
نویسنده: محمدرضا باباگلی
ايميل: MohammadRezaBabagoli.AI@gmail.com
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
آزمایشگاه شناسایی الگو دکتر هادی صدوقی یزدی
تشخیص سرقت ادبی - Plagiarism Detection

مقدمه
سرقت ادبی چیست؟ سرقت ادبی یا Plagiarism یکی از انواع نقض مالکیت فکری است که به معنای استفاده از آثار دیگران، شامل آثار ادبی، هنری و علمی، بدون اشاره به منبع اصلی است. سرقت ادبی میتواند نقض حق نشر (کپی رایت) محسوب شود و به عنوان سرقت آثار و نقض حقوق مولف اثر شناخته شود. سرقت ادبی به انگلیسی ، پلاجریسم (Plagiarism) نامیده میشود. در حقیقت، سرقت ادبی یک نوع تخلف اخلاقی در حوزه علم و پژوهش است که اعتبار نویسنده و پژوهشگر را تحت تاثیر قرار میدهد و میتواند عواقب قانونی و حرفهای سنگینی به همراه داشته باشد. این پدیده نه تنها در آثار علمی و دانشگاهی، بلکه در تمام زمینههای خلاقانه از جمله ادبیات، هنر، و حتی محتوای دیجیتال نیز قابل مشاهده است.
تشخیص سرقت ادبی (Plagiarism Detection) Plagiarism detection یا «تشخیص سرقت ادبی» به مجموعهای از روشها و سیستمها گفته میشود که برای شناسایی شباهت غیرمجاز بین یک متن و منابع دیگر به کار میروند. هدف آن تشخیص این است که آیا بخشی از یک متن، بهطور مستقیم یا غیرمستقیم، از آثار دیگران بدون ارجاع مناسب استفاده شده است یا نه.
انواع سرقت ادبی
۱. سرقت ادبی مستقیم (Direct / Verbatim Plagiarism) در این نوع، نویسنده بخشهایی از متن را کلمه به کلمه از منبع دیگری کپی میکند بدون اینکه از نقلقول (“quotation marks”) یا ارجاع مناسب استفاده کند. این شکل از سرقت ادبی سادهترین و آشکارترین نوع است.
۲. سرقت ادبی کامل (Global / Complete Plagiarism) کل یک متن، مقاله یا اثر را از منبع دیگر بدون هیچ تغییری و بدون دادن اعتبار به صاحب اصلی ارائه میدهد. این نوع در بسیاری از ساختارهای دانشگاهی شدیدترین تخلف محسوب میشود.
۳. سرقت ادبی موزاییکی (Mosaic / Patchwork Plagiarism) ترکیبی از بخشهای مختلف منابع متفاوت را برداشته و آنها را با تغییرات کوچک (مثلاً جایگزینی چند واژه) کنار هم میگذارد، اما باز هم منبع داده نمیشود. در حقیقت متن جدید از قطعات دیگران تشکیل شده اما بهطور مصنوعی به نظر میرسد.
۴. بازنویسی سرقتی (Paraphrasing Plagiarism) فرد ایده یا محتوای منبع دیگری را با تغییر ساختار یا واژگان بازنویسی میکند اما به منبع اصلی اشاره نمیکند. تفاوت آن با سرقت مستقیم این است که جملات کپی نمیشوند، اما مفهوم بدون ارجاع منتقل میشود.
۵. خودسرقت ادبی (Self-Plagiarism) نویسنده از آثار قبلی خودش استفاده میکند و آن را بهعنوان کار جدید ارائه میدهد بدون اینکه بگوید این محتوا قبلاً منتشر شده است. این نوع در پژوهش و انتشار علمی نیز بهعنوان تخلف شناخته میشود.
۶. سرقت ادبی ناخواسته (Accidental Plagiarism) بهدلیل بیدقتی، عدم آگاهی از روش صحیح ارجاعدهی یا سوءتفاهم در نحوۀ بازنویسی، فرد بهطور ناخواسته منابع را بهدرستی ذکر نمیکند یا مفهوم منبع را خیلی نزدیک به متن اصلی مینویسد. حتی اگر قصد اخلاقی نداشته باشد، باز هم میتواند تخلف محسوب شود
۷. سرقت ادبی مبتنی بر منبع (Source-Based Plagiarism / Misleading Attribution) ارجاع به منبع اشتباه، ارائه منبعی که وجود ندارد، یا ارجاع به ثانویه بدون ذکر منبع اصلی زمانی رخ میدهد که نویسنده به شکلی گمراهکننده منابع را معرفی کند
روشهای تشخیص سرقت ادبی

روشهای تشخیص سرقت ادبی (plagiarism detection) در ادبیات کامپیوتر و مهندسی نرمافزار به چند دسته اصلی تقسیم میشود که هر یک بر پایهٔ ویژگیهای متفاوت متن و الگوریتمهای مختلف عمل میکنند. این روشها معمولاً در ابزارهای تجاری و پژوهشی بهصورت ترکیبی به کار میروند تا حالات گوناگون سرقت (کپی مستقیم، پارافرایز، ترجمه و غیره) را شناسایی کنند.
۱) روشهای تطبیق رشتهای (String Matching / Exact Matching) در این روش متن به رشتهها یا بخشهای کوتاه تقسیم میشود و سپس این رشتهها در مجموعهٔ منابع جستجو میشوند. اگر بخشهای طولانی از متن مشابه منابع دیگر باشند، احتمال سرقت ادبی بالاست. این روش برای تشخیص کپی مستقیم مناسب است اما در برابر بازنویسی یا تغییرات واژگانی آسیبپذیر است.
۲) روشهای n-گرم و اثرانگشت (n-gram و Fingerprinting) متن به توالیهای kتایی از کاراکترها یا کلمات تقسیم میشود (n-گرم) و سپس این توالیها به امضاهای عددی (hash) تبدیل میشوند. مقایسهٔ این امضاها بین دو سند میزان شباهت را نشان میدهد و به کارایی بالا در مقایسه با پایگاه دادههای بزرگ کمک میکند. Jaccard similarity یکی از معیارهای رایج برای سنجش همپوشانی این امضاهاست.
۳) روشهای معنایی و مبتنی بر NLP (Semantic / NLP-based) این روشها تلاش میکنند معنای واقعی جملات را استخراج کنند و نه فقط شباهت لفظی. با استفاده از تکنیکهایی مثل word embedding (مثلاً Word2Vec یا BERT)، بردارهایی از مفاهیم جملات ساخته میشود و شباهت معنایی آنها اندازهگیری میشود. این نوع روش برای تشخیص پارافرایزهای پیچیده و بازنویسیها کاربرد دارد.
۴) تحلیل نحو و رشتهوارهها (Syntactic / Grammar-based) در این رویکرد ساختار دستوری متن بررسی میشود (مثلاً با تگگذاری نقش دستوری یا تحلیل درختی). سپس شباهتهای نحوی بین جملات یا بخشهای متن محاسبه میشود که میتواند بازنویسی با تغییر ساختار را هم تا حدی شناسایی کند.
۵) روشهای آماری و برداری (Vector-based / Statistical) در این روشها متن به بردارهای عددی تبدیل میشود (مثلاً TF-IDF) و سپس بردارها با معیارهایی مثل کسینوس شباهت مقایسه میشوند. این روشها در ابزارهای ساده برای سنجش میزان شباهت کلی متن استفاده میشوند و سرعت بالایی دارند.
۶) روشهای درونمتنی و بدون استفاده از مرجع (Intrinsic Detection) این دسته زمانی به کار میرود که مرجع خارجی وجود ندارد یا در دسترس نیست. الگوریتمها تغییرات سبک نوشتار یا عدم همگونی را در یک سند تحلیل میکنند تا بخشهایی را که به سبک کلی نویسنده نمیخورند پیدا کنند. این روش میتواند نشاندهندهٔ سرقت ناخواسته باشد.
۷) روشهای مبتنی بر سبک نگارش (Stylometry / Authorship Attribution) این روشها ویژگیهای آماری سبک نوشتار (مثلاً توزیع طول جملات، فراوانی واژگان، الگوهای نگارشی) را تحلیل میکنند تا مشخص کنند آیا بخشهای مختلف یک متن به یک نویسنده تعلق دارند یا خیر. این میتواند در تشخیص سرقت ادبی پیچیده یا بررسی مشارکت چند نویسنده مفید باشد.
۸) روشهای ترکیبی و یادگیری ماشین (Machine Learning / Hybrid Methods) روشهای جدید از یادگیری ماشین، شبکههای عصبی عمیق، یا مدلهای پیشآموزشدیده (مثلاً LSTM و transformerها) استفاده میکنند تا هم شباهت سطحی و هم معنایی را همزمان بررسی کنند. این دسته در مواجهه با متون بازنویسیشده، تغییرات ساختاری و حتی ترجمهها کارایی بهتری از روشهای سنتی دارد.
ابزارهای تجاری و پژوهشی معمولاً چند تا از این روشها را با هم ترکیب میکنند تا هم سرعت و هم دقت را افزایش دهند و انواع مختلف سرقت ادبی را شناسایی کنند.
شناسایی نویسنده (Authorship Attribution)
۱. ویژگیهای سبکسنجی (Stylometric Features)
ویژگیهای سبکسنجی ابزارهایی هستند که برای کمیسازی سبک نوشتاری استفاده میشوند. این ویژگیها به دستههای مختلفی تقسیم میشوند:
۱.۱ ویژگیهای واژگانی (Lexical Features)
الف) ویژگیهای مبتنی بر توکن
سادهترین روش برای بررسی متن، در نظر گرفتن آن به عنوان دنبالهای از توکنها (کلمات، اعداد، علائم نگارشی) است. ویژگیهای پایه شامل:
- طول جمله: تعداد کلمات در هر جمله
- طول کلمه: تعداد حروف در هر کلمه
- توزیع علائم نگارشی: فراوانی استفاده از ویرگول، نقطه، علامت سوال و غیره
ب) توابع غنای واژگانی
این توابع تلاش میکنند تنوع واژگان یک متن را کمی کنند:
نسبت نوع به نمونه (Type-Token Ratio):
TTR = V/N
که در آن:
- V = تعداد کلمات یکتا (منحصر به فرد)
- N = تعداد کل کلمات متن
مشکل: این نسبت به شدت به طول متن وابسته است و با افزایش طول متن، مقدار آن کاهش مییابد.
تابع K یول (Yule’s K):
K = 10^4 × (Σ(i² × Vi) - N) / N²
که در آن:
- Vi = تعداد کلماتی که دقیقاً i بار تکرار شدهاند
- N = تعداد کل کلمات
تابع R هونور (Honore’s R):
R = 100 × log(N) / (1 - V1/V)
که در آن:
- V1 = تعداد کلماتی که فقط یک بار ظاهر شدهاند (hapax legomena)
این توابع تلاش میکنند تا پایداری بیشتری نسبت به طول متن داشته باشند، اما هنوز به طور کامل قابل اعتماد نیستند.
ج) فراوانی کلمات
رایجترین روش نمایش متن، استفاده از بردار فراوانی کلمات است. تفاوت مهم در تشخیص نویسندگی نسبت به طبقهبندی موضوعی:
کلمات تابعی (Function Words) مانند “و”، “از”، “به” بهترین ویژگیها برای تمایز بین نویسندگان هستند، چرا که:
- به طور ناخودآگاه استفاده میشوند
- مستقل از موضوع هستند
- الگوهای سبکی خالص را نشان میدهند
مثالهایی از مجموعههای کلمات تابعی:
- 150 کلمه (Abbasi و Chen، 2005)
- 303 کلمه (Argamon و همکاران، 2003)
- 675 کلمه (Argamon و همکاران، 2007)
روش انتخاب: استخراج n کلمه پرتکرار متن (معمولاً 100 تا 1000 کلمه)
د) n-گرامهای کلمهای
برای در نظر گرفتن اطلاعات زمینهای، n کلمه متوالی به عنوان ویژگی استفاده میشود:
مثال: عبارت “take on a new challenge”
- بایگرامها: “take on”، “on a”، “a new”، “new challenge”
- تریگرامها: “take on a”، “on a new”، “a new challenge”
محدودیتها:
- افزایش شدید ابعاد مسئله
- پراکندگی بالای دادهها
- احتمال گرفتن اطلاعات موضوعی به جای سبکی
۱.۲ ویژگیهای کاراکتری (Character Features)
در این روش، متن به عنوان دنبالهای از کاراکترها در نظر گرفته میشود.
الف) ویژگیهای ساده
- تعداد حروف الفبا
- تعداد ارقام
- تعداد حروف بزرگ و کوچک
- فراوانی هر حرف
- تعداد علائم نگارشی
ب) n-گرامهای کاراکتری
تعریف: n کاراکتر متوالی
مثال: برای عبارت “A more elaborate”
-
4-گرامها: A_mo ، _mor ، more ، ore_ ، re_e ، e_el
| (علامت | نشاندهنده مرز n-گرام و _ نشاندهنده فاصله است) |
مزایا:
- سادگی محاسباتی: نیاز به ابزار پیشپردازش ندارد
- مقاومت در برابر نویز: اشتباهات املایی تأثیر کمی دارد
- مستقل از زبان: برای زبانهای مختلف قابل استفاده
- جامعیت: اطلاعات واژگانی، زمینهای و نگارشی را میگیرد
مثال مقاومت در برابر نویز: کلمه “simplistic” و “simpilstc” (غلط) تریگرامهای مشترک زیادی دارند:
-
مشترک: sim ، imp ، mpi ، pil ، ils ، lst -
متفاوت: stc (در کلمه غلط) و sti ، tic (در کلمه صحیح)
انتخاب n:
- n کوچک (2-3): اطلاعات زیرکلمهای (هجا مانند)
- n بزرگ (4-5): اطلاعات کلمهای و زمینهای بهتر، اما ابعاد بیشتر
- n متغیر: ترکیب مزایای هر دو
n-گرامهای متغیر: استفاده از تمام n-گرامها با طولهای مختلف (مثلاً 2 تا 5)
ج) روشهای فشردهسازی
ایده اصلی: استفاده از الگوریتمهای فشردهسازی متن برای اندازهگیری شباهت
روش کار:
- فشردهسازی متن نویسنده A: C(A)
- الحاق متن ناشناخته x به A: A+x
- فشردهسازی متن ترکیبی: C(A+x)
- محاسبه تفاوت: d(x,A) = C(A+x) - C(A)
اگر x و A توسط نویسنده یکسانی نوشته شده باشند، تفاوت کم خواهد بود.
الگوریتمهای فشردهسازی مورد استفاده:
- RAR (بهترین نتایج)
- GZIP
- BZIP2
- 7ZIP
۱.۳ ویژگیهای نحوی (Syntactic Features)
این ویژگیها اطلاعات ساختار دستوری جملات را میگیرند.
الف) برچسبگذاری نقش دستوری (POS Tagging)
به هر کلمه یک برچسب دستوری نسبت داده میشود:
مثال: “Another attempt to exploit syntactic information”
- Another/DT attempt/NN to/TO exploit/VB syntactic/JJ information/NN
که در آن:
- DT = تعیینکننده
- NN = اسم
- TO = حرف اضافه
- VB = فعل
- JJ = صفت
ویژگیها:
- فراوانی هر برچسب
- فراوانی بایگرامها یا تریگرامهای برچسبها
ب) تجزیه قطعهای (Chunking)
شناسایی عبارات مختلف در جمله:
مثال: “Another attempt to exploit syntactic information was proposed”
- NP[Another attempt] VP[to exploit] NP[syntactic information] VP[was proposed]
که در آن:
- NP = عبارت اسمی
- VP = عبارت فعلی
ویژگیها:
- تعداد عبارات اسمی
- تعداد عبارات فعلی
- طول میانگین عبارات
- نسبت انواع عبارات
ج) قوانین بازنویسی (Rewrite Rules)
تجزیه کامل ساختار نحوی:
مثال قانون:
A:PP → P:PREP + PC:NP
معنی: یک عبارت حرف اضافهای قیدی (A:PP) از یک حرف اضافه (P:PREP) و یک عبارت اسمی (PC:NP) تشکیل میشود.
ویژگی: فراوانی هر قانون بازنویسی در متن
مشکل: نیاز به تجزیهگر کامل و دقیق که برای متون غیررسمی معمولاً خطا دارد.
۱.۴ ویژگیهای معنایی (Semantic Features)
این ویژگیها سطح بالاترین تحلیل را ارائه میدهند اما استخراج آنها دشوارتر است.
الف) مترادفها و مفاهیم
استفاده از WordNet یا منابع مشابه برای یافتن:
- مترادفهای کلمات
- روابط مفهومی (hypernym/hyponym)
- افعال علّی
ب) ویژگیهای کارکردی (Functional Features)
مبتنی بر نظریه دستور زبان نقشگرای سیستمی (Systemic Functional Grammar):
مثال: طرحواره CONJUNCTION که نشان میدهد یک جمله چگونه بر جنبهای از زمینه قبلی خود گسترش مییابد:
- ELABORATION (توضیح): کلماتی مثل “specifically”، “in other words”
- EXTENSION (افزودن): کلماتی مثل “moreover”، “in addition”
- ENHANCEMENT (تقویت): کلماتی مثل “therefore”، “consequently”
ویژگیها: فراوانی استفاده از هر نوع گسترش معنایی
۱.۵ ویژگیهای وابسته به کاربرد
الف) ویژگیهای ساختاری
برای متون الکترونیکی مثل ایمیل یا پستهای آنلاین:
- استفاده از سلام و خداحافظی
- نوع امضا
- استفاده از تورفتگی (Indentation)
- طول پاراگراف
- استفاده از تگهای HTML
- رنگ و اندازه فونت
ب) ویژگیهای خاص موضوع
کلمات کلیدی مرتبط با موضوع خاص که نویسندگان متفاوت از آنها به شکلهای مختلف استفاده میکنند.
مثال: در پیامهای فروش آنلاین: “deal”، “sale”، “obo” (or best offer)
ج) ویژگیهای خاص زبان
مثال: در یونانی مدرن، پایانههای فعلی که در انواع رسمی (Katharevousa) و غیررسمی (Dimotiki) زبان متفاوت هستند.
۲. گروههای زیررشته کلیدی: ساخت درخت پسوند برای نمایش تمام n-گرامهای ممکن و سپس گروهبندی آنها بر اساس فراوانی و افزونگی.
۲. روشهای تشخیص نویسندگی
روشهای تشخیص نویسندگی بر اساس نحوه برخورد با متون آموزشی به سه دسته تقسیم میشوند:
۲.۱ روشهای مبتنی بر پروفایل (Profile-based)
اصل کار:
تمام متون آموزشی هر نویسنده به یک فایل بزرگ متصل میشوند و یک نمایش تجمعی (پروفایل) از سبک نویسنده استخراج میشود.
معماری:
متون نویسنده A → [متن₁ + متن₂ + متن₃] → پروفایل A
متون نویسنده B → [متن₁ + متن₂] → پروفایل B
متن ناشناخته → پروفایل متن ناشناخته
فرمول تخمین نویسنده:
author(x) = argminₐ∈A d(PR(x), PR(xₐ))
توضیح فرمول تخمین نویسنده
این فرمول یک روش آماری/ریاضی برای شناسایی نویسنده یک متن ناشناس ارائه میدهد. اجزای فرمول را به ترتیب توضیح میدهم:
۱. هدف فرمول: تعیین نویسندهی یک متن مجهول (x) با مقایسهی آن با نوشتههای نویسندگان شناختهشده.
۲. اجزای فرمول:
x: متن ناشناسی که میخواهیم نویسندهی آن را شناسایی کنیم.
A: مجموعهای از نویسندگان کاندید (نویسندگان شناختهشدهای که احتمال میدهیم نویسندهی متن x باشند).
a: یک نویسنده خاص از مجموعه A.
xₐ: تمام متون شناختهشدهای که از نویسنده a در اختیار داریم (اتصال/کنار هم گذاشتن همهی نوشتههای آن نویسنده).
PR(x): پروفایل یا ویژگیهای استخراجشده از متن x. این پروفایل میتواند شامل معیارهایی مانند:
- فراوانی کلمات تابع (the، is، و…)
- میانگین طول جملات
- الگوهای نشانهگذاری
- سبکهای نگارشی خاص
- ویژگیهای آماری دیگر
PR(xₐ): پروفایل نویسنده a که از تحلیل تمام نوشتههای شناختهشدهی او به دست آمده است.
d(·, ·): تابع فاصله که میزان شباهت یا تفاوت بین دو پروفایل را اندازه میگیرد. هرچه این فاصله کمتر باشد، دو پروفایل شبیهتر هستند.
argminₐ∈A: این بخش میگوید: “آن نویسنده a از مجموعه A را انتخاب کن که مقدار تابع فاصله برای آن مینیمم (کمترین) باشد.”
۳. تفسیر کلی فرمول:
“نویسندهی متن ناشناس x، آن نویسندهای از بین نویسندگان شناختهشده است که پروفایل سبک نوشتاریاش (بر اساس همهی نوشتههای قبلیاش) کمترین فاصله را با پروفایل متن ناشناس x داشته باشد.”
۴. مراحل اجرا: ۱. از متن مجهول x یک پروفایل سبکی استخراج میکنیم (PR(x)) ۲. برای هر نویسنده کاندید a:
- همهی متون شناختهشدهی او را جمع میکنیم (xₐ)
- از این مجموعه، پروفایل نویسنده را استخراج میکنیم (PR(xₐ))
- فاصله بین PR(x) و PR(xₐ) را محاسبه میکنیم ۳. نویسندهای که کمترین فاصله را داشته باشد، به عنوان نویسندهی احتمالی متن x انتخاب میشود.
۵. مثال:
فرض کنید متنی ناشناس داریم و سه نویسنده کاندید: الف، ب، ج.
فاصلهی پروفایل متن ناشناس با پروفایل هر نویسنده:
- فاصله با الف: ۲.۱
- فاصله با ب: ۰.۸
- فاصله با ج: ۳.۴
نویسندهی ب انتخاب میشود زیرا کمترین فاصله (۰.۸) را دارد.
این روش مبتنی بر این فرض است که هر نویسنده “امضای سبکی” منحصر به فردی دارد که در نوشتههایش پایدار است.
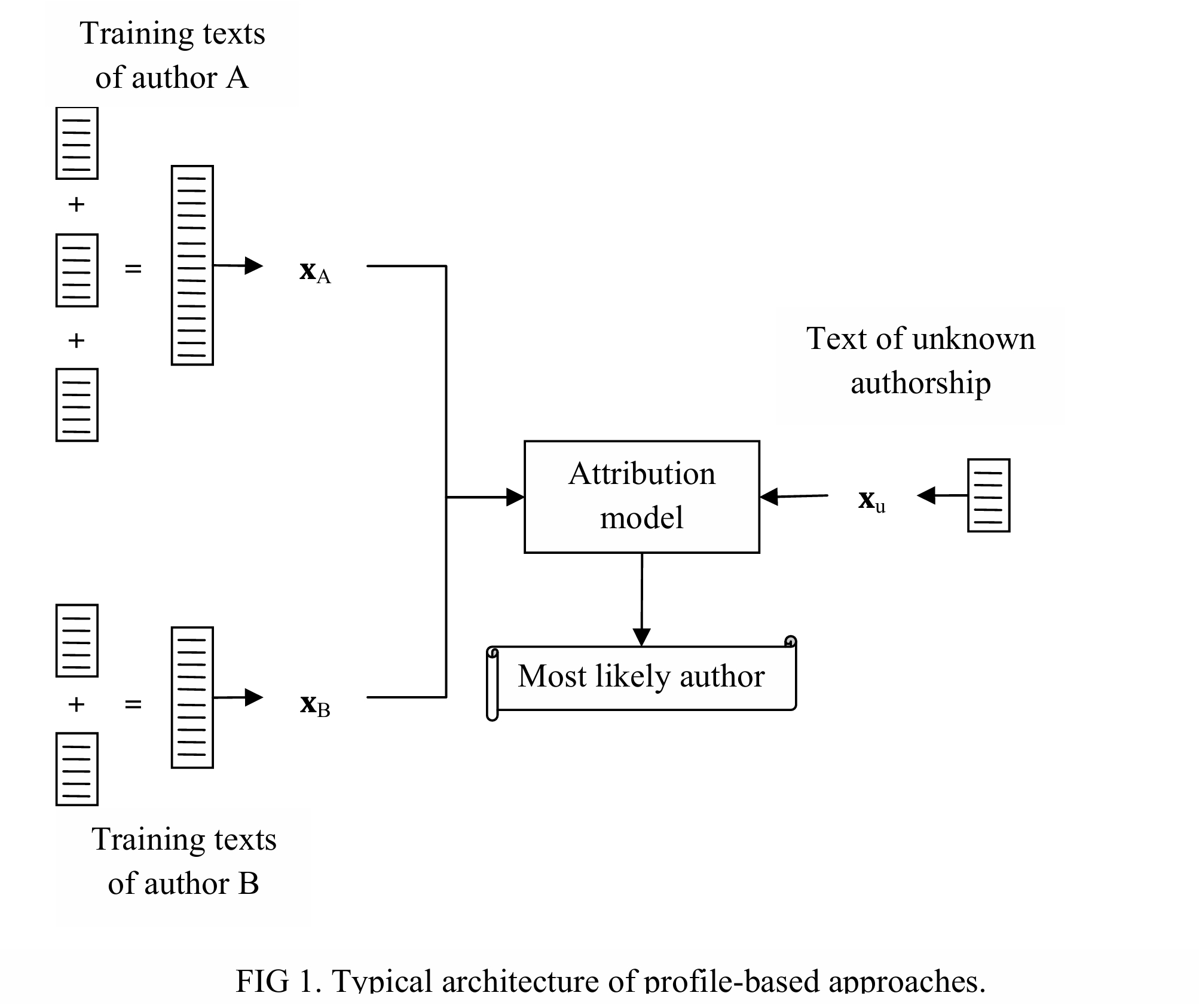
معماری مرسوم روش مبتنی بر پروفایل
۲.۲ روشهای مبتنی بر نمونه (Instance-based)
اصل کار:
هر متن آموزشی به طور جداگانه نمایش داده میشود و یک مدل طبقهبندی آموزش داده میشود.
معماری:
متن₁ نویسنده A → بردار ویژگی x_{A,1}
متن₂ نویسنده A → بردار ویژگی x_{A,2}
متن₃ نویسنده A → بردار ویژگی x_{A,3}
↓
مدل طبقهبندی
↓
متن ناشناخته → بردار ویژگی x_u → نویسنده تخمینی
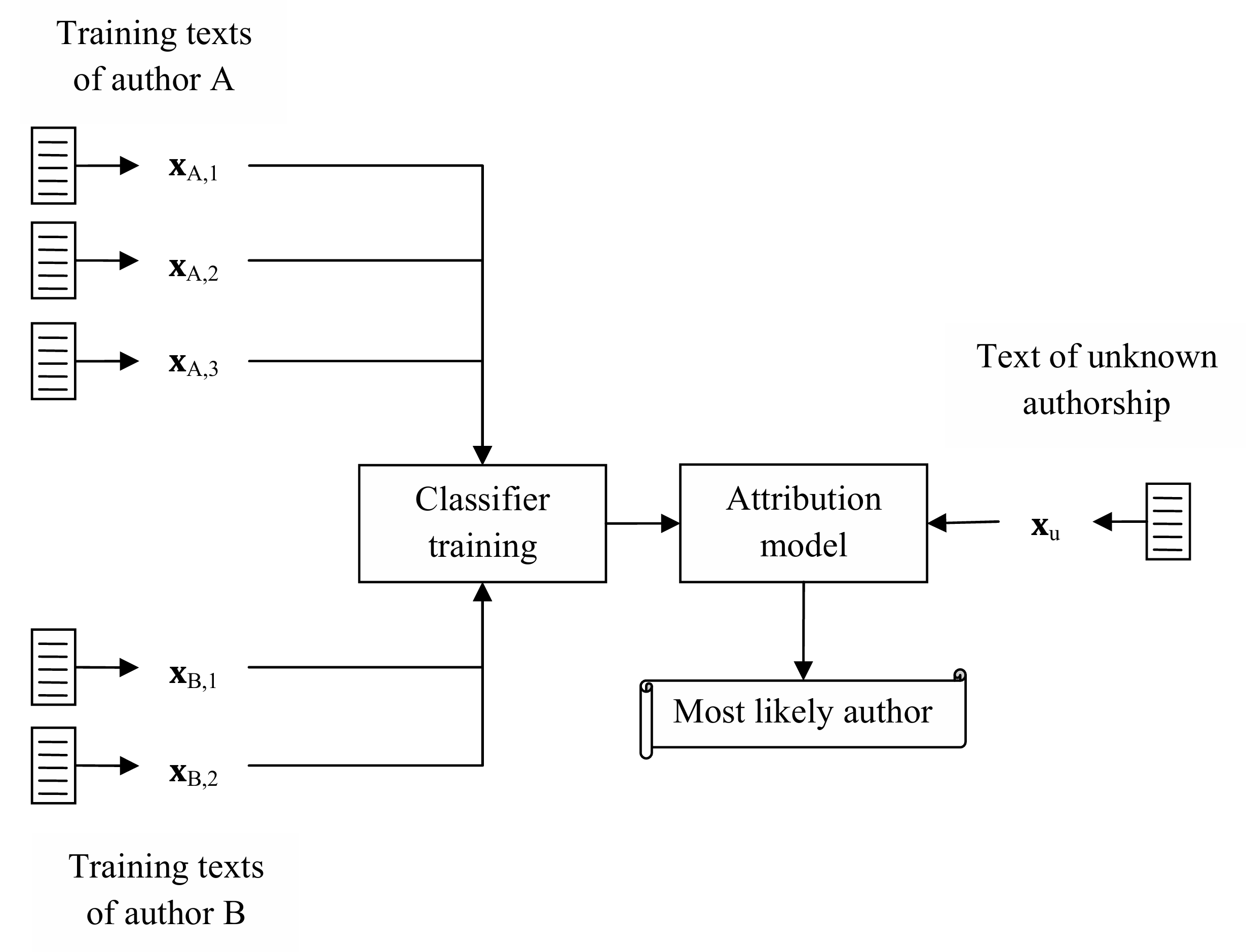
معماری مرسوم روش مبتنی بر نمونه
۲.۳ روشهای ترکیبی (Hybrid)
روش van Halteren:
- هر متن آموزشی جداگانه نمایش داده میشود (مثل روشهای instance-based)
- بردارهای نمایش برای متون هر نویسنده میانگینگیری میشوند (مثل روشهای profile-based)
- فاصله بین پروفایل متن ناشناخته و پروفایل هر نویسنده با تابع وزندار محاسبه میشود:
d(x, a) = Σᵢ wᵢ × (xᵢ - āᵢ)²
d(x, a): فاصله (تفاوت) بین متن ناشناس x و نویسنده a
هرچه این مقدار کمتر باشد، شباهت بیشتر است.
i: اندیس ویژگیها (مثلاً اگر ۱۰۰ ویژگی داشته باشیم، i از ۱ تا ۱۰۰ تغییر میکند)
xᵢ: مقدار ویژگی i-ام در متن ناشناس x
āᵢ: میانگین مقدار ویژگی i-ام برای نویسنده a
(بر اساس همه متون آموزشی آن نویسنده محاسبه شده)
(xᵢ - āᵢ)²: تفاوت مربع (فاصله اقلیدسی مربع) برای ویژگی i
wᵢ: وزن ویژگی i
- این قسمت مهم روش van Halteren است
- برخی ویژگیها در تشخیص نویسنده مهمتر هستند
- وزنها معمولاً از طریق تحلیل آماری یا یادگیری تعیین میشوند
Σᵢ: جمعزنی روی همه ویژگیها
۲.۴ مقایسه روشها
| معیار | Profile-based | Instance-based |
|---|---|---|
| نمایش متون آموزشی | یک نمایش تجمعی برای هر نویسنده | هر متن جداگانه نمایش داده میشود |
| مزیت با متون کوتاه | اتصال متون کوتاه ممکن است بهتر باشد | نمایش جداگانه ضعیفتر است |
| ترکیب ویژگیها | دشوار | آسان |
| الگوریتمهای قوی | محدود | SVM و دیگر الگوریتمهای پیشرفته |
| هزینه آموزش | کم | نسبتاً زیاد |
| هزینه اجرا | کم | کم |
| مسئله عدم توازن | بستگی به طول متون دارد | بستگی به تعداد متون دارد |
نتیجهگیری
تشخیص نویسندگی یک حوزه فعال و در حال رشد است که در دهه اخیر پیشرفتهای قابل توجهی داشته است:
دستاوردها:
- روشهای کاملاً خودکار با دقت بالا
- استفاده از الگوریتمهای یادگیری ماشین قدرتمند
- ارزیابی عینی با مجموعهدادههای استاندارد
- کاربردهای متنوع در دنیای واقعی
چالشهای باقیمانده:
- کار با متون بسیار کوتاه
- تشخیص قابل اعتماد برای دادگاهها
- تفکیک کامل سبک از موضوع
- کار با تعداد زیاد نویسنده
- انتقال بین ژانرها
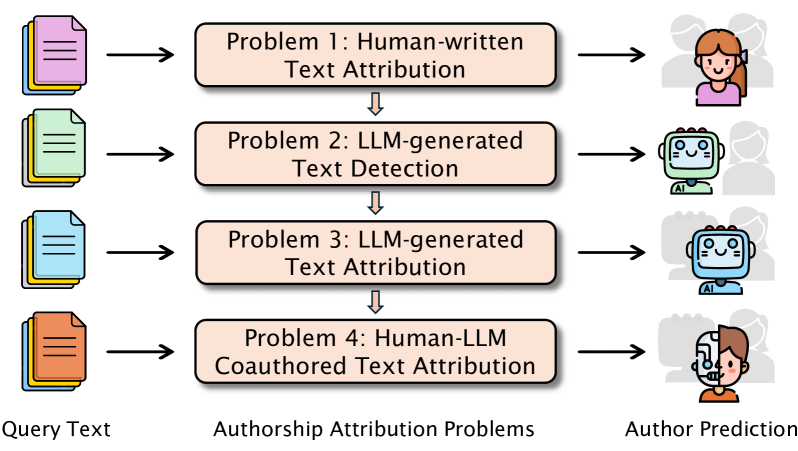
انتساب نویسنده در عصر مدلهای زبانی بزرگ (LLMs): مسائل، روشها و چالشها
این قسمت به بررسی انتساب نویسنده در عصر مدلهای زبانی بزرگ میپردازد. با پیشرفت LLMها، تمایز میان متنهای انسانی و ماشینی دشوارتر شده و روشهای سنتی با چالشهای جدی روبهرو هستند.
آیا مدل های زبان بزرگ می توانند نویسنده را شناسایی کنند؟
در این کار، راهبرد “پرامپتدهی مبتنی بر دانش زبانی” (Linguistically Informed Prompting یا LIP) را پیشنهاد میشود که با ارائهی راهنماییهای زبانی درونمتنی، توان استدلال مدلهای زبانی بزرگ را در وظایف راستیآزمایی و انتساب نویسندگی افزایش میدهد و همزمان توضیحاتی قابلفهم به زبان طبیعی ارائه میکند.
فرض کنید، دو متن مانند تصویر زیر داریم و میخواهیم با استفاده از مدل زبانی مشخص کنیم آیا نویسنده هر دو متن یک شخص هست یا خیر.

روش اول: فقط پرامت ساده بدون هیچ راهنمایی در تصویر زیر میبینیم که فقط از مدل زبانی خواسته شده تصمیم بگیرد که آیا نویسنده دو متن یک شخص هست یا خیر، و توضیحی اضافهای داده نشده.

میبینیم که مدل در پاسخ جواب False را برگشت داده است. یعنی نویسنده دو متن یکسان نیستند.
روش دوم: پرامت به همراه راهنمایی سبک نویسندگی در اینجا، علاوه بر پرامت اولیه که از مدل خواستهشده تا یکسان بودن نویسندهها را مشخص کند، به او گفته شده که سبک نوشتن متن را بدون توجه به موضوع و محتوای متن تحلیل کند.

میبینیم که مدل در پاسخ جواب False را برگشت داده است. یعنی نویسنده دو متن یکسان نیستند.
روش سوم: پرامت به همراه راهنمایی در گرامر متن
در این روش، علاوه بر پرامت اصلی، به مدل گفته میشود که روی سبک دستوری متن که نشاندهنده نویسندگی هستند تمرکز کند.

میبینیم که مدل در پاسخ جواب False را برگشت داده است. یعنی نویسنده دو متن یکسان نیستند.
روش چهارم: Linguistically Informed Prompting (LIP) - پرامپتدهی مبتنی بر دانش زبانی
LIP رویکردی در طراحی پرامپت است که بهجای تکیهی صرف بر مثالها یا دستورهای کلی، دانش و نشانههای زبانی (مانند سبک نگارش، واژگان، نحو، انسجام متن و الگوهای سبکی) را بهصورت راهنمای درونمتنی در اختیار مدل زبانی قرار میدهد. هدف آن تقویت توان استدلال مدلهای زبانی بزرگ در وظایفی مانند راستیآزمایی نویسندگی و انتساب نویسنده است، بهگونهای که مدل علاوه بر تصمیم نهایی، بتواند توضیحاتی شفاف و قابلفهم به زبان طبیعی ارائه دهد.
ترجمه پرامت در تصویر: بررسی کن آیا دو متن ورودی توسط یک نویسنده نوشته شدهاند یا خیر. سبک نگارش دو متن را تحلیل کن و تفاوتهای موضوعی و محتوایی را نادیده بگیر. استدلال خود را بر اساس ویژگیهای زبانی مانند افعال عبارتی، افعال وجهی، نشانهگذاری، واژگان نادر، وندها(پیشوند، پسوند)، کمیتها، طنز، کنایه، خطاهای تایپی و غلطهای املایی ارائه بده.

همانطور که میبینیم، اکنون مدل نویسنده دو متن را یکسان در نظر گرفته است. دلایل انتخاب مدل (ترجمه خروجی):
هر دو متن لحن محاورهای و غیررسمی دارند و از ضمایر شخصی و بیان نظرات ذهنی بهطور مکرر استفاده میکنند. در هر دو، ترکیبی از جملات ساده و مرکب دیده میشود و بهکارگیری عبارات معترضه برای افزودن توضیحات جانبی قابلتوجه است. طنز و کنایه نیز در هر دو متن وجود دارد، مانند عبارتهایی نظیر «total dimwits» و «corny (no pun intended)». سبک نشانهگذاری مشابه است؛ استفادهی زیاد از ویرگول و گاهی سهنقطه مشاهده میشود. همچنین برخی خطاهای تایپی و زبان غیررسمی به چشم میخورد، مانند «pretty original idea» و «pretty well developed». هر دو متن از افعال وجهی مانند «might» و «should» بهره میبرند و استفادهی پیوسته از افعال عبارتی و اصطلاحات محاورهای دارند. در مجموع، ویژگیهای زبانی و سبک نگارش بسیار مشابهاند و این شباهتها نشان میدهد که احتمالاً هر دو متن توسط یک نویسنده نوشته شدهاند.
مثال بالا راهبرد «پرامپتدهی مبتنی بر دانش زبانی» (Linguistically Informed Prompting یا LIP) را با روشهای پایهای دیگر که راهنمایی زبانی کمتری برای وظیفهی راستیآزمایی نویسندگی ارائه میدهند مقایسه میکند. خروجیهای مدل زبانی بزرگ به دو دستهی «تحلیل» (Analysis) و «پاسخ» (Answer) تقسیم شدهاند. تنها راهبرد LIP بهدرستی تشخیص میدهد که دو متن دادهشده توسط یک نویسنده واحد نوشته شدهاند. متنهایی که با رنگ نارنجی مشخص شدهاند تفاوتها را در چهار سطح مختلفِ راهنمایی نشان میدهند. متنهای آبیرنگ بیانگر فرایند استدلال مبتنی بر دانش زبانی هستند و متن آبی نشاندهندهی محتوای ارجاعدادهشده از اسناد اصلی است.
جمعبندی
تشخیص سرقت ادبی و انتساب نویسندگی دو حوزهی بههمپیوسته و کلیدی در تحلیل متون هستند که نقش مهمی در حفظ اصالت علمی، امنیت اطلاعات و اعتبار محتوای دیجیتال ایفا میکنند. تشخیص سرقت ادبی عمدتاً بر شناسایی شباهتهای متنی، بازنویسیها و استفادهی بدون ارجاع از آثار دیگران تمرکز دارد، در حالیکه انتساب نویسندگی به دنبال شناسایی یا تأیید نویسندهی یک متن بر اساس الگوهای سبکی و ویژگیهای زبانی اوست. با گسترش فضای دیجیتال و افزایش حجم دادههای متنی، هر دو حوزه از روشهای آماری، یادگیری ماشین و تحلیلهای زبانی عمیق بهره میبرند تا بتوانند الگوهای پنهان در متون را آشکار کنند.
با ظهور مدلهای زبانی بزرگ، مرز میان متن انسانی و متن تولیدشده توسط ماشین کمرنگتر شده و چالشهای جدیدی برای هر دو مسئله ایجاد شده است. در این شرایط، روشهای پیشرفتهای که علاوه بر شباهت سطحی، به تحلیل ویژگیهای زبانی، سبک نگارش و الگوهای استدلال توجه دارند، اهمیت بیشتری یافتهاند. ترکیب رویکردهای تشخیص سرقت ادبی و انتساب نویسندگی، بهویژه با تأکید بر تعمیمپذیری و تبیینپذیری، میتواند چارچوبی قدرتمند برای ارزیابی اصالت متن و افزایش اعتماد به سیستمهای پردازش زبان طبیعی در محیطهای علمی، حقوقی و رسانهای فراهم کند
منابع
- سرقت ادبی چیست؟ انواع، پیامدها و روشهای پیشگیری
- Plagiarism types and detection methods: a systematic survey of algorithms in text analysis
- Types of Plagiarism and Definitions | Types
- Stylometric methods for plagiarism detection: an authorship attribution approach
- A survey of modern authorship attribution methods
- Authorship Attribution in the Era of LLMs: Problems, Methodologies, and Challenges