[بسمالله الرحمن الرحیم]
[عنوان: Cross Validation اعتبارسنجی متقاطع]
[دانشگاه فردوسی مشهد - دانشکده مهندسی - گروه کامپیوتر]
[رشته: کارشناسی ارشد هوش مصنوعی]
[استاد راهنما: دکتر هادی صدوقی یزدی]
[نام دانشجو: اسماعیل برزگری]
[تاریخ: پاییز- 1404]
[آدرس ایمیل:] smailbarzegari@gmail.com
مقدمه:
Cross-Validation (اعتبارسنجی متقاطع) یک تکنیک مهم در ارزیابی مدلهای یادگیری ماشین است که بهویژه در رگرسیون و طبقهبندی کاربرد دارد. هدف اصلی آن، تخمین دقت مدل روی دادههای unseen و جلوگیری از overfitting است. در صورتی که سیستم، داده ها و بر چسب آنها را حفظ (از بر کند) و یاد نگیرد خواهیم گفت که overfitting یا بیش برازش رخ داده است.
بر اساس تعریف ویکیپدیا، اعتبارسنجی (cross-validation) متقابل (که در آمار به آن تخمین چرخشی یا آزمایش خارج از نمونهگیری نیز گفته میشود)، به تکنیکهای اعتبارسنجی مدلهای مختلف اطلاق میشود که معیاری کمی از نتایج تحلیلهای آماری ایجاد میکنند بهطوری که مدلهای تولید شده قادر به تعمیم (generalize) به یک مجموعهداده مستقل یا یک مجموعهداده نگهدارنده است.
مدلی که دارای حالت بیش برازش (overfit) است در دنیای واقعی دارای محدودیتهایی است و ارزش بسیاری ندارد. اما چنین مدلهایی گاهی اوقات میتوانند نتایج خوبی در مجموعه داده اعتبار (validation dataset) به دست آورند. این سناریو به طور خاص برای حالتی است که مجموعه آموزش و آزمایش از نظر اندازه کوچکتر باشند؛ بنابراین در چنین شرایطی، بسیار مهم است که اعتبارسنجی متقابل را در مجموعه آموزشی انجام دهیم، یعنی باید اعتبارسنجی متقابل را برای کل مجموعه داده اجرا کنیم.
از طرفی یک مدل یادگیری ماشین (Machine Learning) خوب باید ویژگیهای زیادی داشته باشد، اما یکی از اساسیترین نیازهایش، توانایی تعمیم است (به این معنی که باید عملکرد خوبی در مواجهه با دادههایی که در مراحل تمرین دیده نشده و یا وجود نداشتهاند، داشته باشد). این موضوع برای یک مدل بسیار مهم است؛ زیرا عاملی است که مشخص میکند یک مدل میتواند برای تولید و استفاده در دنیای واقعی مناسب باشد یا خیر؛ بنابراین نیاز داریم دادهها و اطلاعاتی که از آن مدل، بعد از آموزش به ما میرسد را بررسی کنیم و تشخیص دهیم که مدل ما مناسب استفاده است یا نه.
همانطور که قبلا گفته شد، یک راه مناسب برای اطمینان از این موضوع، اعتبارسنجی متقابل (cross-validate) مدل است. اعتبارسنجی متقابل خوب تضمین میکند که نتایج به دست آمده در مرحله آموزش و توسعه، قابلتکرار و سازگار باشند. البته به شرطی که هرگونه تغییر خارجی در توزیع دادههای دریافتی، مشاهده و محاسبه شود. یک چرخه خوب فرایندهای اعتبارسنجی یادگیری ماشین (Machine Learning validation)، بهترین ابر پارامترها (best hyperparmeters) را نتیجه میدهد.
چیزی مانند شکل یک میباشد:

شکل شماره یک: استخراج پارامترها از اعتبارسنجی
2- انواع روشهای Cross-Validation
شاید شما هم به دیتاستی برخورده کرده باشید که دادههای ارزیابی یا اعتبارسنجی در آن وجود ندارد. میدانیم که مدلها باید روی یکسری داده آموزش ببینند و با دادههای جدیدی ارزیابی شوند. در چنین شرایطی چطور باید مدل را ارزیابی کنیم؟ جواب، تکنیکهای cross validation یا اعتبارسنجی متقابل است. در این ارائه میخواهیم ببینیم انواع تکنیکهایی که برای cross validation وجود دارد، چه هستند.
2-1- Holdout Cross-Validation
یکی از سادهترین و پرکاربردترین روشهای ارزیابی مدل، روش Hold out است. ما کل مجموعه داده را به دو بخش نابرابر تقسیم میکنیم که بخش بیشتری از دادهها برای آموزش و قسمت دیگر دادهها برای اعتبارسنجی مدل استفاده میشوند. یعنی اطمینان حاصل شود که کاهش در تابع هدف، با پیشبینیها مطابقت دارد و حالتی از بیش برازش نیست.
در این روش، دادهها به صورت تصادفی به دو گروهِ آموزش و ارزیابی تقسیم میشوند. تعداد دادههای بخش آموزش، بیشتر از بخش ارزیابی باید باشد. معمولا 80-20 نسبت رایجی برای دادهها است، یعنی 80 درصد آموزش و 20 درصد ارزیابی.
به این صورت مدل با 80 درصد دادهها آموزش میبیند و با 20 درصد دیگر که هرگز آنها را ندیده، ارزیابی میشود. تصویر شماره یک، اعتبارسنجی به این روش، Hold out cross validation را نشان میدهد.
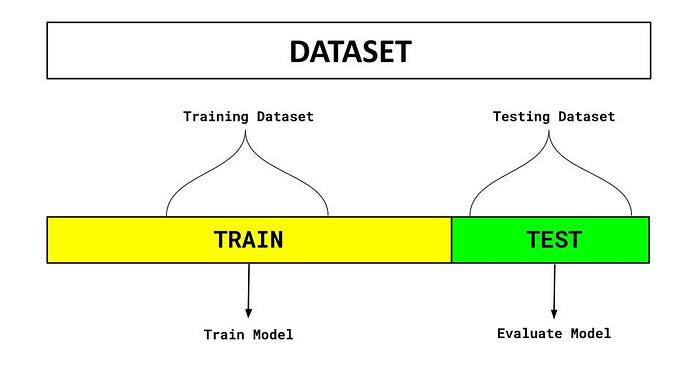 شکل شماره دو: اعتبار سنجی Hold out
شکل شماره دو: اعتبار سنجی Hold out
یکی از ویژگیهای مثبت این روش این است که نسبت به سایر روشهای اعتبارسنجی پیچیدگی محاسباتی کمتری دارد. اما باید دقت داشته باشید که این روش برای دیتاستهای کوچک مناسب نیست.
قطعه کدی کوچک برای این پیادهسازی:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
iris=load_iris()
X=iris.data
Y=iris.target
linear_reg=LogisticRegression()
# the actual splitting happens here
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
linear_reg.fit(x_train,y_train)
predictions=linear_reg.predict(x_test)
print("Accuracy score on training set is {} - Untitled-1:61".format(accuracy_score(linear_reg.predict(x_train),y_train)))
print("Accuracy score on test set is {} - Untitled-1:62".format(accuracy_score(predictions,y_test)))
2-2- K-Fold CV
رایجترین روش که در آن دادهها به K بخش مساوی تقسیم شده و در هر مرحله، یک بخش بهعنوان آزمون و k-1 بخش بهعنوان آموزش استفاده میشود و این فرآیند K بار تکرار میشود و میانگین نتایج گزارش میشود.
این اعتبارسنجی یکی از معروفترین تکنیکها برای پیادهسازی اعتبارسنجی متقابل است. تمرکز اصلی در این روش بر روی ایجاد “fold”های مختلف دادهها (معمولاً در اندازه برابر) است که ما از آنها برای اعتبارسنجی مدل استفاده میکنیم و بقیه دادهها برای فرایند آموزش استفاده میشوند. همه این فولدها به طور مکرر برای فرایند اعتبارسنجی و برای آموزش نمونه دادهها، با همدیگر ترکیب و سپس استفاده میشوند. همانطور که از نام آن مشخص است، چرخههای آموزشی در این تکنیک به تعداد K بار تکرار میشوند و دقت نهایی با گرفتن میانگین از اجراهای اعتبارسنجی دادهها محاسبه میشود.
تصویر سه، اعتبارسنجی k fold را برای نمونه داده شده نشان میدهد:

شکل شماره سه: اعتبارسنجی k-fold
فرض کنید که یک دیتاست با تعدادی داده دارید.
مقدار k را 4 فرض کنید. در این صورت 4 تا fold داریم درست؟ روند کار به این شکل است که ابتدا داده را به چهار بخش تقسیم میکنیم.
سپس در هر fold، یکی از این چهار بخش را به عنوان ارزیابی در نظر گرفته و مابقی را برای آموزش مدل استفاده میکنیم.
در fold دوم، بخش دوم از داده را به عنوان validation در نظر گرفته و مابقی را برای آموزش مدل استفاده میکنیم و به همین ترتیب fold سوم و چهارم را نیز تشکیل میدهیم.
خب تا اینجا توانستیم داده را به 4 k= شکل مختلف تقسیمبندی کنیم. حالا برای هر کدام از fold-ها، عملیات آموزش و ارزیابی مدل را انجام میدهیم.
مقدار k بستگی به فاکتورهای مختلفی مثل سایز و ساختار دیتاست، سخت افزار و … بستگی دارد، اما k=5 و k=10 بسیار رایج است.
اگر K-Fold چندین بار با ترکیبهای مختلف اجرا شود در آن صورت به آن Repeated K-Fold گفته میشود و میانگین نتایج نیز گزارش میشود.
مزیت: کاهش واریانس تخمین خطا نسبت به Hold-Out
معایب: محاسبات سنگین برای K های بزرگ.
قطعه کدی برای استفاده از این روش:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
features=iris.data
outcomes=iris.target
logreg=LogisticRegression()
K_fold_validation=KFold(n_splits=5)
score=cross_val_score(logreg,features,outcomes,cv=K_fold_validation)
print("Cross Validation Scores are {} - Untitled-1:104".format(score))
print("Average Cross Validation score :{} - Untitled-1:105".format(score.mean()))
2-3- Leave-One-Out CV (LOOCV)
حالت خاص K-Fold که این تکنیک، مشابه k-fold است. با این تفاوت که در آن، k=N است که N، تعداد نمونهها را نشان میدهد. این روش یک اعتبارسنجی متقاطع ساده است. هر مجموعه یادگیری با گرفتن همه نمونهها به جز یکی ایجاد میشود، که مجموعه تست، نمونه کنار گذاشته شده است. بنابراین، برای N نمونه، ما N مجموعه آموزشی مختلف و مجموعههای تست مختلف داریم. این رویه اعتبارسنجی متقاطع دادههای زیادی را هدر نمیدهد زیرا فقط یک نمونه از مجموعه آموزشی حذف میشود.
از کاربران بالقوه LOO برای انتخاب مدل باید چند نکته شناخته شده را در نظر بگیرند. در مقایسه با اعتبارسنجی متقاطع k-fold، به جای N مدل از N نمونه، از K مدل ساخته میشوند، که در آن N>k است. علاوه بر این، هر کدام به جای N-1 نمونه، از (k-1)N/k روی آنها آموزش داده میشوند. در هر دو روش، با فرض اینکه k خیلی بزرگ نیست و k>n است، روش LOO از نظر محاسباتی گرانتر از اعتبارسنجی متقابل k-fold است.
به این ترتیب N دقت از مدل به دست آوردهایم. در قدم بعدی، دقیقا مشابه با k fold، باید میانگین این دقتها را محاسبه و گزارش کنیم.
تصویر چهار اعتبارسنجی Leave-One-Out قرار داده شده و این موضوع را با تصویری ساده بیان میکند:

شکل شماره چهار: اعتبارسنجی Leavr-one-out
Leave P-Out بسیار شبیه به LeaveOneOut است زیرا با حذف نمونهها از مجموعه کامل، تمام مجموعههای آموزشی/آزمایشی ممکن را ایجاد میکند. برای p نمونهها، این کار ترکیب جفتهای n از p آموزش-آزمون را تولید میکند. برخلاف LeaveOneOut و KFold، مجموعههای آزمایشی برای p>1 همپوشانی خواهند داشت.
مزیت: عدم اتلاف داده (مناسب برای مجموعه دادههای کوچک).
معایب: هزینه محاسباتی بسیار بالا.
قطعه کدی برای استفاده از این روش:
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X=iris.data
Y=iris.target
leave_p_out=LeavePOut(p=2)
leave_p_out.get_n_splits(X)
random_forrest_classifier=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(random_forrest_classifier,X,Y,cv=leave_p_out)
print("Cross Validation Scores are {} - Untitled-1:139".format(score))
print("Average Cross Validation score :{} - Untitled-1:140".format(score.mean()))
2-4- Stratified K-Fold
نمونهگیری طبقهبندی شده یک تکنیک نمونهگیری است که در آن نمونهها به همان نسبتی که در جمعیت ظاهر میشوند (با تقسیم جمعیت به گروههایی به نام «طبقه» بر اساس یک ویژگی) انتخاب میشوند.
به عنوان مثال، اگر جمعیت مورد نظر شامل 30٪ مرد و 70٪ زن باشد، جمعیت را به دو گروه («مرد» و «زن») تقسیم میکنیم و 30٪ از نمونه را از گروه «مرد» و 70٪ از نمونه را از گروه «زن» انتخاب میکنیم.
طبقهبندی زمانی استفاده میشود که مجموعهدادهها حاوی کلاسهای نامتعادل باشند؛ بنابراین، اگر با یک تکنیک معمولی اعتبارسنجی متقابل انجام دهیم، ممکن است نمونههایی فرعی تولید شود که دارای توزیع متفاوتی از کلاسها هستند. برخی از نمونههای نامتعادل ممکن است نمرات فوقالعاده بالایی ایجاد کنند که منجر به نمره بالای اعتبارسنجی میشود و در نتیجه وضعیت نامطلوبی رخ میدهد؛ بنابراین ما زیر نمونههای طبقهبندیشدهای ایجاد میکنیم که فرکانس را در کلاسهای متفاوت حفظ میکنند و به ما تصویر واضحی از عملکرد مدل را تحویل میدهند.
مزیت: جلوگیری از سوگیری در توزیع کلاسها.
شکل پنج اعتبار سنجی Stratified K-Fold قرار داده شده و این موضوع را با تصویری ساده بیان میکند:

شکل شماره پنج: اعتبارسنجی startified k-fold
قطعه کدی برای استفاده از این پیادهسازی:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold,cross_val_score
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
linear_reg=LogisticRegression()
Stratified_cross_validate=StratifiedKFold(n_splits=5)
score=cross_val_score(linear_reg,X,Y,cv=Stratified_cross_validate)
print("Cross Validation Scores are {} - Untitled-1:168".format(score))
print("Average Cross Validation score :{} - Untitled-1:169".format(score.mean()))
2-5- Time Series CV
برای دادههای سریزمانی از دادههای گذشته برای آموزش و دادههای آینده برای آزمون استفاده میشود.
مثال : Time Series Split در scikit-learn
تکنیکهای عادی اعتبارسنجی متقابل برای وقتی که با مجموعهدادههای بر پایه زمان کار میکنیم مناسب نیستند. مجموعه دادههای بر پایه زمان را نمیتوان به صورت تصادفی تقسیم کرد و برای آموزش و اعتبارسنجی مدل استفاده کرد، به این دلیل که شاید بخش مهمی از اطلاعات مانند اطلاعات فصلی (seasonality که در واقع مشخصه یک سری زمانی است که دادهها در آن تغییرات منظم و قابلپیشبینی ای را تجربه میکنند) و غیره. با وجود مهم بودن ترتیب دادهها، تقسیم دادهها در هر بازه معینی دشوار است. برای مقابله با این مشکل میتوانیم از اعتبارسنجی متقابل سری زمانی استفاده کنیم.
در این نوع اعتبارسنجی متقابل، ما یک نمونه کوچک از دادهها (به صورت دستنخورده و با حفظ ترتیب) را میگیریم و سعی میکنیم نمونه بعدی را برای اعتبارسنجی پیشبینی کنیم. این عمل بهعنوان زنجیره پیشرو یا زنجیرهسازی جلوسو (forward chaining) و یا اعتبارسنجی متقابل متحرک (rolling cross validation) نیز شناخته میشود. ازآنجاییکه ما به طور مداوم در حال آموزش و اعتبارسنجی مدل بر روی مقادیر کوچک داده هستیم، مطمئناً میتوانیم یک مدل خوب پیدا کنیم که بتواند نتیجه خوبی را در این نمونههای چرخشی ارائه دهد.
شکل شش نحوه پیادهسازی این تکنیک روی نمونهای از داده را نشان میدهد:

شکل شماره شش: اعتبارسنجی time series cv
قطعه کد این اعتبارسنجی:
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4], [77,33]])
y = np.array([1, 2, 3, 4, 5, 6, 7])
rolling_time_series = TimeSeriesSplit()
print(rolling_time_series)
for current_training_samples, current_testing_samples in rolling_time_series.split(X):
print("TRAIN: - Untitled-1:195", current_training_samples, "TEST:", current_testing_samples)
X_train, X_test = X[current_training_samples], X[current_testing_samples]
y_train, y_test = y[current_training_samples], y[current_testing_samples]
3- جمع بندی و نکات مهم در انتخاب روش Cross-Validation
CV ابزاری قدرتمند برای ارزیابی مدلهای رگرسیون و طبقهبندی است.
K-Fold رایجترین روش است.
Stratified K-Fold برای طبقهبندی توصیه میشود.
برای دادههای کوچک: از LOOCV استفاده میشود.
برای دادههای نامتوازن: از Stratified K-Fold استفاده میشود.
برای دادههای وابسته به زمان: از Time Series Split استفاده میشود.
جدول مقایسه کاربردهای مختلف در روش های Cross-Validation
| ردیف | روشهای اعتبارسنجی | مثال کاربردی |
|---|---|---|
| 1 | Holdout | سادهترین و پرکاربردترین روش ارزیابی مدل برای مجموعه دادههای خیلی بزرگ |
| 2 | K-Fold | رگرسیون / طبقهبندی عمومی — ارزیابی رگرسیون خطی |
| 3 | Repeated K-Fold | کاهش واریانس تخمین با تکرار K-Fold |
| 4 | LOOCV | دادههای بسیار کوچک — ارزیابی SVM روی Iris |
| 5 | Stratified K-Fold | دادههای نامتوازن — روی دادههای نامتوازن |
| 6 | Time Series Split | دادههای سریزمانی — روی دادههای زمانی |
4- پیادهسازی در Python (Scikit-Learn)
4-1- برای رگرسیون
from sklearn.model_selection import KFold, cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=5, noise=0.1)
model = LinearRegression()
kfold = KFold(n_splits=5, shuffle=True)
scores = cross_val_score(model, X, y, cv=kfold, scoring='neg_mean_squared_error')
print("MSE Scores: - Untitled-1:230", -scores)
print("Mean MSE: - Untitled-1:231", -scores.mean())
4-2- برای طبقهبندی
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100, n_classes=2, weights=[0.8, 0.2])
model = RandomForestClassifier()
skfold = StratifiedKFold(n_splits=5, shuffle=True)
scores = cross_val_score(model, X, y, cv=skfold, scoring='accuracy')
print("Accuracy Scores: - Untitled-1:242", scores)
print("Mean Accuracy: - Untitled-1:243", scores.mean())
5- منابع:
[1] https://www.geeksforgeeks.org/machine-learning/cross-validation-machine-learning/
[2] https://medium.com/code-like-a-girl/what-is-cross-validation-in-machine-learning-5668f1ec6811
[3] https://en.wikipedia.org/wiki/Training,_validation,_and_test_data_sets
[4] https://scikit-learn.org/stable/modules/cross_validation.html
[5] https://medium.com/@aditib259/a-comprehensive-guide-to-hyperparameter-tuning-in-machine-learning-dd9bb8072d02
[6] https://uk.mathworks.com/discovery/cross-validation.html
[7] https://neptune.ai/blog/cross-validation-in-machine-learning-how-to-do-it-right
[8] https://medium.com/@soumyachess1496/cross-validation-in-time-series-566ae4981ce4
ومن الله التوفیق
اسماعیل برزگری