edge computing
پردازش لبه در دستگاه های هوشمند
فهرست مطالب
- اطلاعات نویسنده
- مقدمه
- مفهوم پردازش لبه
- پردازش لبه چگونه کار می کند؟
- اجزای مختلف پردازش لبه
- مزایای پردازش لبه
- کاربرد های پردازش لبه
- پردازش لبه در معماری سیستم های هوشمند
- نتیجه گیری</li>
- منابع</li> </ul> </div> ## اطلاعات نویسنده **نام :** حسین جهانبانی فر **وابستگی:** گروه مهندسی کامپیوتر ، دانشگاه فردوسی مشهد **تماس:** hosseinjahanbanifar@gmail.com ## مقدمه در عصر دیجیتال امروز، حجم دادههایی که از حسگرها، دوربینها و سیستمهای هوشمند تولید میشوند بسیار زیاد است. ارسال همهی این دادهها به سرورهای مرکزی یا فضای ابری برای پردازش، هم هزینهبر است و هم باعث تأخیر در واکنش دستگاهها میشود. در پردازش لبه، دادهها در همان محل تولید یعنی «لبهٔ شبکه» پردازش میشوند — مثلاً در خود دستگاه یا در یک مدار الکترونیکی نزدیک به حسگر. در این پروژه به مفهوم پردازش لبه، نحوه کار آن، اجزای مختلف مورد استفاده ، مزایای آن و نحوه پردازش لبه در سیستم های هوشمند می پردازیم . بررسی خواهیم کرد که چطور سختافزار میتواند دادهها را بدون نیاز به سرویس ابری پردازش کند و تصمیم بگیرد. ## مفهوم پردازش لبه به زبان ساده، پردازش لبه (Edge Computing) به معماریای گفته میشود که در آن دادهها بهجای ارسال مستقیم به سرورهای مرکزی، در نزدیکی منبع تولید داده (مانند سنسورها یا دستگاههای هوشمند) پردازش میشوند. این ساختار باعث میشود اطلاعات قبل از رسیدن به مرکز داده، در همان نقطه یا نزدیکترین node پردازش، تحلیل و بررسی شوند. یکی از مهمترین چالش هایی که محاسبات لبه رفع میکند، **کاهش تاخیر** در پردازش دادهها است. تصور کنید یک سیستم هوشمند کنترل ترافیک در شهری بزرگ باید در لحظه تصمیمگیری کند. اگر این اطلاعات ابتدا به سرورهای مرکزی ارسال شود و سپس پاسخ بازگردد، زمان زیادی صرف میشود. اما با استفاده از پردازش لبه، دادهها بلافاصله در محل جمعآوری و پردازش شده و پاسخ مناسب ارسال میشود. این ویژگی برای بسیاری از سرویسهای مبتنی بر اینترنت اشیا که به واکنش سریع نیاز دارند، **حیاتی** است. ## پردازش لبه چگونه کار می کند؟ محاسبات لبه با ایجاد تغییر ساختاری در معماری شبکه، امکان پاسخگویی سریعتر، کاهش مصرف پهنای باند و افزایش امنیت را فراهم میآورد و برای کاربردهای حساس به زمان و دادههای بزرگ بسیار حیاتی است. در ادامه مراحل پردازش دادهها در این روش را بررسی میکنیم: ### جمع آوری داده ها در لبه شبکه دادهها از دستگاههای مختلف (مثلا حسگرها یا دوربینها) جمعآوری میشوند. ### ارسال داده ها به گره های لبه دادههای خام یا بخشی از آنها به گرههای پردازشی نزدیک به منبع (مثل روترها، گیتویها یا سرورهای محلی) منتقل میشوند. ### پردازش داده ها در لبه این گرهها دادهها را بهشکل محلی پردازش میکنند؛ مثل فیلتر کردن، تحلیل اولیه یا اجرای الگوریتمهای هوش مصنوعی. ### تصمیم گیری و واکنش سریع بر اساس نتایج پردازش، واکنشهای فوری مثل ارسال هشدار، کنترل دستگاهها یا ذخیرهسازی محلی انجام میشود ### بازخورد و بروزرسانی نتایج پردازش میتوانند باعث بهروزرسانی سیستمها یا تنظیم عملکرد دستگاهها در محیط لبه شوند.
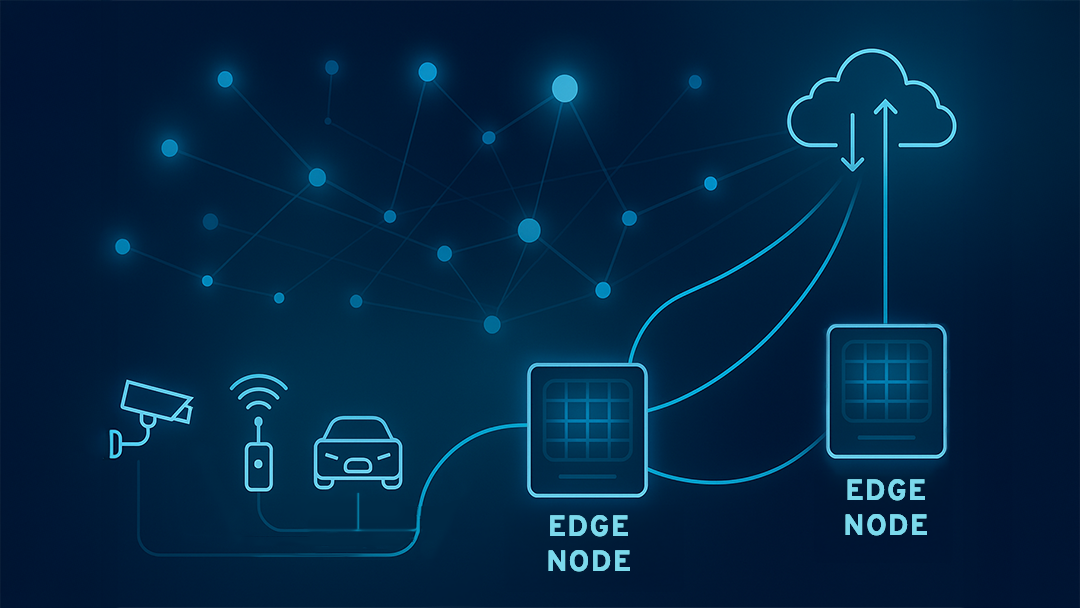 Figure 1: How does edge computing work?## اجزای مختلف پردازش لبه ### دستگاه های لبه این دستگاهها شامل سنسورها، دوربینها، گیتویها و هر وسیلهای است که داده را در محیط واقعی جمعآوری میکند. دستگاههای لبه نخستین نقطه تماس با دادههای خام هستند و بخشی از محاسبات لبه را در خود انجام میدهند ### گره های لبه گرههای لبه، همان نقاطی هستند که پردازش داده بهشکل محلی انجام میشود. این گرهها ممکن است سرورهای کوچک یا حتی رایانههای تعبیهشده باشند که دادهها را پیشپردازش میکنند و تحلیل اولیه روی آنها انجام میشود تا فقط اطلاعات مهمتر به مرحلهی بعد منتقل شود. ### گیت وی های لبه گیتویهای لبه، مسئول ارتباط بین دستگاههای پردازش لبه و شبکههای گستردهتر هستند. آنها دادهها را از گرههای لبه دریافت کرده و پس از فیلتر و تجمیع، آنها را به سمت سیستمهای ابری ارسال میکنند. ### نرم افزار های مدیریت و هماهنگی برای مدیریت حجم بالای دادهها و فرآیندهای پردازشی، به نرمافزارهای خاصی نیاز است که بین دستگاههای لبه و سرورهای ابری ارتباط برقرار کنند. این نرمافزارها، هماهنگی بین اجزای مختلف را فراهم کرده و از مقیاسپذیری سیستم پشتیبانی میکنند. ### زیرساخت های ابری هرچند بخش اصلی عملیات در محل انجام میشود، اما دادههایی که به پردازش سنگین یا ذخیرهسازی بلندمدت نیاز دارند، با هدف رایانش ابری به زیرساختهای ابری ارسال میشوند. این زیرساختها امکان بهرهمندی از ظرفیت بالا و قابلیت ارتقا را به شبکه میدهند.
Figure 1: How does edge computing work?## اجزای مختلف پردازش لبه ### دستگاه های لبه این دستگاهها شامل سنسورها، دوربینها، گیتویها و هر وسیلهای است که داده را در محیط واقعی جمعآوری میکند. دستگاههای لبه نخستین نقطه تماس با دادههای خام هستند و بخشی از محاسبات لبه را در خود انجام میدهند ### گره های لبه گرههای لبه، همان نقاطی هستند که پردازش داده بهشکل محلی انجام میشود. این گرهها ممکن است سرورهای کوچک یا حتی رایانههای تعبیهشده باشند که دادهها را پیشپردازش میکنند و تحلیل اولیه روی آنها انجام میشود تا فقط اطلاعات مهمتر به مرحلهی بعد منتقل شود. ### گیت وی های لبه گیتویهای لبه، مسئول ارتباط بین دستگاههای پردازش لبه و شبکههای گستردهتر هستند. آنها دادهها را از گرههای لبه دریافت کرده و پس از فیلتر و تجمیع، آنها را به سمت سیستمهای ابری ارسال میکنند. ### نرم افزار های مدیریت و هماهنگی برای مدیریت حجم بالای دادهها و فرآیندهای پردازشی، به نرمافزارهای خاصی نیاز است که بین دستگاههای لبه و سرورهای ابری ارتباط برقرار کنند. این نرمافزارها، هماهنگی بین اجزای مختلف را فراهم کرده و از مقیاسپذیری سیستم پشتیبانی میکنند. ### زیرساخت های ابری هرچند بخش اصلی عملیات در محل انجام میشود، اما دادههایی که به پردازش سنگین یا ذخیرهسازی بلندمدت نیاز دارند، با هدف رایانش ابری به زیرساختهای ابری ارسال میشوند. این زیرساختها امکان بهرهمندی از ظرفیت بالا و قابلیت ارتقا را به شبکه میدهند.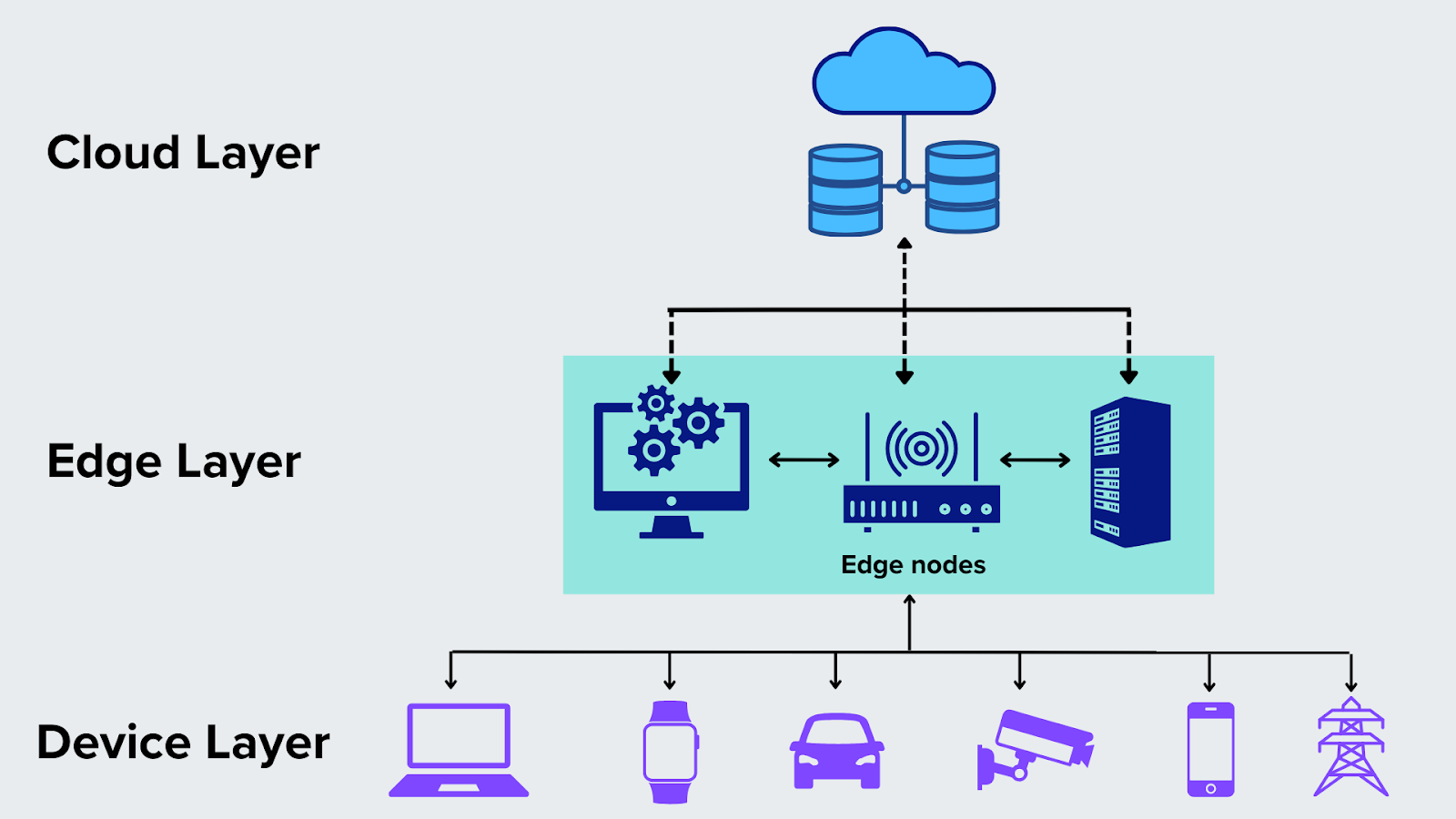 Figure 2: Edge Computing architecture## مزایای پردازش لبه ### کاهش تاخیر یکی از مهمترین مزایای رایانش لبه، کاهش محسوس تاخیر است. دادهها مستقیم در نزدیکترین نقطه به منبع تولید پردازش میشوند و نیاز به انتقال آنها به مراکز داده مرکزی یا رایانش ابری به حداقل میرسد. ### افزایش امنیت محاسبات لبه با پردازش دادهها در دستگاههای نزدیک به محل تولید آنها، خطرات حمله سایبری را کاهش میدهد. این موضوع برای کسب و کاری که با دادههای مهم سر و کار دارند، بسیار قابل توجه است. چون با استفاده از رمزگذاری دادهها و فایروالهای قوی در دستگاههای لبه میتوانند امنیت اطلاعات را به حداکثر میزان ممکن برسانند. ### صرفه جویی در پهنای باند در معماری محاسبات لبه، فقط اطلاعات ضروری پس از پردازش اولیه به سرویس های مرکزی ارسال میشوند. این موضوع به کاهش قابل توجه مصرف پهنای باند شبکه و بهینهسازی هزینههای زیرساختی منجر میشود. ### افزایش عملکرد در زمان واقعی یکی از مزایای بزرگ محاسبات لبه، قابلیت تجزیه و تحلیل دادهها در **زمان واقعی** است. این امکان به سازمانها کمک میکند تا به صورت فوری و لحظهای دادهها را پردازش و نتایج را بررسی کنند، بدون اینکه نیاز به ارسال آنها به مراکز داده یا سرورهای ابری داشته باشند. این ویژگی موجب افزایش کارایی سازمانها میشود و عمر مفید تجهیزات در حال استفاده را طولانیتر میکند.
Figure 2: Edge Computing architecture## مزایای پردازش لبه ### کاهش تاخیر یکی از مهمترین مزایای رایانش لبه، کاهش محسوس تاخیر است. دادهها مستقیم در نزدیکترین نقطه به منبع تولید پردازش میشوند و نیاز به انتقال آنها به مراکز داده مرکزی یا رایانش ابری به حداقل میرسد. ### افزایش امنیت محاسبات لبه با پردازش دادهها در دستگاههای نزدیک به محل تولید آنها، خطرات حمله سایبری را کاهش میدهد. این موضوع برای کسب و کاری که با دادههای مهم سر و کار دارند، بسیار قابل توجه است. چون با استفاده از رمزگذاری دادهها و فایروالهای قوی در دستگاههای لبه میتوانند امنیت اطلاعات را به حداکثر میزان ممکن برسانند. ### صرفه جویی در پهنای باند در معماری محاسبات لبه، فقط اطلاعات ضروری پس از پردازش اولیه به سرویس های مرکزی ارسال میشوند. این موضوع به کاهش قابل توجه مصرف پهنای باند شبکه و بهینهسازی هزینههای زیرساختی منجر میشود. ### افزایش عملکرد در زمان واقعی یکی از مزایای بزرگ محاسبات لبه، قابلیت تجزیه و تحلیل دادهها در **زمان واقعی** است. این امکان به سازمانها کمک میکند تا به صورت فوری و لحظهای دادهها را پردازش و نتایج را بررسی کنند، بدون اینکه نیاز به ارسال آنها به مراکز داده یا سرورهای ابری داشته باشند. این ویژگی موجب افزایش کارایی سازمانها میشود و عمر مفید تجهیزات در حال استفاده را طولانیتر میکند.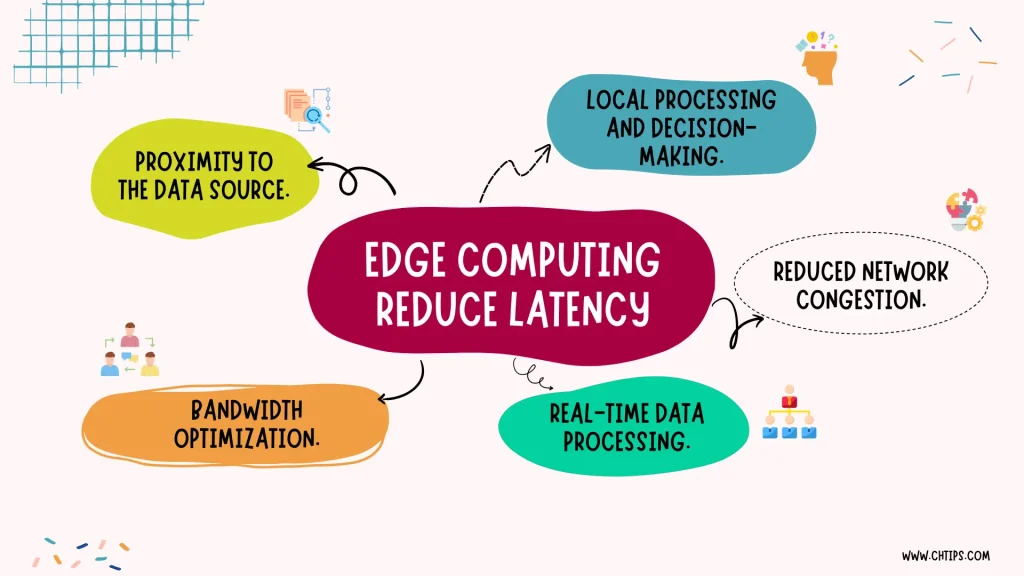 Figure 3: Edge Computing benefits## کاربردهای پردازش لبه ### اینترنت اشیا(IoT) اینترنت اشیا حجم بسیار زیادی از دادهها را بهطور لحظهای تولید میکند. پردازش لبه این امکان را میدهد که این دادهها بهشکل محلی پردازش شوند و فقط اطلاعات کلیدی و مهم به جهت رایانش ابری به سرورها ارسال گردد. برای نمونه، در کارخانههای هوشمند یا سیستمهای مدیریت انرژی، محاسبات لبه نقش کلیدی در تحلیل سریع دادههای سنسورها ایفا میکند. ### خودروهای خودران یکی از مهمترین کاربردهای پردازش لبه در صنعت خودروسازی، خودروهای هوشمند و خودران است. این خودروها نیازمند تصمیمگیریهای بلادرنگ برای ایمنی و عملکرد بهتر هستند. با کمک رایانش لبه، اطلاعات مربوط به موقعیت، سرعت، وضعیت جاده و موانع در لحظه پردازش میشود و خودرو قادر است بدون وابستگی به سرورهای مرکزی، عکسالعمل سریع نشان دهد. ### شهر های هوشمند در پروژههای شهر هوشمند، پردازش لبه به مدیریت و تحلیل دادههای حجیم مربوط به ترافیک، دوربینهای نظارتی، سیستمهای هشداردهنده و سایر تجهیزات متصل کمک میکند. این فناوری، امکان پاسخگویی سریع به رویدادها، بهبود کیفیت زندگی شهروندان و بهینهسازی منابع را فراهم میکند. ## پردازش لبه در معماری سیستم های هوشمند ایده اصلی پردازش لبه این است که هر رویداد مهم—از لرزش غیرعادی یک موتور تا تغییر ناگهانی دما—در همان محل تشخیص داده شود. این فرآیند با ترکیب پردازش سیگنال، استخراج ویژگی، تشخیص آنومالی و انتقال فقط اطلاعات ضروری انجام میشود.
Figure 3: Edge Computing benefits## کاربردهای پردازش لبه ### اینترنت اشیا(IoT) اینترنت اشیا حجم بسیار زیادی از دادهها را بهطور لحظهای تولید میکند. پردازش لبه این امکان را میدهد که این دادهها بهشکل محلی پردازش شوند و فقط اطلاعات کلیدی و مهم به جهت رایانش ابری به سرورها ارسال گردد. برای نمونه، در کارخانههای هوشمند یا سیستمهای مدیریت انرژی، محاسبات لبه نقش کلیدی در تحلیل سریع دادههای سنسورها ایفا میکند. ### خودروهای خودران یکی از مهمترین کاربردهای پردازش لبه در صنعت خودروسازی، خودروهای هوشمند و خودران است. این خودروها نیازمند تصمیمگیریهای بلادرنگ برای ایمنی و عملکرد بهتر هستند. با کمک رایانش لبه، اطلاعات مربوط به موقعیت، سرعت، وضعیت جاده و موانع در لحظه پردازش میشود و خودرو قادر است بدون وابستگی به سرورهای مرکزی، عکسالعمل سریع نشان دهد. ### شهر های هوشمند در پروژههای شهر هوشمند، پردازش لبه به مدیریت و تحلیل دادههای حجیم مربوط به ترافیک، دوربینهای نظارتی، سیستمهای هشداردهنده و سایر تجهیزات متصل کمک میکند. این فناوری، امکان پاسخگویی سریع به رویدادها، بهبود کیفیت زندگی شهروندان و بهینهسازی منابع را فراهم میکند. ## پردازش لبه در معماری سیستم های هوشمند ایده اصلی پردازش لبه این است که هر رویداد مهم—از لرزش غیرعادی یک موتور تا تغییر ناگهانی دما—در همان محل تشخیص داده شود. این فرآیند با ترکیب پردازش سیگنال، استخراج ویژگی، تشخیص آنومالی و انتقال فقط اطلاعات ضروری انجام میشود. Figure 4: Edge Computing Applications### لایه پردازش سیگنال هر چه داده خامی که از حسگرها وارد می شود، تمیزتر و قابل اعتمادتر باشد، تمامی لایه های بعدی بهتر عمل خواهند کرد. داده هایی که از سنسور های لرزش ، صوت، جریان یا دما وارد می شوند همیشه شامل مقدار زیادی نویز محیطی هستند. مثلا نویز ناشی از موتور های اطراف ، نوسانات ولتاژ، لرزش بدنه . اگر این نویز حذف نشود، سیستم تشخیص خرابی یا پیش بینی عمر دستگاه به اشتباه می افتد در نتیجه اولین کاری که یک سیستم پایش وضعیت انچام می دهد، **پاک سازی سیگنال** است . Wavelet یکی از قوی ترین روش های حذف نویز است، زیرا بر خلاف فیلترهای ساده مثل **میان گیر گیر** می تواند همزمان اطلاعات فرکانسی و زمانی سیگنال را نیز بررسی کند.
Figure 4: Edge Computing Applications### لایه پردازش سیگنال هر چه داده خامی که از حسگرها وارد می شود، تمیزتر و قابل اعتمادتر باشد، تمامی لایه های بعدی بهتر عمل خواهند کرد. داده هایی که از سنسور های لرزش ، صوت، جریان یا دما وارد می شوند همیشه شامل مقدار زیادی نویز محیطی هستند. مثلا نویز ناشی از موتور های اطراف ، نوسانات ولتاژ، لرزش بدنه . اگر این نویز حذف نشود، سیستم تشخیص خرابی یا پیش بینی عمر دستگاه به اشتباه می افتد در نتیجه اولین کاری که یک سیستم پایش وضعیت انچام می دهد، **پاک سازی سیگنال** است . Wavelet یکی از قوی ترین روش های حذف نویز است، زیرا بر خلاف فیلترهای ساده مثل **میان گیر گیر** می تواند همزمان اطلاعات فرکانسی و زمانی سیگنال را نیز بررسی کند.این کد یک سیگنال لرزش شبیهسازیشده را همراه با نویز تولید کرده و با روش Wavelet آن را پاکسازی میکند.
```python import pywt import numpy as np import matplotlib.pyplot as plt #signal Processing Layer def wavelet_denoise(data, wavelet='db4', level=3): # Wavelet decomposition coeffs = pywt.wavedec(data, wavelet, level=level) # Estimate noise threshold sigma = np.median(np.abs(coeffs[-1])) / 0.6745 threshold = sigma * np.sqrt(2*np.log(len(data))) # Apply soft thresholding for noise removal new_coeffs = [coeffs[0]] + [ pywt.threshold(c, threshold, mode='soft') for c in coeffs[1:] ] return pywt.waverec(new_coeffs, wavelet) # Simulating motor vibration data t = np.linspace(0, 1, 2000) signal = 0.5*np.sin(50*t) + 0.3*np.sin(120*t) # natural vibration behavior noise = np.random.normal(0, 0.4, len(t)) # environmental noise raw = signal + noise clean = wavelet_denoise(raw) plt.figure(figsize=(6, 3)) plt.plot(t, raw, label="Raw") plt.plot(t, clean, label="Clean") plt.legend() plt.savefig("wavelet.png", dpi=150) plt.show() ``` Figure 5: Vibration Sensor### استخراج ویژگی پس از حذف نویز، نوبت آن است که سیستم داده خام را به **چند عدد معنادار** تبدیل کند. این مرحله همان **استخراج ویژگی** است. در لرزشسنجی صنعتی، ویژگیهایی مثل RMS، میانگین، انحراف معیار، اسکونس و کرتسیس بسیار مهماند، چون هر کدام نشانهای از **وضعیت مکانیک دستگاه** هستند. برای مثال:
Figure 5: Vibration Sensor### استخراج ویژگی پس از حذف نویز، نوبت آن است که سیستم داده خام را به **چند عدد معنادار** تبدیل کند. این مرحله همان **استخراج ویژگی** است. در لرزشسنجی صنعتی، ویژگیهایی مثل RMS، میانگین، انحراف معیار، اسکونس و کرتسیس بسیار مهماند، چون هر کدام نشانهای از **وضعیت مکانیک دستگاه** هستند. برای مثال:- افزایش RMS نشانه افزایش انرژی ارتعاش و احتمال خرابی است
- افزایش Kurtosis معمولاً نشاندهنده ضربات کوچک ناشی از خرابی بلبرینگ است
- میانگین و انحراف معیار تغییرات کلی رفتار را نشان میدهند
این بخش، سیگنال را به مجموعهای از ویژگیهای آماری عددی مثل RMS، انحراف معیار و کرتسیس تبدیل میکند تا وضعیت مکانیکی دستگاه بهصورت فشرده و قابل تحلیل نمایش داده شود.
```python import numpy as np from scipy.stats import skew, kurtosis def extract_features(x): # Compute a dictionary of statistical features from the input signal x feat = { "mean": np.mean(x), "rms": np.sqrt(np.mean(x**2)), "std": np.std(x), "skew": skew(x), "kurt": kurtosis(x), # Kurtosis "peak_to_peak": np.ptp(x) # Peak-to-peak amplitude (max - min) } return feat # Simulating motor sensor data with a failure impulse raw = np.random.normal(0,1,2000) raw[500:520] += 6 # Injecting a sudden fault impact (bearing defect) # Extract features from the raw signal features = extract_features(raw) print(features) ``` ### تشخیص آنامولی در لبه تشخیص آنومالی یا رفتار غیر عادی یعنی اینکه سیستم متوجه شود که رفتار دستگاه از حالت معمول خارج شده است. این مرحله باید تا حد امکان روی خود دستگاه (لبه ) انجام شود تا نیازی به ارسال **داده های بسیار بزرگ** به سمت سرور نباشد. مثلا اگر سنسور لرزش روی پمپ نصب شده باشد و مقدار RMS آن ناگهان **دو برابر** شود، پمپ احتمالا به **خرابی** نزدیک شده است و سیستم باید در همان لحظه **هشدار** بدهد.در این قطعهکد یک مدل Isolation Forest با دادههای سالم آموزش داده میشود تا بتواند با بررسی ویژگیهای جدید، رفتار غیرعادی دستگاه را در همان لبه تشخیص دهد.
```python from sklearn.ensemble import IsolationForest import numpy as np # Generate training Data representing Normal motor behavior # 300 smaples, each with 5 extracted features normal_data = np.random.normal(0, 1, (300, 5)) # create Isolation Forest model # contamination = expected percentage of anomalies model = IsolationForest(contamination=0.02) # Train the model using only normal behavior data model.fit(normal_data) # Featur order : [RMS , STD , Kurtorsis , skewness , peak_to_peak] new_sample = np.array([[0.2, 0.3, 0.1, 0.5, 0.4]]) # predict anomaly anomaly = model.predict(new_sample) print("Anomaly result:", "Abnormal" if anomaly[0] == -1 else "Normal") ``` ### پردازش لبه در بخش قبل دیدیم که چگونه با استفاده از Isolation Forest و استخراج ویژگی های آماری از سیگنال ارتعاش، رفتار غیرعادی ماشین نسبت به حالت سالم تشخیص داده می شود. این یک روش **تحلیلی و هوشمند** هست که بر اساس **الگوی کلی** رفتار ماشین تصمیم گیری می کند اما سوال مهم این است که :آیا همیشه می توان منتظر تحلیل هوشمند ماند ؟
در این بخش وارد لایه حفاظت آنی (Fast Protection Layer) می شویم. هدف این بخش تشخیص **شدت لحظه ای ارتعاش** و صدور **هشدار فوری** روی خود دستگاه (edge) می باشد بدون استفاده از **یادگیری ماشین** و **مقایسه با الگوهای گذشته**این کد بدون استفاده از یادگیری ماشین، شدت لحظهای ارتعاش را محاسبه کرده و در صورت عبور RMS از آستانه مشخص، هشدار فوری روی خود دستگاه صادر میکند.
```python import machine, time, math adc = machine.ADC(machine.Pin(34)) def get_rms(samples=100): vals = [] for _ in range(samples): vals.append(adc.read()) time.sleep(0.002) mean = sum(vals)/len(vals) rms = math.sqrt(sum((v-mean)**2 for v in vals)/len(vals)) return rms while True: rms = get_rms() # Fast protection if rms > 50: print("WARNING: High vibration detected!") alarm_msg = { "type" : "ALARM", "rms" : rms, "timestamp" : time.time() } print("Send To Server" , alarm_msg) # periodic status (every loop ~100ms ) status_msg = { "type" : "STATUS" , "rms" : rms, "timestamp" : time.time() } print("Send To Server" , status_msg) time.sleep(0.1) ``` Figure 6: ESP32 Microcontroller### دوقلوی دیجیتال دوقلو دیجیتال یا Digital Twin نسخه دیجیتال یک دستگاه در واقعیت است. مثلا اگر یک پمپ در کارخانه داشته باشیم، نسخه دیجیتال آن روی **سرور** ساخته می شود و همان رفتار را تقلید می کند. Twin همیشه از لبه داده دریافت می کند داده هایی شامل : لرزش - دما - موقعیت - سلامت و ... و با استفاده از این داده ها می تواند پیش بینی کند چه زمانی پمپ خراب می شود یا حتی پیشنهاد دهد چه قطعه ای باید **تعویض** شود. در پروژه های صنعتی واقعی ، این قابلیت موجب کاهش خرابی های سنگین و افزایش عمر دستگاه می شود.
Figure 6: ESP32 Microcontroller### دوقلوی دیجیتال دوقلو دیجیتال یا Digital Twin نسخه دیجیتال یک دستگاه در واقعیت است. مثلا اگر یک پمپ در کارخانه داشته باشیم، نسخه دیجیتال آن روی **سرور** ساخته می شود و همان رفتار را تقلید می کند. Twin همیشه از لبه داده دریافت می کند داده هایی شامل : لرزش - دما - موقعیت - سلامت و ... و با استفاده از این داده ها می تواند پیش بینی کند چه زمانی پمپ خراب می شود یا حتی پیشنهاد دهد چه قطعه ای باید **تعویض** شود. در پروژه های صنعتی واقعی ، این قابلیت موجب کاهش خرابی های سنگین و افزایش عمر دستگاه می شود.در این بخش یک مدل ساده از دوقلوی دیجیتال پیادهسازی شده که با دریافت ویژگیها و نتایج آنامولی، سلامت سیستم، خرابیهای احتمالی و عمر باقیمانده دستگاه را تخمین میزند.
```python class DigitalTwin: def __init__(self): self.history = [] self.health = 100 self.rul_estimated = 400 # hours self.faults = [] def update(self, features, anomaly_flag): self.history.append(features) # Wear-based degradation (RMS) if features["rms"] > 1.5: self.health -= 2 # Impact-based degradation (Bearing fault) if features["kurt"] > 6: self.health -= 5 self.faults.append("Bearing degradation") # Anomaly feedback from edge if anomaly_flag == -1: self.health -= 3 self.faults.append("Unexpected vibration pattern") # RUL update self.rul_estimated = max(0, self.rul_estimated - features["rms"]) def recommendation(self): if self.health > 80: return "System operating normally" elif self.health > 50: return "Schedule inspections" elif self.health > 20: return "Maintenance required soon" else: return "Immediate shutdown recommended" def status(self): return { "health": self.health, "RUL_hours": self.rul_estimated, "faults_detected": list(set(self.faults)), "last_features": self.history[-1], "recommendation": self.recommendation() } packet = { "features" : { "rms" : 2.2 , "kurt" : 7.1 , "std" : 0.9 , "skew" : 0.5, "ptp" : 3.6 }, "anomaly_flag" : -1 } dt = DigitalTwin() dt.update(packet["features"] , packet["anomaly_flag"]) print(dt.status()) ```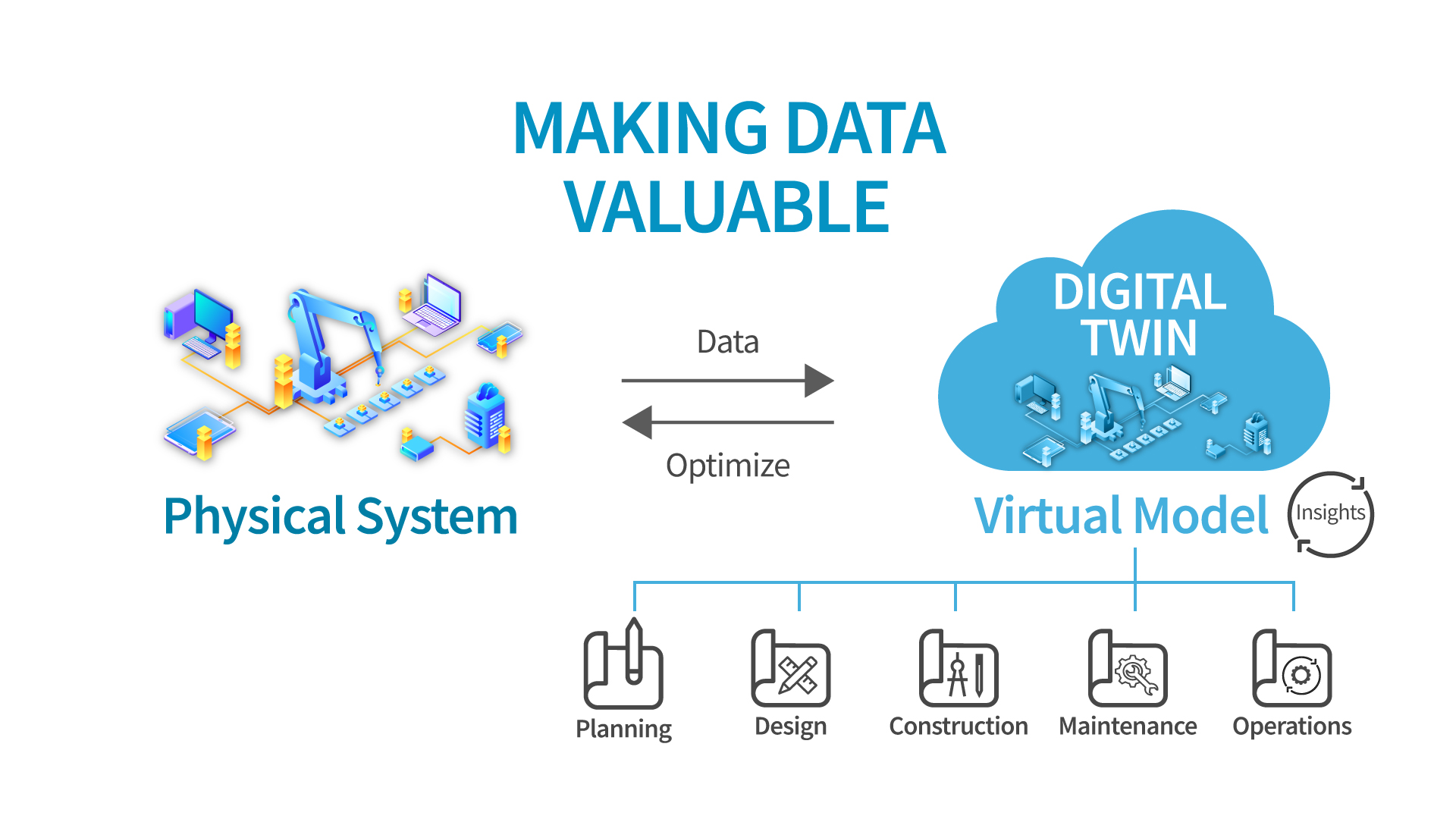 Figure 7: Digital Twin Architecture## نتیجه گیری پردازش لبه به عنوان یک فناوری کلیدی نقش مهمی در افزایش سرعت واکنش سیستمها و بهینهسازی مصرف منابع شبکه ایفا میکند. با انجام پردازش نزدیک به منبع داده، این روش توانسته چالشهای مربوط به تاخیر، پهنای باند و امنیت را تا حد زیادی کاهش دهد و راهحلهای موثری برای کاربردهای حساس به زمان ارایه کند. ## منابع
Figure 7: Digital Twin Architecture## نتیجه گیری پردازش لبه به عنوان یک فناوری کلیدی نقش مهمی در افزایش سرعت واکنش سیستمها و بهینهسازی مصرف منابع شبکه ایفا میکند. با انجام پردازش نزدیک به منبع داده، این روش توانسته چالشهای مربوط به تاخیر، پهنای باند و امنیت را تا حد زیادی کاهش دهد و راهحلهای موثری برای کاربردهای حساس به زمان ارایه کند. ## منابع - منابع</li> </ul> </div> ## اطلاعات نویسنده **نام :** حسین جهانبانی فر **وابستگی:** گروه مهندسی کامپیوتر ، دانشگاه فردوسی مشهد **تماس:** hosseinjahanbanifar@gmail.com ## مقدمه در عصر دیجیتال امروز، حجم دادههایی که از حسگرها، دوربینها و سیستمهای هوشمند تولید میشوند بسیار زیاد است. ارسال همهی این دادهها به سرورهای مرکزی یا فضای ابری برای پردازش، هم هزینهبر است و هم باعث تأخیر در واکنش دستگاهها میشود. در پردازش لبه، دادهها در همان محل تولید یعنی «لبهٔ شبکه» پردازش میشوند — مثلاً در خود دستگاه یا در یک مدار الکترونیکی نزدیک به حسگر. در این پروژه به مفهوم پردازش لبه، نحوه کار آن، اجزای مختلف مورد استفاده ، مزایای آن و نحوه پردازش لبه در سیستم های هوشمند می پردازیم . بررسی خواهیم کرد که چطور سختافزار میتواند دادهها را بدون نیاز به سرویس ابری پردازش کند و تصمیم بگیرد. ## مفهوم پردازش لبه به زبان ساده، پردازش لبه (Edge Computing) به معماریای گفته میشود که در آن دادهها بهجای ارسال مستقیم به سرورهای مرکزی، در نزدیکی منبع تولید داده (مانند سنسورها یا دستگاههای هوشمند) پردازش میشوند. این ساختار باعث میشود اطلاعات قبل از رسیدن به مرکز داده، در همان نقطه یا نزدیکترین node پردازش، تحلیل و بررسی شوند. یکی از مهمترین چالش هایی که محاسبات لبه رفع میکند، **کاهش تاخیر** در پردازش دادهها است. تصور کنید یک سیستم هوشمند کنترل ترافیک در شهری بزرگ باید در لحظه تصمیمگیری کند. اگر این اطلاعات ابتدا به سرورهای مرکزی ارسال شود و سپس پاسخ بازگردد، زمان زیادی صرف میشود. اما با استفاده از پردازش لبه، دادهها بلافاصله در محل جمعآوری و پردازش شده و پاسخ مناسب ارسال میشود. این ویژگی برای بسیاری از سرویسهای مبتنی بر اینترنت اشیا که به واکنش سریع نیاز دارند، **حیاتی** است. ## پردازش لبه چگونه کار می کند؟ محاسبات لبه با ایجاد تغییر ساختاری در معماری شبکه، امکان پاسخگویی سریعتر، کاهش مصرف پهنای باند و افزایش امنیت را فراهم میآورد و برای کاربردهای حساس به زمان و دادههای بزرگ بسیار حیاتی است. در ادامه مراحل پردازش دادهها در این روش را بررسی میکنیم: ### جمع آوری داده ها در لبه شبکه دادهها از دستگاههای مختلف (مثلا حسگرها یا دوربینها) جمعآوری میشوند. ### ارسال داده ها به گره های لبه دادههای خام یا بخشی از آنها به گرههای پردازشی نزدیک به منبع (مثل روترها، گیتویها یا سرورهای محلی) منتقل میشوند. ### پردازش داده ها در لبه این گرهها دادهها را بهشکل محلی پردازش میکنند؛ مثل فیلتر کردن، تحلیل اولیه یا اجرای الگوریتمهای هوش مصنوعی. ### تصمیم گیری و واکنش سریع بر اساس نتایج پردازش، واکنشهای فوری مثل ارسال هشدار، کنترل دستگاهها یا ذخیرهسازی محلی انجام میشود ### بازخورد و بروزرسانی نتایج پردازش میتوانند باعث بهروزرسانی سیستمها یا تنظیم عملکرد دستگاهها در محیط لبه شوند.