
بینایی ترنسفورمر Vision Transformer (ViT)

نویسنده: مهدیه ارغوانی
ایمیل : arghavany.ma@gmail.com
دانشگاه فردوسی مشهد دانشکده مهندسی گروه کامپیوتر
دانشجوی ارشد هوش مصنوعی دانشگاه فردوسی مشهد
بینایی کامپیوتر دکتر هادی صدوقی یزدی
بینایی ترنسفورمر

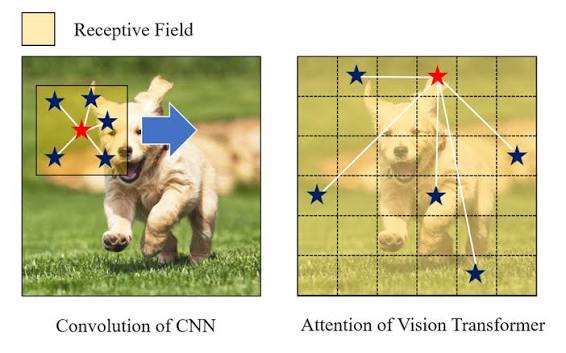
تا سال ۲۰۲۰، اگر به یک مدل بینایی کامپیوتر میگفتید «این عکس رو ببین»، اول از همه سراغ کانولوشن میرفت. شبکههای عصبی پیچشی (CNN) سالها سلطان بلامنازع میدان بودند.اما یه سؤال: وقتی خودِ ما آدمها به یک تصویر نگاه میکنیم، چطور این کار را میکنیم؟
· اول کل تصویر را میبینیم · بعد به جزئیات توجه میکنیم · رابطه بین قسمتهای مختلف را میفهمیم · و در نهایت یک درک یکپارچه از صحنه داریم
جالب اینجاست که ترنسفورمر دقیقاً همین کار را میکند. همان مدلی که در پردازش زبان انقلاب کرد، حالا آمده بود تا در بینایی کامپیوتر هم تحول ایجاد کند.ViT یا Vision Transformer یعنی: بیاییم با تصویر همانطور رفتار کنیم که با یک جمله رفتار میکنیم.
پرسش بنیادین: چطور میشود یک تصویر را مثل یک جمله دید؟
یک جمله از کلمهها تشکیل شده. کلمهها پشت سر هم میآیند و معنا میسازند. یک تصویر از چی تشکیل شده؟ پیکسلها. اما اگر بخواهیم پیکسلها را مثل کلمه ببینیم، باید چکار کنیم؟ایدهی ViT ساده و در عین حال انقلابی بود:بیاییم تصویر را به تکهتکههای کوچک (پچ) تقسیم کنیم و با هر تکه مثل یک کلمه رفتار کنیم.
تعریف ساده ViT
ViT یا Vision Transformer مدلی است که:
· تصویر را به پچهای کوچک تقسیم میکند · هر پچ را مثل یک کلمه در نظر میگیرد · با مکانیزم attention رابطه بین پچها را یاد میگیرد · و در نهایت یک درک کلی از تصویر به دست میآورد
برخلاف CNN که با لایههای پیچشی قدمبهقدم جلو میرود، ViT یکباره کل تصویر را میبیند و رابطهی همهی پچها با هم را میفهمد.
فرق ViT با CNN چیست؟
ویژگی CNN ViT دید به تصویر محلی و تدریجی سراسری و یکباره استخراج ویژگی با فیلترهای پیچشی با مکانیزم attention ترتیب پردازش لایهبهلایه همهی پچها همزمان درک روابط با بزرگتر شدن میدان دید مستقیم و در همهی سطوح دادهی مورد نیاز نسبتاً کم زیاد (یا پیشآموزش)
به زبان ساده:
· CNN مثل این میماند که با ذرهبین به تصویر نگاه کنیم و کمکم کل را ببینیم · ViT مثل این میماند که یکباره کل تصویر را ببینیم و همهی ارتباطات را همزمان درک کنیم
کاربردهای ViT
۱) طبقهبندی تصویر ViT میتواند با دقت بالا بگوید در تصویر چه چیزی هست. از تشخیص نژاد سگ تا شناسایی بیماریهای گیاهی. ۲) تشخیص اشیاء با ترکیب ViT و مکانیزمهای دیگر، میتوان همهی اشیاء یک تصویر را تشخیص داد و موقعیتشان را مشخص کرد. ۳) بخشبندی تصویر ViT میتواند برای هر پیکسل تصویر مشخص کند که به چه کلاسی تعلق دارد. مثلاً در تصاویر پزشکی، تومور را از بافت سالم جدا کند. ۴) بازشناسی تصویر از چهرهی افراد گرفته تا مدلهای خودرو، ViT در بازشناسی الگوها عالی عمل میکند. ۵) ویدیو با گسترش ViT به ویدیو، میتوان حرکت و تعامل اشیاء را در طول زمان فهمید.
معماری ViT
حالا بیایید ببینیم ViT چطور کار میکند. شش مرحلهی اصلی:
۱) تقسیم تصویر به پچ – از پیوسته به گسسته
تصویر ورودی را به پچهای کوچک (مثلاً ۱۶×۱۶ پیکسل) تقسیم میکنیم. مثال: یک تصویر ۲۲۴×۲۲۴ را در نظر بگیرید. با پچ ۱۶×۱۶، چند پچ داریم؟ (224 ÷ 16) × (224 ÷ 16) = 14 × 14 = 196 پچ هر پچ یک تکهی کوچک از تصویر است که بعداً با آن مثل یک کلمه رفتار میشود.
۲) تبدیل پچ به بردار – خطیسازی
هر پچ که یک تکهی دوبعدی از تصویر است، باید به یک بردار یکبعدی تبدیل شود. چگونگی: هر پچ ۱۶×۱۶×۳ (سه کانال رنگی) را صاف میکنیم تا یک بردار ۷۶۸ عنصری به دست بیاید. سپس با یک لایهی خطی، این بردار را به یک بردار با ابعاد کوچکتر (مثلاً ۷۶۸) تبدیل میکنیم. به این بردارها میگویند پچ امبدینگ.
۳) اضافه کردن موقعیت – فهمیدن نظم
وقتی پچها را به بردار تبدیل کردیم، ترتیب آنها را از دست دادهایم. برای ترنسفورمر، همهی پچها مثل یک مجموعه هستند و نمیداند کدام پچ بالا سمت چپ است و کدام پایین راست. پس یک بردار موقعیت به هر پچ اضافه میکنیم که بگوید این پچ در کجای تصویر قرار داشته.
۴) توکن کلاس – عصارهی تصویر
یک بردار مخصوص هم اضافه میکنیم که بهش میگویند توکن کلاس. این توکن قرار است بعد از همهی محاسبات، نمایندهی کل تصویر باشد و برای طبقهبندی نهایی استفاده شود.
۵) لایههای ترنسفورمر – قلب مدل
مجموعهی پچها (به اضافهی توکن کلاس) وارد لایههای ترنسفورمر میشوند. هر لایه دو بخش اصلی دارد:
۵-۱) مکانیزم توجه (Self-Attention)
هر پچ به همهی پچهای دیگر نگاه میکند و میفهمد کدامها با آن مرتبط هستند.مثلاً پچی که چشم گربه است، باید به پچی که گوش گربه است توجه کند.
۵-۲) شبکهی پیشخور (FFN)
یک شبکهی عصبی ساده که روی هر پچ جداگانه پردازش انجام میدهد. این دو مرحله چند بار تکرار میشوند تا مدل روابط عمیق بین پچها را یاد بگیرد.
۶) سر طبقهبند – تصمیم نهایی
بعد از گذر از همهی لایهها، توکن کلاس را برمیداریم و به یک شبکهی کوچک میدهیم که تصمیم نهایی را بگیرد: · اگر طبقهبندی ۱۰ کلاسه باشد (مثلاً CIFAR-10)، خروجی ۱۰ عدد خواهد بود · هر عدد نشاندهندهی احتمال تعلق تصویر به آن کلاس است · بیشترین احتمال را به عنوان پاسخ برمیگزینیم

پیاده سازی vit
بامعماری ترنسفورمر بینایی آشنا شدیم .می خواهیم میوه را شناسایی کنیم.درقدم اول باید کتابخانه ها را پیاده سازی کنیم و تصویر را وارد کنیم و ابعاد تصویر را تغییر دهیم
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw
import requests
from io import BytesIO
print("🎓 پروژه آموزشی: درک Vision Transformer (ViT) قدم به قدم")
print("\n📥 دریافت عکس سیب از گوگل درایو")
drive_url = "https://drive.google.com/uc?export=download&id=1vPYJzdYnIkTsjaInZJXAVgI1G59bftep"
response = requests.get(drive_url)
image = Image.open(BytesIO(response.content)).convert('RGB')
plt.figure(figsize=(5,5))
plt.imshow(image)
plt.title("Original Image (Apple)")
plt.axis('off')
plt.show()
print(" ✅ عکس با موفقیت بارگذاری شد")
print("\n📏 تغییر اندازه تصویر به ۲۲۴×۲۲۴")
image_224 = image.resize((224, 224))
plt.figure(figsize=(5,5))
plt.imshow(image_224)
plt.title(" Resized to 224×224")
plt.axis('off')
plt.show()
print(" ✅ تغییر اندازه انجام شد")

در مرحله اول باید تصویر را به پچ های کوچکتر تقسیم کنیم
print("\n🧩 مرحله 1: تقسیم تصویر به پچهای ۱۶×۱۶")
patch_size = 16
num_patches_h = 224 // patch_size
num_patches_w = 224 // patch_size
num_patches = num_patches_h * num_patches_w
print(f" 📍 هر پچ: {patch_size}×{patch_size} پیکسل")
print(f" 📍 تعداد پچها: {num_patches_h}×{num_patches_w} = {num_patches} پچ")
plt.figure(figsize=(8,8))
plt.imshow(image_224)
for i in range(0, 225, patch_size):
plt.axhline(y=i, color='red', linewidth=0.5)
plt.axvline(x=i, color='red', linewidth=0.5)
plt.title(f"Step 1: Image divided into {num_patches} patches")
plt.axis('off')
plt.show()
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
fig.suptitle("Step 2: Sample Patches", fontsize=14)
center_r, center_c = 7, 7
img_array = np.array(image_224)
positions = [
(center_r, center_c, "Center patch (Apple)"),
(center_r, center_c-1, "Left edge"),
(center_r, center_c+1, "Right edge"),
(center_r-1, center_c, "Top edge"),
(center_r+1, center_c, "Bottom edge (shadow)"),
(center_r+3, center_c+3, "Background"),
(center_r-2, center_c-2, "Background"),
(center_r+2, center_c-2, "Background"),
]
for idx, (r, c, label) in enumerate(positions):
if 0 <= r < 14 and 0 <= c < 14:
patch = img_array[r*16:(r+1)*16, c*16:(c+1)*16]
ax = axes[idx//4, idx%4]
ax.imshow(patch)
ax.set_title(label, fontsize=9)
ax.axis('off')
plt.tight_layout()
plt.show()


در این مرحله باید تصویر به بردار تبدیل شود
print("\n📊 مرحله 2: تبدیل هر پچ به یک بردار")
embed_dim = 768
print(f" 📍 هر پچ ۱۶×۱۶×۳ = ۷۶۸ عدد → یک بردار {embed_dim} بعدی")
print(f" 📍 خروجی: {num_patches} بردار {embed_dim} بعدی")
print(f" 📍 شکل نهایی: (1, {num_patches}, {embed_dim})")
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
patch_sample = img_array[7*16:(7+1)*16, 7*16:(7+1)*16]
axes[0].imshow(patch_sample)
axes[0].set_title("1. A 16×16 patch")
axes[0].axis('off')
axes[1].text(0.5, 0.5, "→", fontsize=50, ha='center', va='center')
axes[1].axis('off')
vector_display = np.random.rand(1, 50) * 2 - 1
axes[2].imshow(vector_display, cmap='viridis', aspect='auto')
axes[2].set_title(f"2. {embed_dim}-D vector")
axes[2].set_xlabel("768 numbers")
axes[2].set_yticks([])
plt.tight_layout()
plt.show()
print(" ✅ هر پچ به یه بردار عددی تبدیل میشه")

در این مرحله باید اطلاعات تصویر را به هر قسمت بدهیم
print("\n🔖 مرحله 3: اضافه کردن توکن [CLS]")
print(" 📍 توکن [CLS]: یه بردار مخصوص که نماینده کل تصویر میشه")
print(f" 📍 قبل از اضافه کردن: {num_patches} بردار")
print(f" 📍 بعد از اضافه کردن: {num_patches + 1} بردار (یه [CLS] + ۱۹۶ پچ)")
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
before = np.random.rand(5, 10)
axes[0].imshow(before, cmap='Blues', aspect='auto')
axes[0].set_title("Before: Only patch vectors")
axes[0].set_ylabel("Patches")
axes[0].set_xlabel("Features")
after = np.random.rand(6, 10)
after[0, :] = 1
axes[1].imshow(after, cmap='Blues', aspect='auto')
axes[1].axhline(y=0.5, color='red', linewidth=2)
axes[1].set_title("After: [CLS] + patches")
axes[1].set_ylabel("First row = [CLS]")
axes[1].set_xlabel("Features")
plt.tight_layout()
plt.show()

print("\n📍 مرحله 3-1: اضافه کردن Position Embedding")
print(" 📍 Position Embedding: به مدل میفهمونه هر پچ کجای تصویر قرار داره")
print(" 📍 مثال: پچ بالا-چپ یه کد میگیره، پچ پایین-راست یه کد دیگه")
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
pos_grid = np.zeros((14, 14))
for i in range(14):
for j in range(14):
pos_grid[i, j] = (i*14 + j) / 200
im1 = axes[0].imshow(pos_grid, cmap='rainbow')
axes[0].set_title("Position codes for each patch")
axes[0].set_xlabel("Column")
axes[0].set_ylabel("Row")
plt.colorbar(im1, ax=axes[0])
positions_sample = [0, 49, 98, 147, 195]
pos_values = [p/200 for p in positions_sample]
patch_labels = ['Top-left', 'Center', 'Center', 'Bottom', 'Bottom-right']
axes[1].bar(range(len(positions_sample)), pos_values, color='orange', tick_label=patch_labels)
axes[1].set_title("Different position codes")
axes[1].set_ylabel("Position code value")
axes[1].set_xlabel("Patch location")
plt.tight_layout()
plt.show()

در این مرحله متوجه تصویر را بررسی می کند
print("\n🧠 مرحله 4: مکانیزم توجه (Self-Attention)")
print(" 📍 هر پچ به همه پچهای دیگه نگاه میکنه تا ارتباطها رو بفهمه")
print(" 📍 مثال: پچ سیب به پچهای اطرافش بیشتر توجه میکنه")
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
attention = np.zeros((10, 10))
for i in range(10):
for j in range(10):
attention[i, j] = np.exp(-abs(i-j)/2) + np.random.rand()*0.1
im = axes[0].imshow(attention, cmap='hot')
axes[0].set_title("Attention Matrix")
axes[0].set_xlabel("Target patches")
axes[0].set_ylabel("Source patches")
plt.colorbar(im, ax=axes[0])
patch_attention = attention[5, :]
axes[1].bar(range(10), patch_attention, color='orange')
axes[1].set_title("Attention of center patch")
axes[1].set_xlabel("Other patches")
axes[1].set_ylabel("Attention weight")
layers = ['Layer 1\n(edges)', 'Layer 3\n(colors)', 'Layer 6\n(parts)', 'Layer 12\n(object)']
focus = [0.6, 0.8, 0.9, 0.95]
axes[2].plot(layers, focus, marker='o', linewidth=2)
axes[2].set_title("Attention evolution")
axes[2].set_ylabel("Focus on correct region")
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n 📍 توجه در لایههای مختلف:")
print(" • لایه ۱: تشخیص لبههای سیب")
print(" • لایه ۳: تشخیص رنگ قرمز")
print(" • لایه ۶: تشخیص بخشهای سیب")
print(" • لایه ۱۲: تشخیص مفهوم کلی «سیب»")

این مرحله دسته بندی نهایی است
print("\n🎯 مرحله 5: دستهبندی نهایی")
classes = ['Apple', 'Orange', 'Banana', 'Pear', 'Peach']
probabilities = [0.86, 0.07, 0.03, 0.02, 0.02]
print(f" 📍 توکن [CLS] بعد از ۱۲ لایه، نماینده کل تصویر میشه")
print(f" 📍 یه شبکه کوچک این بردار رو به {len(classes)} کلاس تبدیل میکنه")
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
colors = ['green', 'gray', 'gray', 'gray', 'gray']
bars = axes[0].bar(classes, probabilities, color=colors)
axes[0].set_title("Final Classification")
axes[0].set_xlabel("Classes")
axes[0].set_ylabel("Probability")
axes[0].set_ylim(0, 1)
for bar, prob in zip(bars, probabilities):
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width()/2., height + 0.02,
f'{prob:.0%}', ha='center', fontsize=12)
axes[1].pie(probabilities, labels=classes, autopct='%1.0f%%',
colors=['green', 'orange', 'yellow', 'lightgreen', 'peachpuff'])
axes[1].set_title("Prediction Result")
plt.tight_layout()
plt.show()
print(f"\n ✅ نتیجه نهایی: Apple با {probabilities[0]:.0%} اطمینان!")

با اجرای این کد می توانیم خروجی زیر را ببینیم
🎓 پروژه آموزشی: درک Vision Transformer (ViT) قدم به قدم
📥 دریافت عکس سیب از گوگل درایو
✅ عکس با موفقیت بارگذاری شد
📏 تغییر اندازه تصویر به ۲۲۴×۲۲۴
✅ تغییر اندازه انجام شد
🧩 مرحله 1: تقسیم تصویر به پچهای ۱۶×۱۶
📍 هر پچ: 16×16 پیکسل
📍 تعداد پچها: 14×14 = 196 پچ
📊 مرحله 2: تبدیل هر پچ به یک بردار
📍 هر پچ ۱۶×۱۶×۳ = ۷۶۸ عدد → یک بردار 768 بعدی
📍 خروجی: 196 بردار 768 بعدی
📍 شکل نهایی: (1, 196, 768)
✅ هر پچ به یه بردار عددی تبدیل میشه
🔖 مرحله 3: اضافه کردن توکن [CLS]
📍 توکن [CLS]: یه بردار مخصوص که نماینده کل تصویر میشه
📍 قبل از اضافه کردن: 196 بردار
📍 بعد از اضافه کردن: 197 بردار (یه [CLS] + ۱۹۶ پچ)
📍 مرحله 3-1: اضافه کردن Position Embedding
📍 Position Embedding: به مدل میفهمونه هر پچ کجای تصویر قرار داره
📍 مثال: پچ بالا-چپ یه کد میگیره، پچ پایین-راست یه کد دیگه
🧠 مرحله 4: مکانیزم توجه (Self-Attention)
📍 هر پچ به همه پچهای دیگه نگاه میکنه تا ارتباطها رو بفهمه
📍 مثال: پچ سیب به پچهای اطرافش بیشتر توجه میکنه
📍 توجه در لایههای مختلف:
• لایه ۱: تشخیص لبههای سیب
• لایه ۳: تشخیص رنگ قرمز
• لایه ۶: تشخیص بخشهای سیب
• لایه ۱۲: تشخیص مفهوم کلی «سیب»
🎯 مرحله 5: دستهبندی نهایی
📍 توکن [CLS] بعد از ۱۲ لایه، نماینده کل تصویر میشه
📍 یه شبکه کوچک این بردار رو به 5 کلاس تبدیل میکنه
✅ نتیجه نهایی: Apple با 86% اطمینان!
مکانیزم توجه در ViT
قلب ViT مکانیزم توجه است. بیایید ساده ببینیم چطور کار میکند: تشبیه: یک دورهمی دوستانه فرض کنید در یک مهمانی هستید. میخواهید بفهمید فضا چطور است. چکار میکنید؟ · به همه نگاه میکنید · میبینید چه کسی با چه کسی حرف میزند · میفهمید گروهِ اصلی کجاست · متوجه میشوید چه کسی تنهاست مکانیزم توجه دقیقاً همین کار را میکند: ۱. پرسش (Query): هر پچ از خودش میپرسد «من باید به چه پچهایی توجه کنم؟» ۲.کلید (Key): هر پچ یک برچسب دارد که نشان میدهد چه اطلاعاتی دارد ۳.ارزش (Value): هر پچ یک محتوا دارد که اگر به آن توجه شود، باید منتقل کند ۴.توجه: شباهت بین پرسش و کلید مشخص میکند هر پچ چقدر به پچ دیگر توجه کند ۵.جمعآوری: بر اساس میزان توجه، ارزش پچها جمع میشود
مثال در تصویر گربه:
· پرسش از پچ چشم: «به چه پچهایی باید توجه کنم؟» · کلید پچ گوش: «من بخشی از گوش هستم» · شباهت پرسش و کلید: بالا (چشم و گوش هر دو بخشی از صورت گربه هستند) · توجه: ۰.۸ (یعنی ۸۰٪ از اطلاعات پچ گوش به پچ چشم منتقل شود)

انواع ViT
مدل ویژگی خاص ViT اصلی پایهایترین نسخه، ساده و مؤثر DeiT آموزش با دادهی کمتر، استفاده از تقطیر دانش Swin Transformer پنجرههای محلی برای کاهش محاسبات CvT ترکیب کانولوشن و ترنسفورمر ViT-MAE یادگیری خودنظارتی با ماسک کردن پچها
ViT و آیندهی بینایی کامپیوتر
ViT فقط یک مدل نیست، یک تغییر پارادایم است. حالا میدانیم که میشود با تصویر همانطور رفتار کرد که با متن رفتار میکنیم. این یعنی: · مدلهای یکپارچهای که هم تصویر و هم متن را میفهمند (مثل VLM) · مدلهایی که چند حس را ترکیب میکنند (مثل LMM) · مدلهایی که میبینند، میفهمند و عمل میکنند (مثل VLA) همهی اینها با ایدهی سادهی «تقسیم تصویر به پچ و رفتار با آنها مثل کلمه» شروع شد.
برای مطالعه بیشتر
- مقالهی اصلی ViT: An Image is Worth 16x16 Words
- ViT در Hugging Face
- کد رسمی ViT از Google Research
- DeiT: Data-efficient Image Transformers
- Swin Transformer