
نویسنده: محمدرضا باباگلی
ايميل: MohammadRezaBabagoli.AI@gmail.com
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
آزمایشگاه شناسایی الگو دکتر هادی صدوقی یزدی
اجرای مدلهای زبانی به صورت محلی در Google Colab برای اجرای برنامههای LangChain

مقدمه
Olama به شما امکان می دهد مدل های منبع باز را به صورت محلی (بدون نیاز به API و اینترنت) روی سیستم شخصی خود اجرا کنید از نظر کاربردی، Ollama برای توسعهدهندگانی مفید است که میخواهند چتبات یا سیستمهای NLP را بهصورت آفلاین، با حفظ حریم خصوصی دادهها، یا با هزینه کمتر آزمایش و پیادهسازی کنند. برای مثال، در پروژههای چتبات محلی یا سیستمهای سازمانی که ارسال داده به خارج مجاز نیست، استفاده از Ollama رایج است.
نصب Ollama
Ollama روی سه سیستم عامل ویندوز، مک و لینوکس نصب میشود. وارد سایت رسمی Ollama شوید و آن را نصب کنید: https://ollama.com/
سایت رسمی Ollama
Ollama محیط گرافیکی (GUI) ندارد و شما باید از طریق ترمینال یا cmd از آن استفاده کنید. ظاهر شدن آیکون Ollama در استارت به معنای نصب کامل هست، اما میتوانید تست ساده زیر را انجام دهید.
۱. در منوی استارت ویندوز، cmd را تایپ و وارد Command Prompt شوید.
۲. در پنجره سیاهرنگی که باز میشود، دستور زیر را برای بررسی نسخه Ollama وارد کنید:
ollama --version
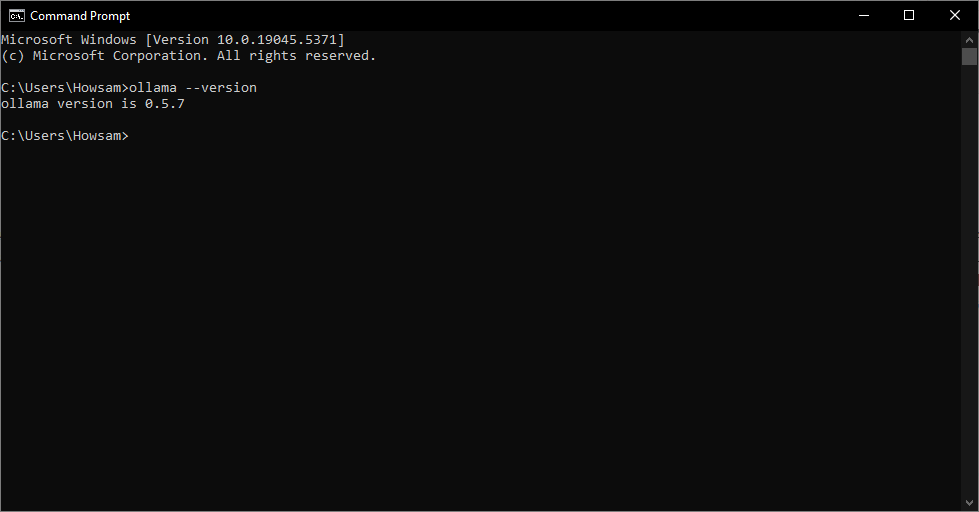
اجرای این دستور نسخه Ollama نصبشده را نشان میدهد.
مدل زبانی در Ollama
اگر بخواهید مدلهای زبانی مختلف را در Ollama نصب کنید، باید از فهرست موجود در سایت رسمی، مدل خود را انتخاب کنید.
متناسب با سیستم شخصی خودتان، یک مدل مناسب را انتخاب کنید.
دستورات Ollama

- دانلود مدل اگر فقط میخواهید مدلی را دانلود کنید اما وارد محیط چت نشوید.
ollama pull deepseek-r1:1.5b
- اجرای (دانلود و گفتگو با) یک مدل با این دستور، اگر مدل روی سیستم شما نباشد، آن را دانلود و سپس یک چت تعاملی با آن شروع میکند.
ollama run <model-name>
مثال:
ollama run llama3.2
- لیست کردن مدلهای نصبشده روی سیستم شما
این دستور تمام مدلهایی که قبلاً دانلود کردهاید را نشان میدهد.
ollama list - حذف یک مدل از سیستم شما
اگر مدلی را نمیخواهید و میخواهید فضای دیسک آزاد کنید.
ollama rm <model-name>مثال:
ollama rm codellama - مشاهده اطلاعات یک مدل خاص
جزئیات بیشتری درباره یک مدل نصبشده نشان میدهد.
ollama show <model-name>
نکته: برای توقف مدلی که در حال اجراست (در حالت چت تعاملی)، کافیست کلیدهای Ctrl + D را بفشارید یا دستور “/bye” را تایپ کنید.
- سفارشیسازی رفتار مدل زبانی
برای تنظیم دقیقتر پاسخ مدل، میتوانید پارامترهای مؤثری مانند حداکثر توکن (Max Tokens) و درجه خلاقیت (Temperature) را هنگام اجرای دستور وارد کنید.
ollama run deepseek-r1:1.5b --temperature 0.7 --max-tokens 100 - اتمام کار با مدل زبانی برای پایان دادن به جلسه کار با مدل و خروج از حالت گفتگو (چت)، میتوانید از یکی از روشهای ساده زیر استفاده کنید:
-
تایپ دستور خروج:
کافیست در خط فرمان، دستورexitرا تایپ و کلیدEnterرا بفشارید. -
استفاده از کلیدهای ترکیبی:
کلیدهایCtrl + Cرا همزمان فشار دهید. این روش سریعترین راه برای توقف و خروج است.
هر کدام از این روشها به سرعت شما را از محیط تعاملی مدل خارج میکنند و به خط فرمان اصلی (cmd) بازمیگردانند.
Ollama رو بروی Google Colab!
ممکن است سیستم و اینترنت شما به اندازه کافی قوی نباشد که بتواند یک مدل زبانی را اجرا کند، شما میتوانید، از GPU گوگل کولب استفاده کنید و مدل زبانی را در گوگل کولب اجرا بگیرید. این کار زمانی مفید است که شما میخواهید چند مدل زبانی را برای برنامه خود تست کنید تا ببینید کدام مدل مناسب تر است. پس بهتر است به جای دانلود با اینترنت شخصی، از گوگل کولب استفاده کنید.

دستورات زیر را به ترتیب در سلولهای گوگل کولب اجرا کنید:
!pip -q install langchain_ollama
!sudo apt-get update
!sudo apt-get install -y pciutils lshw
!curl -fsSL https://ollama.com/install.sh | sh
!nohup ollama serve > ollama.log 2>&1 &
# Download a model
!ollama pull qwen3:8b
# See available models
!ollama list
خروجی:
NAME ID SIZE MODIFIED
qwen3:14b bdbd181c33f2 9.3 GB 16 minutes ago
# Test with Hello!
!curl http://localhost:11434/api/generate \
-d '{"model":"qwen3:14b","prompt":"Hello!"}'
اکنون حتی میتوانيد مدل فراخواني شده با Ollama را در برنامههای LangChain خود در گوگل کولب اجرا کنید.
Ollama در LangChain
LangChain یک فریمورک متن-باز برای ساخت برنامههای کاربردی مبتنی بر مدلهای زبانی بزرگ است. شما میتوانید، در بخش فراخوانی مدلهای زبانی و مدلهای امبدینگ از مدلهای موجود در Ollama نیز استفاده کنید.

ChatOllama
برای استفاده از مدل زبانی در LangChain توسط Ollama کد زیر را اجرا کنید:
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="llama3.1",
temperature=0,
# other params...
)
مثال ساده از نحوه فراخوانی مدل:
res = llm.invoke("hi")
print(res.content)
<think>
Okay, the user said "hi". I need to respond appropriately. Since it's a greeting, I should greet them back and offer assistance. Let me check the guidelines. The response should be friendly and open-ended. Maybe ask how I can help them today. Keep it simple and welcoming. Alright, that should work.
</think>
Hello! How can I assist you today? 😊
مثال دیگر از فراخوانی:
messages = [
(
"system",
"You are a helpful assistant that translates English to French. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg
```text theme={null} AIMessage(content=’The translation of “I love programming” in French is:\n\n”J'adore la programmation.”’, additional_kwargs={}, response_metadata={‘model’: ‘llama3.1’, ‘created_at’: ‘2025-06-25T18:43:00.483666Z’, ‘done’: True, ‘done_reason’: ‘stop’, ‘total_duration’: 619971208, ‘load_duration’: 27793125, ‘prompt_eval_count’: 35, ‘prompt_eval_duration’: 36354583, ‘eval_count’: 22, ‘eval_duration’: 555182667, ‘model_name’: ‘llama3.1’}, id=’run–348bb5ef-9dd9-4271-bc7e-a9ddb54c28c1-0’, usage_metadata={‘input_tokens’: 35, ‘output_tokens’: 22, ‘total_tokens’: 57})
```python theme={null}
print(ai_msg.content)
```text theme={null} The translation of “I love programming” in French is:
“J’adore le programmation.”
#### پردازش تصویر با Ollama (Multi-Modal)
قابلیت اجرای مدلهای زبانی چندمنظوره (که همزمان متن و تصویر پردازش میکنند) در Ollama محدود است. برای نمونه، مدل [gemma3](https://ollama.com/library/gemma3) از این نوع است.
> برای بهرهبرداری از این ویژگی، حتماً Ollama را به آخرین نسخه بهروز کنید.
```python theme={null}
pip install pillow
import base64
from io import BytesIO
from IPython.display import HTML, display
from PIL import Image
def convert_to_base64(pil_image):
"""
Convert PIL images to Base64 encoded strings
:param pil_image: PIL image
:return: Re-sized Base64 string
"""
buffered = BytesIO()
pil_image.save(buffered, format="JPEG") # You can change the format if needed
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return img_str
def plt_img_base64(img_base64):
"""
Disply base64 encoded string as image
:param img_base64: Base64 string
"""
# Create an HTML img tag with the base64 string as the source
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# Display the image by rendering the HTML
display(HTML(image_html))
file_path = "../../../static/img/ollama_example_img.jpg"
pil_image = Image.open(file_path)
image_b64 = convert_to_base64(pil_image)
plt_img_base64(image_b64)
OllamaEmbeddings
میتوانید به جای استفاده از API برای فراخوانی مدلهای امبدینگ، از طریق Ollama از آنهااستفاده کنید.

فراخوانی مدل امبدینگ با Ollama:
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="llama3",
)
single_vector = embeddings.embed_query(text)
print(str(single_vector)[:100]) # Show the first 100 characters of the vector
text theme={null}
[-0.0039849705, 0.023019705, -0.001768838, -0.0058736936, 0.00040999008, 0.017861595, -0.011274585,
جمعبندی
Ollama یک پلتفرم مدیریت و اجرای مدلهای زبانی محلی (Local LLMs) است که امکان استفاده از مدلهای هوش مصنوعی را روی سیستمهای کاربر بدون نیاز به اتصال مداوم به سرور فراهم میکند. این ابزار قابلیت بارگذاری، آموزش سبک و اجرای مدلها را با تمرکز بر امنیت دادهها و حریم خصوصی کاربر ارائه میدهد و از آن میتوان برای توسعه برنامههای کاربردی هوش مصنوعی، چتباتها و تحلیل متون استفاده کرد. به طور خلاصه، Ollama محیطی ساده و قابل کنترل برای بهرهگیری از توان محاسباتی LLMها در سطح محلی فراهم میکند، بدون وابستگی به سرویسهای ابری.