چتبات میتواند از دادههای خودتان جواب بدهد (صفحات سایت، فایلها، مستندات و …)
- احتمال جوابهای ساختگی کمتر میشود (چون مدل روی متنهای بازیابیشده تکیه میکند)
- برای آپدیت دانش لازم نیست مدل را دوباره آموزش بدهید؛ کافی است دیتای جدید را index کنید
یک جریان ساده RAG معمولاً این شکلی است: 1) شما سؤال میپرسید. 2) سیستم embedding سؤال را میسازد. 3) از روی vector index نزدیکترین chunkها را برمیگرداند. 4) سؤال + chunkهای برگرداندهشده داخل prompt به LLM داده میشود. 5) LLM یک جواب نهایی میسازد که به همان chunkها تکیه دارد.
4) Project
توی این پروژه یک چتبات ساختیم که پشتش semantic search و RAG قرار دارد:
- به سیستم یک سری URL از سایت میدهیم.
- صفحات دانلود میشود، متن استخراج و تمیز میشود.
- متن به chunkهای کوچکتر تقسیم میشود.
- برای هر chunk embedding ساخته میشود.
- embeddingها داخل FAISS ذخیره میشود (برای جستوجوی سریع شباهت).
- موقع چت، کاربر سؤال میپرسد؛ سیستم از FAISS نزدیکترین chunkها را برمیگرداند.
- بعد chunkها از طریق n8n به LLM داده میشود تا جواب نهایی ساخته شود.
5) File: Server-ingest.py (Building the Vector Database from URLs)
``` Python Code
from langchain_community.document_loaders import WebBaseLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS from langchain_huggingface import HuggingFaceEmbeddings
def main(): urls = [ … ] # list of website pages
loader = WebBaseLoader(urls)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=100)
split_docs = splitter.split_documents(docs)
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vs = FAISS.from_documents(split_docs, embeddings)
vs.save_local("/root/knowledge/visup-faiss")
if name == “main”: main()
فایل `Server-ingest.py` قسمت «آمادهسازی دادهها» (Ingestion) است. خیلی ساده بگم: یک لیست URL میگیرد، محتوای صفحات را میخواند، به chunk تبدیل میکند، برای هر chunk embedding میسازد و در نهایت یک ایندکس **FAISS** روی دیسک ذخیره میکند.
بعد از اینکه این مرحله انجام شد، چتبات (یا هر اسکریپت جستوجو) میتواند همان پوشهی FAISS را لود کند و خیلی سریع متنهای مرتبط را پیدا کند.
ساختار کلی کد همین چند بخش است:
1) *لیست URLها*: دقیقاً مشخص میکنید چتبات قرار است روی کدام صفحهها دانش داشته باشد.
2) *خواندن صفحات* با `WebBaseLoader`: لانگچین هر URL را دریافت میکند و خروجی را به صورت لیستی از `Document` برمیگرداند.
هر `Document` معمولاً شامل اینهاست:
- `page_content`: متن استخراجشده
- `metadata`: اطلاعات کمکی مثل آدرس صفحه
3) *تکهتکه کردن متن* با `RecursiveCharacterTextSplitter`: متن هر صفحه به قطعههای کوچکتر تقسیم میشود.
- `chunk_size=700` یعنی هر chunk حدوداً 700 کاراکتر است (تقریبی).
- `chunk_overlap=100` یعنی 100 کاراکتر از انتهای chunk قبلی ابتدای chunk بعدی هم میآید تا مفهوم وسط جملهها قطع نشود.
4) *ساخت embedding* با `HuggingFaceEmbeddings`: برای هر chunk یک بردار عددی ساخته میشود با مدل
`sentence-transformers/all-MiniLM-L6-v2` (مدل سبک و رایج برای embedding).
5) *ساخت ایندکس برداری* با `FAISS.from_documents`: FAISS این بردارها را طوری سازماندهی میکند که جستوجوی شباهت سریع شود.
6) *ذخیره روی دیسک* با `save_local(...)`: خروجی داخل یک پوشه ذخیره میشود تا دفعههای بعد لازم نباشد دوباره صفحات دانلود و embedding ساخته شود.
## 6) Running on a server (SSH + Docker)
بعضی وقتها اجرای پروژه روی یک سرور لینوکسی (VPS) خیلی راحتتر از لپتاپ است، مخصوصاً وقتی میخواهید چتبات همیشه روشن باشد.
ایده کلی ساده است:
1) با SSH وارد سرور میشویم
2) Docker نصب میکنیم
3) یک کانتینر پایتون بالا میآوریم
4) کتابخانههای پروژه را داخل کانتینر نصب میکنیم
5) کدها را روی سرور میگذاریم (آپلود یا git)
6) اول ingest را اجرا میکنیم (ساخت FAISS) و بعد اپ را اجرا میکنیم
این پایین یک روش کاربردی (برای Ubuntu/Debian) است. اگر سیستمعامل سرور فرق داشته باشد، فقط دستور نصب Docker فرق میکند.
**مرحله ۱: ورود به سرور با SSH**
```bash
ssh user@SERVER_IP
مرحله ۲: نصب Docker اگر Docker نصب نیست، این یک روش کوتاه و رایج است:
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable --now docker
مرحله ۳: انتقال پروژه به سرور
میتوانید با scp کل پوشه را آپلود کنید یا با git کلون کنید. نمونه با scp (این دستور را روی کامپیوتر خودتان بزنید):
scp -r ./langchain-semantic-search user@SERVER_IP:/opt/langchain-semantic-search
بعد روی سرور:
cd /opt/langchain-semantic-search
مرحله ۴: اجرای کانتینر پایتون و نصب نیازمندیها این دستور یک کانتینر بالا میآورد و پوشه پروژه را داخلش mount میکند:
sudo docker run --rm -it ^
-v "$PWD:/app" ^
-v "$PWD/vectorstore-local:/root/knowledge" ^
-w /app ^
--env-file .env ^
python:3.11-slim bash
داخل کانتینر:
pip install -r requirements.txt
مرحله ۵: ساخت دیتابیس برداری (FAISS) داخل همان کانتینر:
python Server-ingest.py
با توجه به mount که گذاشتیم، فایلهای FAISS داخل پوشهای که روی سرور گذاشتید ذخیره میشود (چون به /root/knowledge وصلش کردیم).
مرحله ۶: اجرای برنامه بسته به اینکه کدام فایل را اجرا میکنید:
python app-local.py
یا
python app-noLLM.py

7) n8n (How we connect the chatbot to the LLM)
n8n یک ابزار اتوماسیون و ساختِ workflow است. خیلی ساده: یک محیط بصری که با وصل کردن چند «نود» (Node) به هم، یک جریان کاری میسازید تا داده از یک مرحله به مرحله بعد برود.
توی پروژهی ما، n8n نقش واسطه بین چتبات و مدل زبانی (LLM) را دارد. یعنی به جای اینکه تمام کدهای مربوط به صدا زدن API مدل را داخل پایتون بنویسیم، یک workflow داخل n8n میسازیم که: 1) پیام کاربر را دریافت میکند (از سمت سایت/چت) 2) (اختیاری) کانتکست بازیابیشده را هم میگیرد (chunkهایی که از FAISS پیدا کردیم) 3) همهی اینها را برای LLM میفرستد (مثلاً Gemini یا هر سرویس دیگری که تنظیم کردهاید) 4) جواب نهایی را برمیگرداند به چتبات
اینطوری کد چتبات سادهتر میشود: کارش این است که retrieval انجام بدهد و داده را بفرستد/تحویل بگیرد؛ و n8n کار «ساخت prompt، صدا زدن مدل، و برگرداندن پاسخ» را انجام میدهد.
معمولاً برای این سیستم داخل n8n این چیزها را میسازیم:
- Webhook/Trigger: نقطه ورود کار؛ اپ شما این URL را صدا میزند و سؤال کاربر را میفرستد.
- نودهای آمادهسازی داده (اختیاری): مرتب کردن فیلدها، تمیز کردن متن، ساخت قالب prompt.
- نود LLM (یا HTTP Request به API مدل): جایی که مدل جواب را تولید میکند.
- Response: جواب را به درخواستکننده برمیگرداند.
جای RAG در این داستان:
- بخش Retrieval (جستوجوی FAISS) داخل پایتون انجام میشود.
- بخش Generation (جواب دادن با LLM) داخل n8n انجام میشود.
به همین خاطر وقتی روی سرور تست میگیرید، یک حلقه کامل «سؤال → retrieval → مدل → جواب» را به صورت end-to-end میبینید.
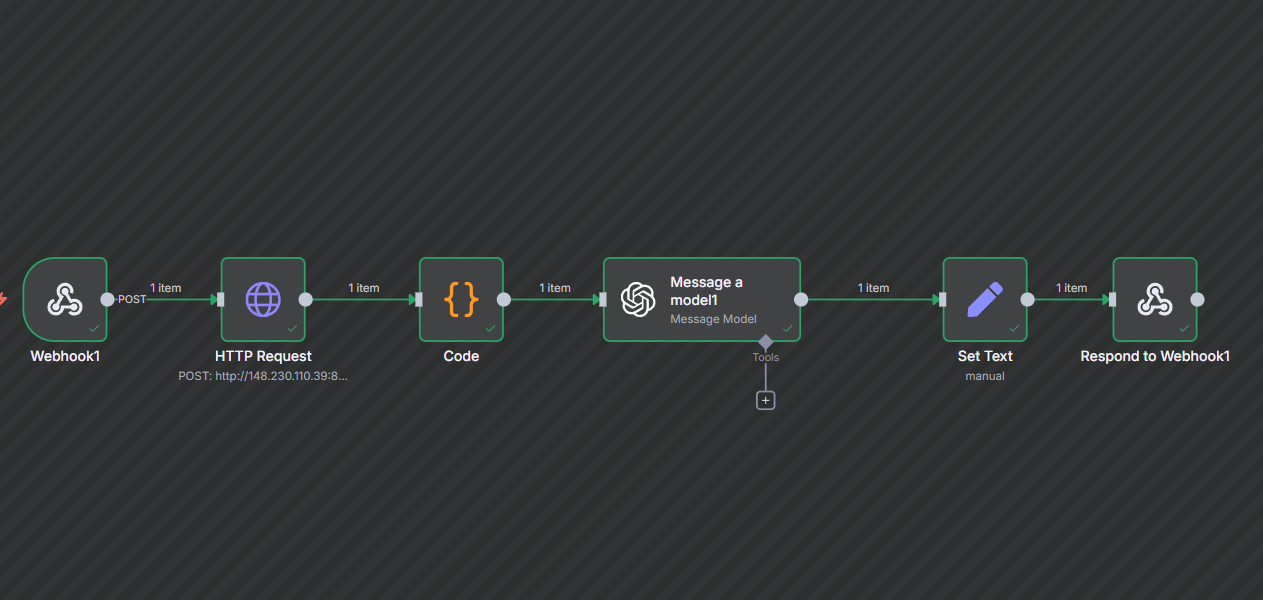
8) The exact n8n workflow we built (node-by-node)
توی این پروژه workflow ما داخل n8n خیلی ساده و خطی است و چندتا نود پشت سر هم دارد:

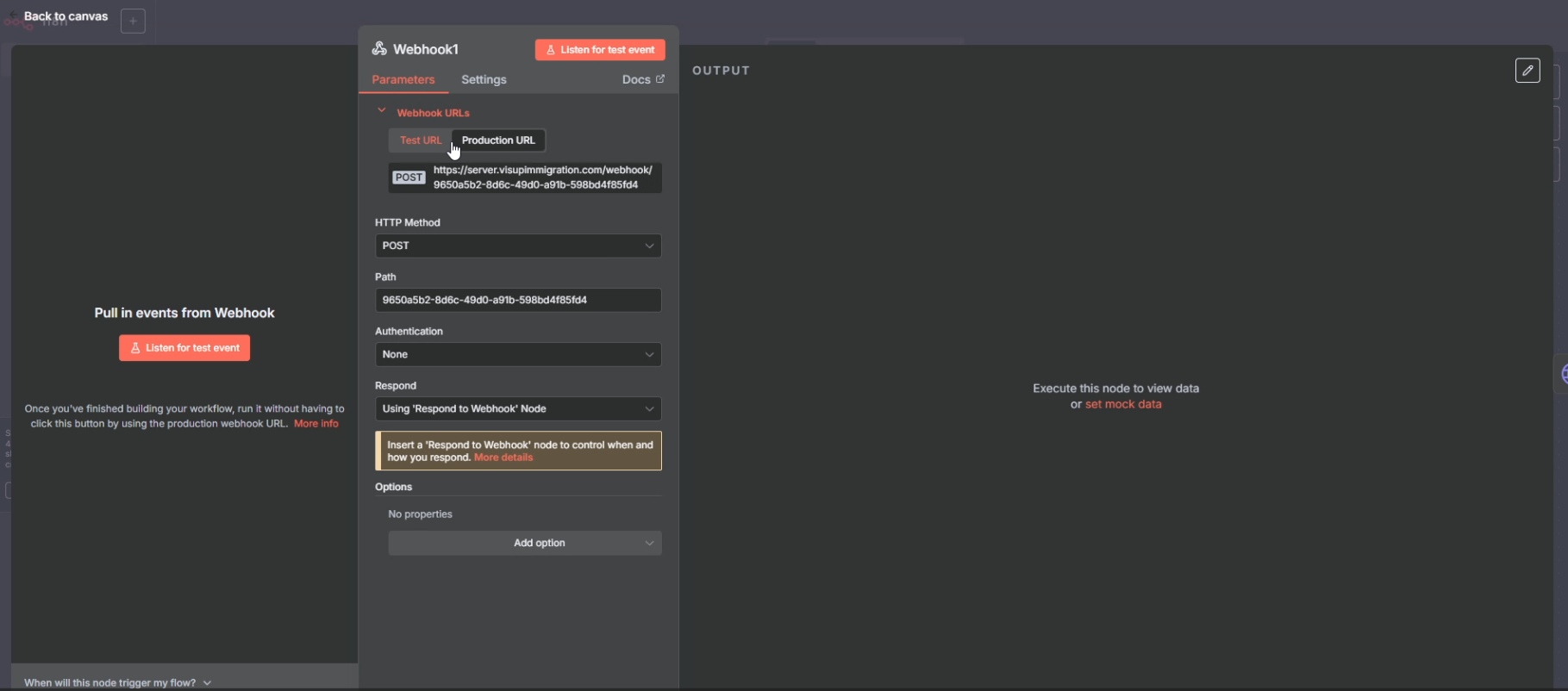
1) Webhook (ورودی کار)
این همان URL است که سایت/چتبات صدا میزند. معمولاً یک چیزی مثل این میفرستیم:
message: متن سؤال کاربر
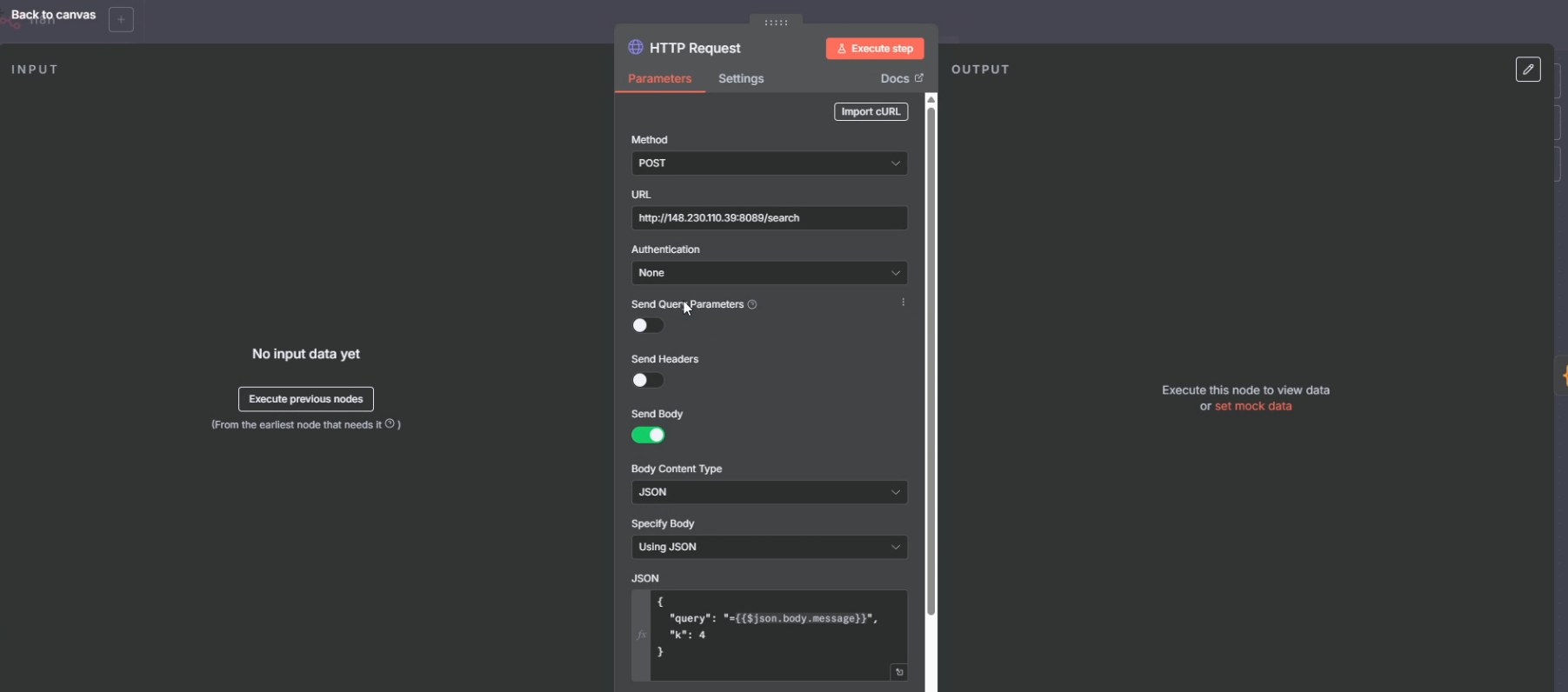
2) HTTP Request (صدا زدن API سرچ)
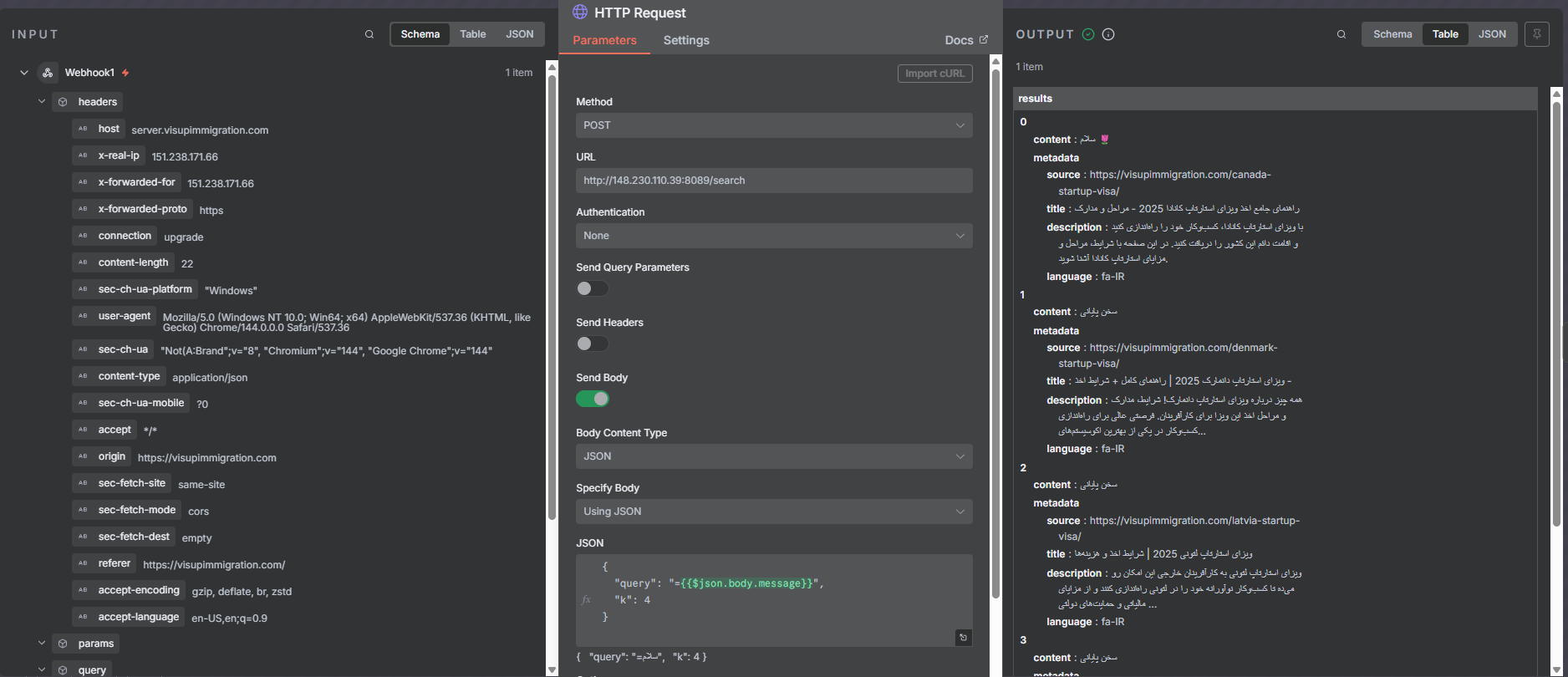
این نود به سرویس پایتونی ما درخواست میزند (همان جایی که FAISS را سرچ میکند).
داخل بدنهی JSON معمولاً اینها را میفرستیم:
query: همان پیام کاربرk: تعداد نتیجههایی که میخواهیم (مثلاً4)
خروجیاش هم معمولاً یک لیست از chunkهای پیدا شده است، مثلاً:
results:[ { content: \"...\", source: \"...\" }, ... ]
3) Code (تبدیل نتایج به یک متن تمیز به اسم Context)
نتیجههای سرچ به درد میخورند ولی خام هستند. توی این نود با یک کد کوتاه:
resultsرا میگیریم- همه را کنار هم میچینیم و یک
contextخوشخوان درست میکنیم (Source 1, Source 2, …)
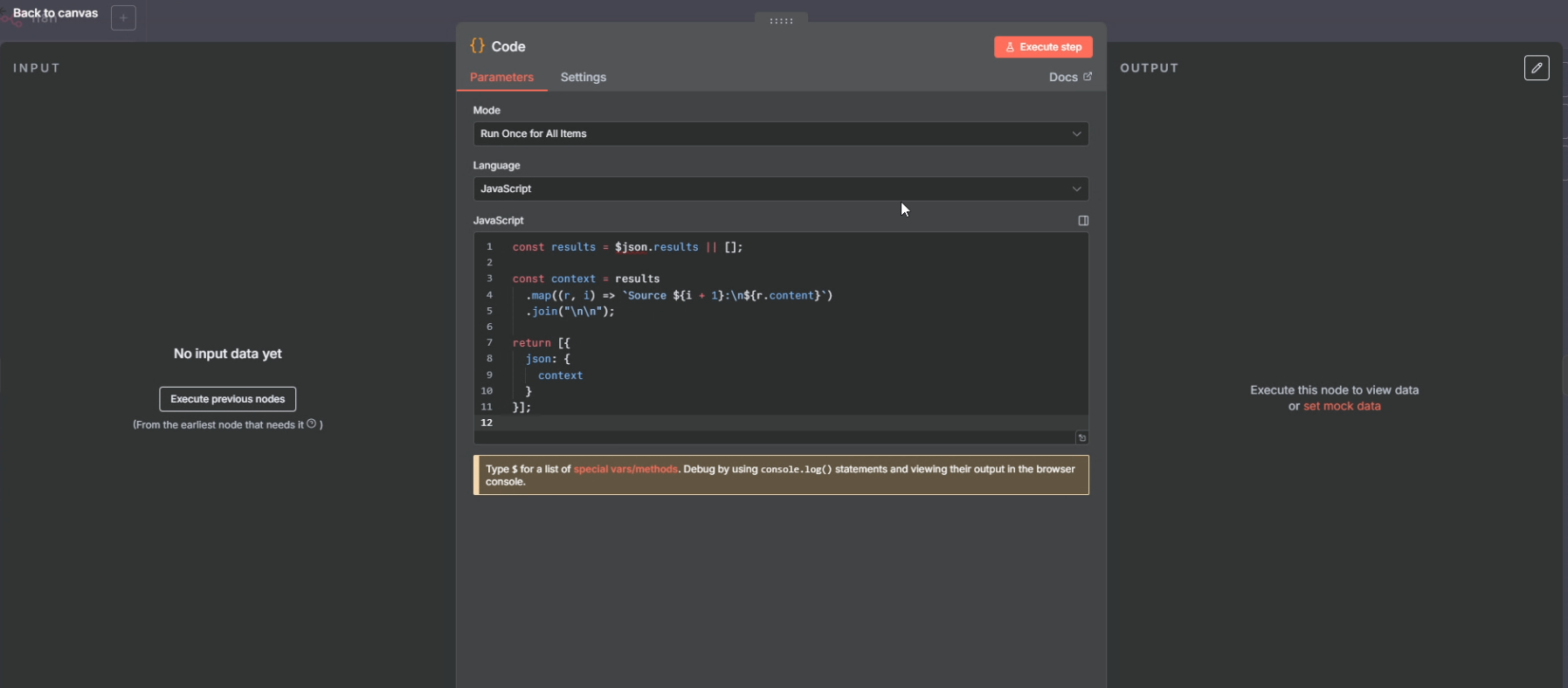
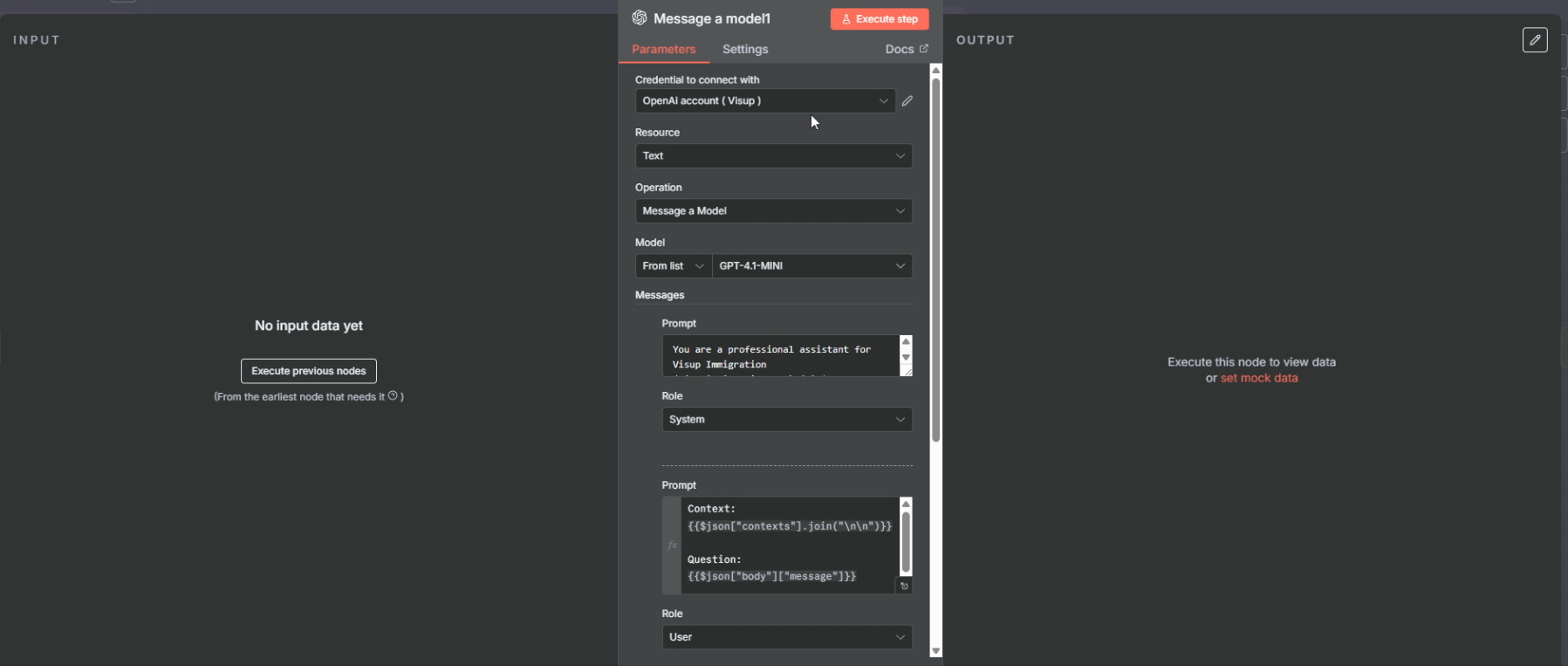
4) Message a model (مدل زبانی / LLM)
اینجا مدل را صدا میزنیم.
عملاً توی prompt این چیزها را میگذاریم:
- یک دستور کلی (system/role)
Context:متنهایی که از سرچ گرفتیمQuestion:سؤال کاربر
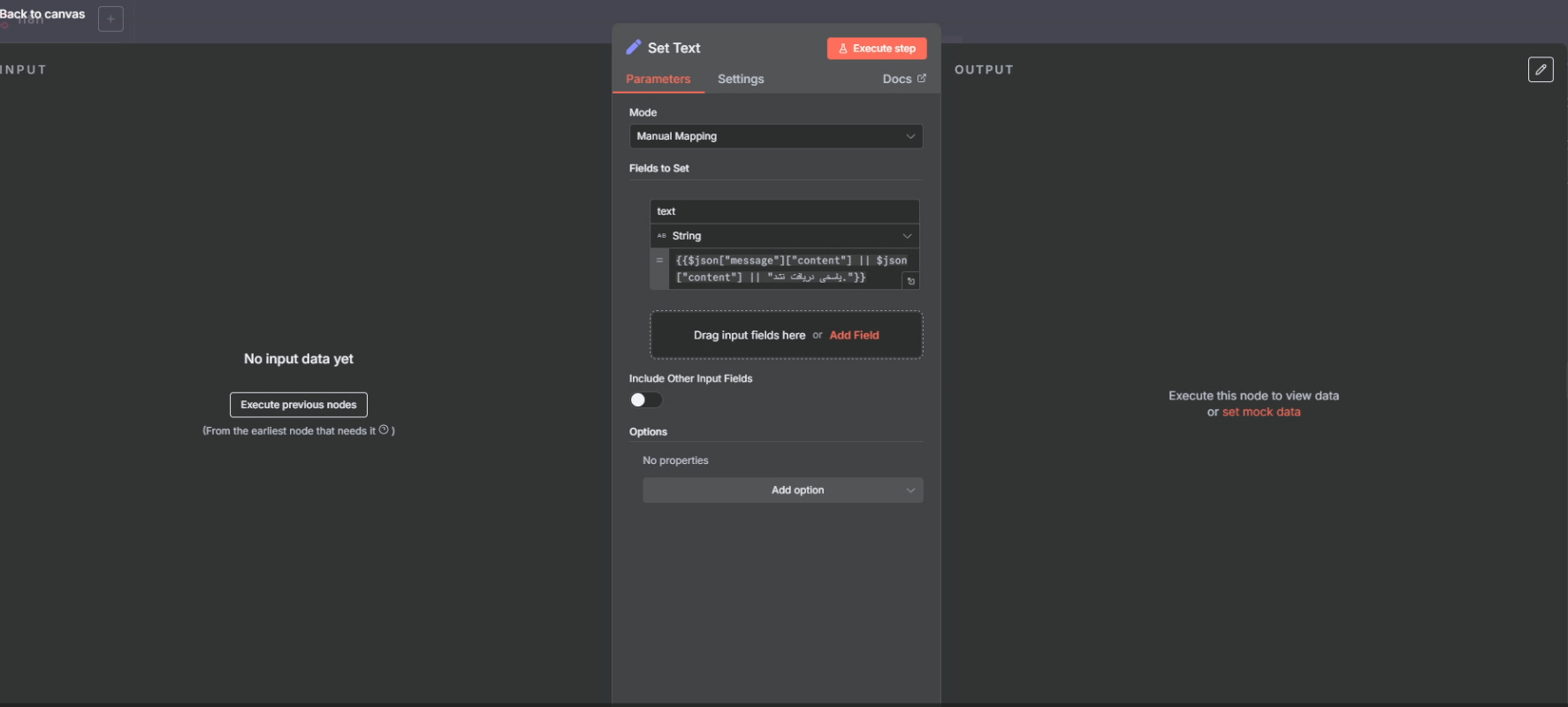
5) Set Text (مرتب کردن خروجی)
این نود خروجی مدل را برمیدارد (معمولاً message.content) و توی یک فیلد تمیز مثل answer میگذارد.
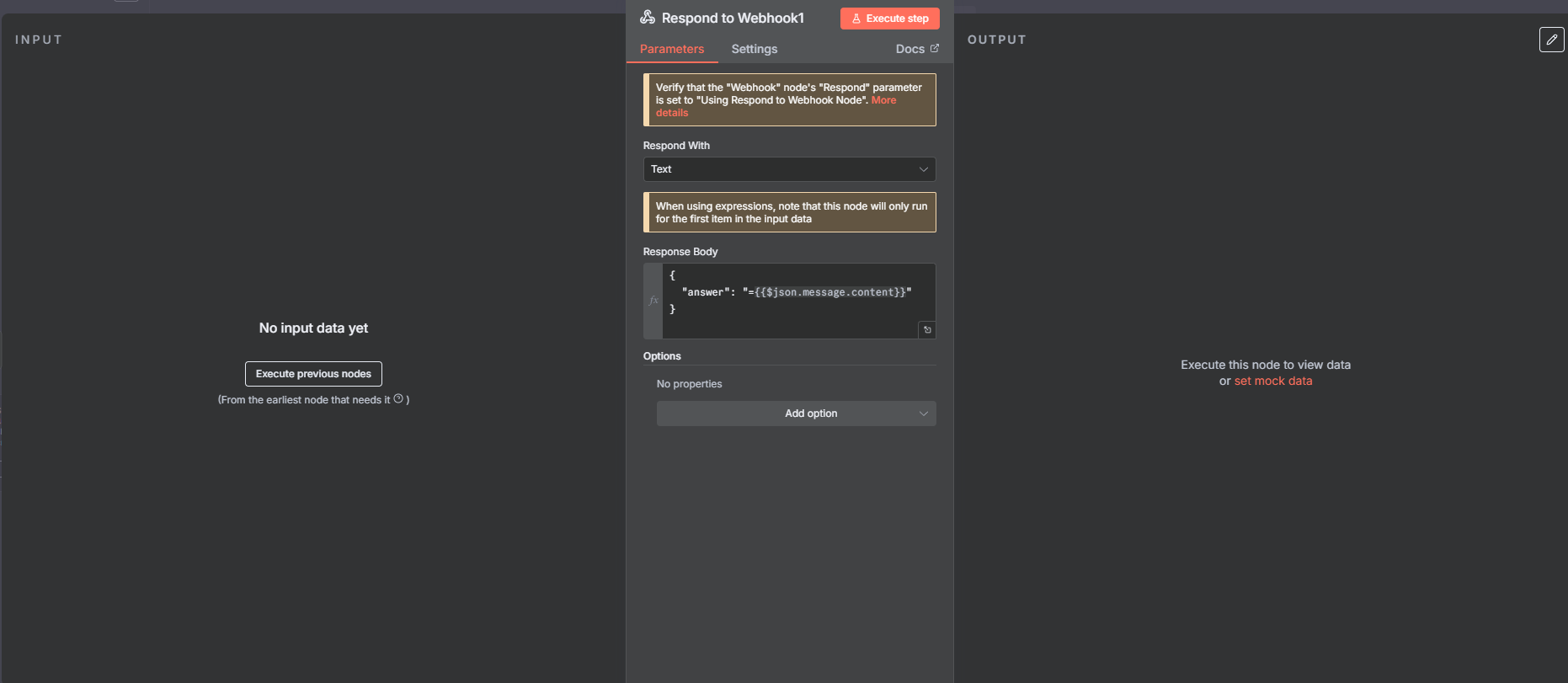
6) Respond to Webhook (برگرداندن پاسخ به سایت)
در آخر پاسخ را به شکل JSON برمیگردانیم تا چتبات روی سایت نشان بدهد، مثلاً:
{ \"answer\": \"...\" }
خیلی تمیز و رو به جلو. retrieval با پایتون/FAISS انجام میشود و n8n کار صدا زدن مدل و برگرداندن جواب نهایی را انجام میدهد.
9) Final server test (run the service + ask the chatbot)
در آخر یک تست واقعی روی سرور میگیریم تا مطمئن شویم سرویس بالا است و چتبات میتواند جواب بگیرد.
روی سرور این دستورها را میزنیم تا سیستم ران شود:
cd /root/kb-service
source .venv/bin/activate
uvicorn app:app --host 0.0.0.0 --port 8089
بعد از اینکه سرویس بالا آمد، داخل چتبات سایت سؤال میپرسیم و باید جواب را دریافت کنیم.