
مدلهای چندوجهی بزرگ Large Multimodal Models (LMM)

نویسنده: مهدیه ارغوانی
ایمیل : arghavany.ma@gmail.com
دانشگاه فردوسی مشهد دانشکده مهندسی گروه کامپیوتر
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
بینایی کامپیوتر دکتر هادی صدوقی یزدی
مدلهای چندوجهی بزرگ

ما انسانها جهان را میبینیم، میشنویم، لمس میکنیم، میخوانیم و از ترکیب همهٔ این حسها، فهم میسازیم.
تا چند سال پیش، هوش مصنوعی فقط یک حس داشت آن هم خواندن متن بود.اما حالا وارد دورهای شدهایم که مدلها فقط متن را نمیخوانند؛
میبینند، میشنوند، تحلیل میکنند و استدلال میکننداین همان جایی است که LMM وارد صحنه میشود.
شاید تا حالا براتون اتفاق افتاده باشه که دنبال موضوعی گشته باشید ولی نتوانسته باشید آن را متوجه شوید.تصور کنید کمی سبزیجات و دو تخم مرغ دارید ولی نمی دانید چطور می توانید املت سبزیجات درست کنید.
به او یک عکس را نشان میدهید، یک جمله میگویید، یک فایل صوتی پخش میکنید.
او همه را با هم میفهمد. LMM مثل انسانی است که:
- تصویر را میبیند
- متن را میخواند
- صدا را میشنود
- و از ترکیب اینها، معنا استخراج میکند
این مدلها فقط «پاسخ» نمیدهند؛ استدلال چندحسی انجام میدهند.
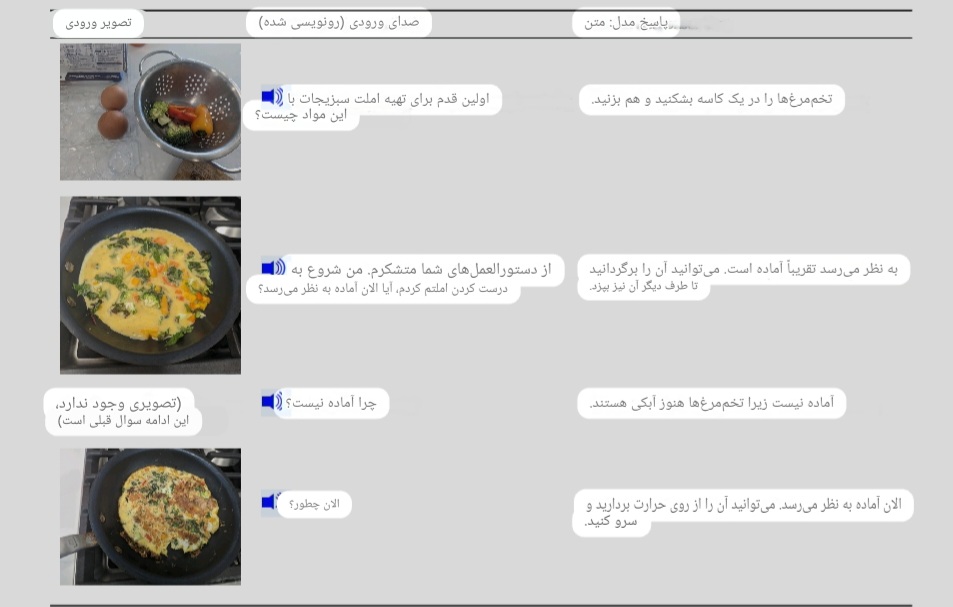
پرسش بنیادین: مدل چطور از چند حس، یک فهم واحد میسازد؟
وقتی شما یک عکس از یک میز شلوغ نشان میدهید، این فقط پیکسل است. وقتی میگویید «لیوان را بردار»، این فقط کلمات است.اما مدل باید بفهمد:
- این شیء روی میز یک لیوان است
- این جمله دربارهٔ «برداشتن لیوان» است
- و این دو باید به هم وصل شوند
LMM دقیقاً برای همین ساخته شده: اتصال «دیدن»، «خواندن» و «شنیدن» به یکدیگر.

تعریف ساده LMM
LMM مدلی است که:
- تصویر را میفهمد
- متن را میفهمد
- صدا را میفهمد
- و از ترکیب اینها استدلال میسازد
این تعریف ساده، پایهٔ بسیاری از سیستمهای هوشمند امروز است.

مربی ورزشی
تصور کنید به مدل میگویید:«این ویدیو رو نگاه کن. ببین چرا ضربههام اشتباهه.» مدل:
- زاویهٔ دست و پا را تحلیل میکند
- متن شما را میفهمد
- استدلال میکند: سرعت کم است؟ زاویه غلط است؟ هماهنگی مشکل دارد؟
- پاسخ میدهد: «زاویهٔ آرنجت خیلی باز است، باید نزدیکتر نگهش داری.» اینجا مدل از تصویر و متن و حرکت، یک فهم واحد ساخته است.

دستیار تعمیرات
یک تکنسین صدای موتور را ضبط میکند و میگوید:«این صدا غیرعادیه. مشکل از کجاست؟» مدل:
- صدا را تحلیل میکند
- متن را میخواند
- الگوی خرابی را تشخیص میدهد
- و یک تحلیل چندوجهی ارائه میدهد
- این همان چیزی است که مدلهای فقط زبانی نمیتوانستند انجام دهند.
کاربردهای گسترده: از خانه تا کارخانه
LMM فقط برای تحلیل عکس نیست. در دهها حوزه کاربرد دارد:
- پزشکی
- آموزش
- خودروهای خودران
- رباتیک
- طراحی
- امنیت
- تولید محتوا
هرجا لازم باشد چند حس با هم فهمیده شوند، LMM حضور دارد.

معماری LMM
چهار مرحلهٔ اصلی — همراه با مثالهای شهودی
۱) رمزگذار بینایی – فهم تصویر
مدل تصویر را میگیرد و آن را به مفاهیم قابلفهم تبدیل میکند.
مثال: یک عکس از یک میز کار شلوغ را به مدل میدهید. او باید بفهمد:
- این لپتاپ است
- این لیوان قهوه است
- این دفترچه است
- این کابل به کجا وصل است
مدل پیکسلها را به «مفهوم» تبدیل میکند.

۲) رمزگذار زبان – فهم متن
مدل جملهٔ شما را میگیرد و آن را به ساختار معنایی تبدیل میکند.
مثال: شما میگویید: «بگو کدوم کابل مربوط به شارژره.» مدل باید بفهمد:
- موضوع: کابل
- هدف: تشخیص کابل شارژ
- محدودیت: از میان چند کابل موجود روی میز

۳) ادغام چندوجهی – اتصال حسها
در این مرحله، مدل تصویر و متن را کنار هم قرار میدهد.
مثال: مدل میفهمد:
- در تصویر چند کابل وجود دارد
- جملهٔ شما دربارهٔ «کابل شارژ» است
- پس باید از میان کابلها، آن یکی را پیدا کند که به آداپتور وصل است یا به پورت شارژ لپتاپ میرود
این همان لحظهٔ «وصل شدن حسها»ست.

۴) استدلال – نتیجهگیری
مدل تصمیم میگیرد چه چیزی مهم است و چه پاسخی مناسب است.
مثال: مدل بررسی میکند:
- کدام کابل به پورت شارژ وصل است
- کدام کابل به دستگاه دیگری میرود
- کدام ویژگیها نشان میدهد این کابل، کابل شارژ است
و در نهایت میگوید:«کابلی که سمت راست لپتاپ قرار دارد، کابل شارژ است.»

پیاده سازی چرخه vla
تا اینجا با مفهوم این چرخه آشنا شدیم و می خواهیم تصویر یک میوه را تشخیص دهیم.در قدم اول کتابخانه های موردنیاز را فراخوانی می کنیم
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration, BlipForQuestionAnswering
from PIL import Image
import numpy as np
import warnings
import os
warnings.filterwarnings('ignore')
import requests
قبل از ورود باید کارهایی انجام شود به عنوان مثال باید تصویری را به صورت ورودی بدهیم که می توانیم به صورت محلی یا مانند اینجا به صورت آنلاین بدهیم و درقدم بعد آماده سازی مدل است
- برای توضیح دادن تصویر (image captioning)
- برای پرسش و پاسخ روی تصویر (VQA)
drive_url = "https://drive.google.com/uc?export=download&id=1vPYJzdYnIkTsjaInZJXAVgI1G59bftep"
image_path = "/content/my_fruit.jpg"
r = requests.get(drive_url)
with open(image_path, "wb") as f:
f.write(r.content)
print("تصویر دانلود شد")
class FruitDetectorLMM:
def __init__(self):
print("\nآمادهسازی مدل LMM")
try:
print("در حال بارگذاری مدلها...")
self.caption_processor = BlipProcessor.from_pretrained(
"Salesforce/blip-image-captioning-base"
)
self.caption_model = BlipForConditionalGeneration.from_pretrained(
"Salesforce/blip-image-captioning-base"
)
print("مدل توضیحدهی بارگذاری شد")
self.vqa_processor = BlipProcessor.from_pretrained(
"Salesforce/blip-vqa-base"
)
self.vqa_model = BlipForQuestionAnswering.from_pretrained(
"Salesforce/blip-vqa-base"
)
print("مدل پرسش و پاسخ بارگذاری شد\n")
except Exception as e:
print(f"خطا: {e}")
raise
def show_image_info(self, image):
print("\nدریافت تصویر")
print(f"ابعاد: {image.size[0]} × {image.size[1]} پیکسل")
print(f"حالت رنگی: {image.mode}")

اولین مرحله چرخه که رمزگذار بینایی است وارد عمل می شود. دراین مرحله باید محیط شناسایی شود.من عکس فوق را به عنوان ورودی واردکردم
def vision_encoder(self, image):
print("\nمرحله 1: رمزگذار بینایی")
print("تقسیم تصویر به پچها و استخراج ویژگیها")
inputs = self.caption_processor(image, return_tensors="pt")
with torch.no_grad():
vision_outputs = self.caption_model.vision_model(inputs["pixel_values"])
features = vision_outputs.last_hidden_state
print(f"تعداد پچها: {features.shape[1]}")
print(f"تعداد ویژگیها: {features.shape[-1]}")
return inputs
در این مرحله مدل دستوری که می دهیم را متوجه می شود
def text_encoder(self, prompt):
print("\nمرحله 2: رمزگذار زبان")
print(f"متن: {prompt}")
print(f"تعداد توکنها: {len(prompt.split())}")
دراین مرحله مدل باید متن و تصویر را باهم ادغام کند
def multimodal_fusion(self, image, prompt):
print("\nمرحله 3: ادغام چندوجهی")
print("ترکیب ویژگیهای تصویر و متن")
inputs = self.caption_processor(image, prompt, return_tensors="pt")
return inputs
در این مرحله ربات باید استدلال و نتیجه گیری را انجام دهد
def reasoning(self, inputs):
print("\nمرحله 4: استدلال")
with torch.no_grad():
outputs = self.caption_model.generate(
**inputs,
max_length=50,
num_beams=5
)
description = self.caption_processor.decode(outputs[0], skip_special_tokens=True)
print(f"توضیح: {description}")
return description
def vqa_step(self, image, question):
inputs = self.vqa_processor(image, question, return_tensors="pt")
with torch.no_grad():
outputs = self.vqa_model.generate(**inputs, max_length=20, num_beams=3)
answer = self.vqa_processor.decode(outputs[0], skip_special_tokens=True)
return answer
در این مرحله چرخه اصلی و مواردی که برای خروجی نیاز داریم می نویسیم
def detect_fruit(self, image_path):
print("\nشروع فرآیند تشخیص میوه با LMM")
try:
if not os.path.exists(image_path):
raise FileNotFoundError(f"فایل {image_path} یافت نشد!")
image = Image.open(image_path).convert('RGB')
self.show_image_info(image)
vision_inputs = self.vision_encoder(image)
prompt = "a picture of a fruit:"
self.text_encoder(prompt)
fused_inputs = self.multimodal_fusion(image, prompt)
description = self.reasoning(fused_inputs)
print("\n پرسش و پاسخ")
questions = [
"What color is the fruit?",
"How many fruits are there?",
"Is this fruit ripe?",
"What shape is the fruit?",
"Is this fruit fresh?",
"What fruit is this?"
]
results = {}
for q in questions:
answer = self.vqa_step(image, q)
print(f"سوال: {q}")
print(f"پاسخ: {answer}")
results[q] = answer
print("\ نتیجهگیری نهایی")
fruit_type = "ناشناخته"
fruit_color = results.get('What color is the fruit?', 'نامشخص')
fruit_map = {
'apple': 'سیب',
'banana': 'موز',
'orange': 'پرتقال',
'strawberry': 'توتفرنگی',
'grape': 'انگور',
'watermelon': 'هندوانه'
}
fruit_answer = results.get("What fruit is this?", "").lower()
for eng, per in fruit_map.items():
if eng in fruit_answer or eng in description.lower():
fruit_type = per
break
print(f"\n✅ {fruit_type} {fruit_color} است")
return {
'success': True,
'fruit': fruit_type,
'color': fruit_color,
'description': description,
'qa_results': results
}
except Exception as e:
print(f"\nخطا: {e}")
return {'success': False, 'error': str(e)}
if __name__ == "__main__":
print("تشخیص میوه با LMM")
try:
detector = FruitDetectorLMM()
results = detector.detect_fruit(image_path)
if results['success']:
pass
else:
print("\nخطا در اجرا")
except Exception as e:
print(f"\nخطای کلی: {e}")
با اجرای این کد می توانیم خروجی زیر را ببینیم
تصویر دانلود شد
تشخیص میوه با LMM
آمادهسازی مدل LMM
در حال بارگذاری مدلها...
Loading weights: 100%
مدل توضیحدهی بارگذاری شد
Loading weights: 100%
مدل پرسش و پاسخ بارگذاری شد
شروع فرآیند تشخیص میوه با LMM
دریافت تصویر
ابعاد: 1024 × 1024 پیکسل
حالت رنگی: RGB
مرحله 1: رمزگذار بینایی
تقسیم تصویر به پچها و استخراج ویژگیها
تعداد پچها: 577
تعداد ویژگیها: 768
مرحله 2: رمزگذار زبان
متن: a picture of a fruit:
تعداد توکنها: 5
مرحله 3: ادغام چندوجهی
ترکیب ویژگیهای تصویر و متن
مرحله 4: استدلال
توضیح: a picture of a fruit : red apple on a wooden table
پرسش و پاسخ
سوال: What color is the fruit?
پاسخ: red
سوال: How many fruits are there?
پاسخ: 1
سوال: Is this fruit ripe?
پاسخ: yes
سوال: What shape is the fruit?
پاسخ: round
سوال: Is this fruit fresh?
پاسخ: yes
سوال: What fruit is this?
پاسخ: apple
نتیجهگیری نهایی
✅ سیب red است
چرا این چرخه مهم است؟
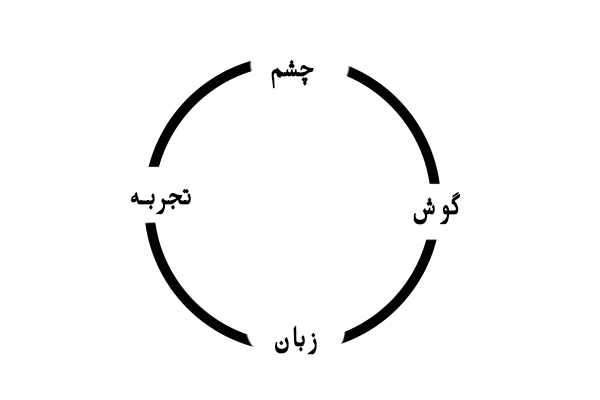
زیرا جهان واقعی فقط متن نیست.
ما با چشم، گوش، زبان و تجربه جهان را میفهمیم. LMM اولین نسل از مدلهایی است که این چندحسی بودن را تقلید میکند.
ادغام با vla
تا اینجا LMM فقط «میفهمد». اما فهمیدن کافی نیست. جهان واقعی نیاز به عمل دارد. اینجاست که VLA وارد میشود: چرخهٔ دیدن , فهمیدن , عمل کردن.اما یک سؤال مهم وجود دارد: ربات برای فهمیدنِ جهان از چه مغزی استفاده میکند؟ در نسلهای جدید رباتیک، این مغز همان LMM است.
ربات:
- تصویر را به LMM میدهد
- دستور شما را به LMM میدهد
- LMM معنا و هدف را استخراج میکند
- VLA این معنا را به «عمل» تبدیل میکند
به زبان ساده:LMM میفهمد، VLA عمل میکند.
اگر می خواهید vla را یادبگیرید کلیک کنید

ربات دستیار
شما میگویید: «این کتاب رو پیدا کن و روی میز مطالعه بذار.»
ربات:
قفسه را نگاه میکند
تصویر را به LMM میدهد
LMM میفهمد: این کتاب است، این شماره ی ردهبندی است
دستور شما را میخواند و هدف را استخراج میکند
VLA تصمیم میگیرد چه حرکتی لازم است
ربات کتاب را برمیدارد
دوباره نگاه میکند، دوباره تصمیم میگیرد
چرخه ادامه پیدا میکند
اینجا LMM «فهم» را میسازد و VLA «عمل» را می سازد

LMM و آیندهٔ هوش مصنوعی هرجا لازم باشد:
- تصویر دیده شود
- متن فهمیده شود
- صدا تحلیل شود
- و از ترکیب اینها نتیجهگیری شود
LMM حضور دارد.
#برای نوشتن کد و یادگیری بهتر می توانید به لینک های زیر مراجعه کنید
- https://arxiv.org/abs/2301.12597
- https://arxiv.org/abs/2404.01284
- https://arxiv.org/abs/2404.05726
- https://arxiv.org/abs/2312.11805
- https://arxiv.org/abs/2403.05530
- https://arxiv.org/abs/2507.06261
- An Introduction to Large Multimodal Models — Alexander Thamm
- Was ist ein Large Multimodal Model (LMM)? — BigData Insider