
With Emphasis on Artificial Intelligence Applications
- Hadi Sadoghi Yazdi : PhD in Electronics, Expert Consultant in Machine Learning and Data Systems
- Affilation and institute:
- Professor of Electrical and Computer Engineering, Ferdowsi University of Mashhad
- Director of Pattern Recognition Laboratory
- Member of SCIIP - Center of Excellence on Soft Computing and Intelligent Information Processing

Introduction
Data Lakes in Brief: Definition
- Centralized Repository: Stores raw data (structured, semi-structured, unstructured) from smart meters, SCADA, sensors.
- Schema-on-Read: Enables rapid analytics without predefined schemas, unlike data warehouses.
- Power Sector Value: Drives grid optimization, consumption analytics, predictive maintenance.
- Standardized Foundation: Built on global standards (IEC 61968 (CIM), IEC 20547, ISO 8000) for seamless interoperability, security, and data quality.
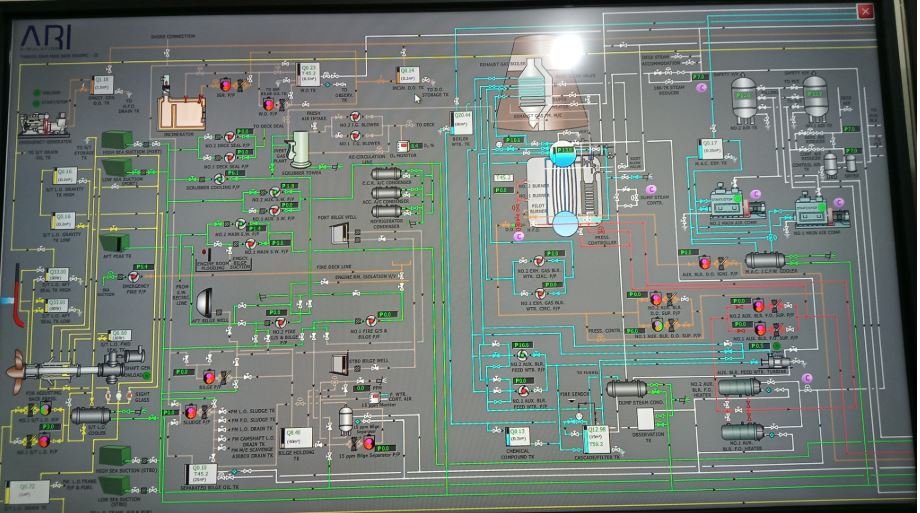
Data Lakes in Brief: Example
Some Examples
Enedis (French Distribution System Operator)
- Structured:
- 35 million smart meter readings/hour (Linky IoT devices)
- Semi-structured:
- Grid topology in JSON/XML (90,000+ substations)
- Unstructured:
- Drone inspection images (200TB/year for predictive maintenance)

Digital DEWA Example
Digital DEWA (Dubai Electricity and Water Authority’s Digital Arm)
- Information:
- Mohammed bin Rashid Al Maktoum Solar Park: 5,000 MW planned capacity by 2030
- AI-driven grid operations data (Rammas AI platform) for customer and employee services
- Energy storage technology testing data (hydrogen, batteries, thermal storage)

Tata Power Example
Tata Power (India’s Largest Integrated Power Company)
- Information:
- 166 offices across 16 states in India, serving diverse energy needs
- Financial performance data (FY21-FY25) and operational metrics in JSON/XML formats
- Renewable energy project data, including solar, wind, and hydroelectric initiatives

2. Data Lakes Benefits for Power Sector
AI-Optimized Smart Grid with Predictive Maintenance and Crisis Response
- Integrates smart grids, sensors, SCADA systems
- Enables AI-driven load forecasting & crisis response
- Supports predictive maintenance (fault detection)

2. Data Lakes Benefits for Power Sector: Example
Researchers at Pacific Northwest National Laboratory (PNNL) applied deep reinforcement learning to enhance power grid resilience during emergency events. Test results demonstrate their algorithm reduced affected customers by 20–65% and decreased network recovery time by an average of 16%. Relevant publications include PNNL’s power sector research and the specific study on enhancing power sector dynamics through improved capacity expansion pathways.

Integrates smart grids, sensors, SCADA systems
Data lakes serve as centralized, scalable repositories that unify heterogeneous data from smart grids, sensors, and Supervisory Control and Data Acquisition (SCADA) systems, enabling real-time analytics, predictive maintenance, and optimized grid operations. By storing raw data in its native format, data lakes facilitate advanced analytics and machine learning, improving efficiency, reliability, and sustainability in the power sector. Data Lakes in Energy Blog

Integrates smart grids, sensors, SCADA systems
-
Real-time Monitoring: Process smart meter/sensor data for grid control.
e.g., DEWA’s Rammas AI optimizes distribution in Dubai. [Src] -
Predictive Maint.: Analyze hist./real-time data to predict failures.
Enedis: 200TB/yr drone+SCADA from 90k+ substations. -
Demand/Load Balancing: Analyze consumption patterns to balance grid.
Tata Power: Integrates smart meters, SCADA & renewables (solar/wind/hydro) across 16 Indian states. [Src] -
Renewable Integration: Manage variability from renewables.
DEWA Solar Park (5,000 MW by 2030): Analyzes sensor data for seamless solar integration into Dubai’s grid. [Src]
Enables AI-driven load forecasting and crisis response
A data lake is merely a raw repository of diverse data from smart grids, sensors, and SCADA systems. However, when armed with AI, it transforms into a sentient mind that not only predicts energy demand with high accuracy but also enables real-time analysis for rapid crisis response, such as detecting outages. This powerful synergy turns inert data into dynamic, strategic knowledge for intelligent decision-making, as exemplified by Tata Power’s load forecasting and DEWA’s Rammas AI platform.

Supports predictive maintenance (fault detection)
Data lakes store and analyze historical and real-time data from sensors, SCADA systems, and equipment to identify patterns indicating potential failures before they occur. By applying machine learning, utilities can detect faults early, reducing downtime and maintenance costs. For example, Enedis uses data lakes to analyze 200TB/year of drone inspection images and SCADA data from 90,000+ substations to predict transformer failures in France’s grid.
Technical Needs for Data Lakes in the Power Sector
1. Handling High-Velocity Smart Meter Data Streams
Data lakes must process massive, continuous data streams from smart meters, which generate real-time readings at high frequencies, requiring scalable architectures and real-time processing capabilities to support grid optimization and load forecasting.
- Example (Enedis): Enedis manages 35 million smart meter readings per hour via its Linky IoT devices, using a data lake to enable real-time grid monitoring and AI-driven load forecasting across France.
- Digital DEWA uses a data lake to handle smart meter data streams for electricity and water services in Dubai, supporting the Rammas AI platform for real-time optimization.
- Tata Power processes high-velocity data from smart meters across 16 Indian states, enabling AI-driven load forecasting and demand response for efficient energy distribution.
Technical Needs for Data Lakes in the Power Sector
2. Robust Security and Compliance (e.g., GDPR, NIS2)
Data lakes must adhere to strict security standards and regulations like GDPR (for customer data protection) and NIS2 (for critical infrastructure cybersecurity), ensuring data privacy, integrity, and resilience against cyber threats.
- Example (Enedis): Enedis’s data lake complies with GDPR, using encryption and access controls for data.
- Example (DEWA): DEWA’s MORO platform adheres to international security standards, ensuring compliance for customer and operational data in Dubai.
- Example (Tata Power): Tata Power’s data lake aligns with India’s data protection laws and ISO 27001, securing financial and operational data across 166 offices.

Technical Needs for Data Lakes in the Power Sector
3. Key Advantages
- Reduces data preprocessing time → Faster analytics: Data lakes store raw, heterogeneous data in its native format, eliminating the need for extensive preprocessing before analysis. This enables faster access to data for analytics, machine learning, and decision-making, accelerating grid optimization and operational efficiency.
- Enables Scalable & Standardized Data Integration: Data lakes integrate diverse data sources (e.g., smart grids, sensors, SCADA) using a unified Common Information Model (CIM - IEC 61968), supporting large-scale, interoperable analytics for grid management.
- Supports Advanced Analytics: Data lakes facilitate machine learning for predictive maintenance and load forecasting, improving operational reliability.

Proposed Architecture
Transforming Power Utilities
Unlocking Grid Intelligence with a Unified Data Lake Architecture
A Vision for the Future
2030
The year data lakes will enable AI to predict demand and balance loads autonomously, minimizing outages.
Challenge and Solution
The Challenge: Data Overload
Power utilities are flooded with high-velocity data from countless sources. Unifying this data for real-time intelligence is a major hurdle to grid modernization.
The Solution: A Central Hub
A Data Lake architecture enables rapid analytics and AI-driven operations.
Proposed Data Lake Architecture
- 1. Ingestion Zone: Collects streaming and batch data from meters, sensors, and SCADA systems.
- 2. Raw Storage Zone: Stores raw, unaltered data in scalable cloud systems like AWS S3 or Azure Data Lake.
- 3. Processing Zone: Cleans, transforms, and enriches data for analysis using tools like Apache Hadoop, Spark.
- 4. Analysis Zone: Runs AI models (regression, clustering) for forecasting and advanced analytics.
- 5. Access Zone: Provides interactive dashboards and reports for managers and analysts.
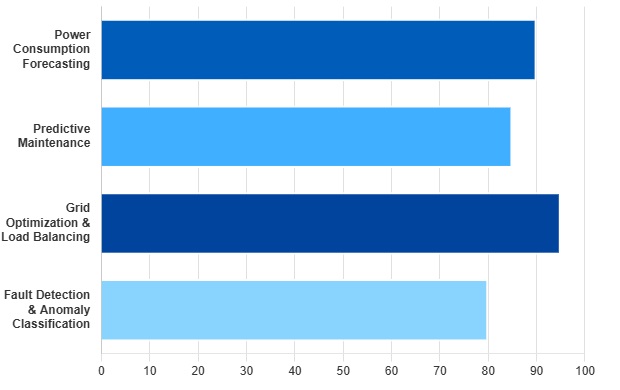
The Power of AI in the Data Lake
AI and machine learning models are the engines that turn raw data into actionable intelligence. This chart highlights the key applications that drive grid optimization and reliability.
Benefits of a Data Lake
Reports from Enel and CPFL companies.
| Performance Indicator | Improvement Range | Description |
|---|---|---|
| Maintenance & Repair Cost Reduction | 15% to 25% | Proactive, data-driven repairs instead of fixed schedules. |
| Equipment Downtime Reduction | 30% to 50% | Predicting failures to minimize asset downtime. |
| Asset Lifespan Extension | 20% to 40% | Optimized maintenance extends the life of key equipment. |
| Improved Demand Forecasting | 20% | Accurate load predictions using historical and external data. |
| Workforce Productivity Increase | 20% to 30% | Integrated data helps teams work more efficiently. |
| Reduction in Technical & Non-Technical Losses | Over $30M/year | Detecting theft and losses via smart meter data. |
| Financial Resource Optimization | Up to 15% | Better insights for efficient capital allocation. |
| Faster Outage Response | 10% Efficiency Increase | Real-time analysis for quick fault detection. |
Achieved through implementation of standardized data governance (ISO 8000) and secure integration frameworks (IEC 20547).
18-Month Implementation Roadmap
Phase 1 (3 Months)
Assessment & Design of data lake architecture.
Phase 3 (6 Months)
Integration and deployment of AI models for analytics.
Phase 2 (6 Months)
Initial Setup of cloud infrastructure and tools.
Phase 4 (3 Months)
Deployment of dashboards and staff training.
On-Premises Big Data Lake Architecture
- The recommended architecture is a robust, on-premises Apache Hadoop cluster for data storage with Spark as the high-speed processing engine.
- This setup requires a minimum of three servers, each equipped with multi-core CPUs and at least 64GB of RAM for parallel processing and in-memory computations.
- Data redundancy and fault tolerance are ensured by the Hadoop Distributed File System (HDFS).
- This solution provides a scalable and secure foundation for advanced data analytics, maintaining complete independence from external cloud providers.
Proposed Architecture: Transforming Power Utilities with Data Lakes
Role of Data Lakes
- Centralized Data Hub: A data lake unifies diverse data (smart meters, SCADA, sensors) into a scalable platform, enabling real-time grid intelligence and rapid analytics.
- Enables Smart Grid Evolution: Supports AI-driven operations, renewable integration, and net-zero goals, transforming utilities into agile, sustainable leaders.

Proposed Architecture: Standards-Based Layers
Layered Architecture
- Ingestion Layer: Data collection from diverse sources
- Storage Layer (Data Lake Core):
- Raw Zone: Data in native format
- Cleansed Zone: ISO 8000-quality data
- Curated Zone: Analysis-ready data
- Analytics Zone: For BI/AI processing
- Integration Layer: Enterprise Service Bus (ESB) for routing & transforming data based on IEC 61968 messages
- Data Quality & Governance Layer: Enforced by ISO 8000 and IEC 20547 standards

Architecture ensures national scalability and compliance with international best practices.
Requirements for Data Lake Implementation
Key Requirements for Power Utilities
- Scalable Infrastructure: Deploy cloud-based storage (e.g., AWS, Azure) to handle high-velocity data streams from smart grids and sensors.
- Robust Security: Ensure GDPR/NIS2 compliance with encryption and zero-trust architecture to protect sensitive grid and customer data.
- Common Data Model: Adoption of IEC 61968 Common Information Model (CIM) to break down data silos and ensure semantic unity across all systems (GIS, CIS, SCADA, etc.).

Strategic Advantages of Data Lakes
Driving Operational Excellence
- Reduced Preprocessing Time: Stores raw data, enabling instant analytics for load forecasting and grid optimization.
- AI-Powered Insights: Facilitates machine learning for predictive maintenance and demand response, enhancing reliability.

Future-Oriented Applications
Visionary Grid Solutions
- Autonomous Grid Management: Data lakes enable AI to predict demand and balance loads autonomously, minimizing outages by 2030.
- Quantum-Inspired Optimization: Emerging quantum algorithms will solve complex grid challenges, boosting renewable integration.
Emerging Trends in Data Lakes
Shaping the Future Grid
- Decentralized Energy Markets: Data lakes will power blockchain-based platforms for peer-to-peer energy trading, empowering prosumers by 2035.
- AI-Driven Resilience: Real-time analytics will predict and mitigate cyber threats, ensuring grid stability in a hyper-connected world.
Utilizing CCR (Coal Combustion Residues) Data in a Data Lake for Environmental and Sustainability Analyses
Entergy Louisiana
Entergy Louisiana serves approximately 1.1 million electric customers in 58 of Louisiana’s 64 parishes.
This approach explores how CCR data, such as compliance reports and monitoring data, can be integrated into a data lake to support comprehensive environmental and sustainability insights.

Consultant’s Approach: Impact on Power Utilities
(Smart Meters, SCADA)
Data Lake
Analytics
& Train Staff
Grids, Sustainability
Role of AI in Data Lake
- Power Consumption Forecasting: Regression and time-series models.
- Fault Detection: Clustering and classification for anomaly detection.
- Grid Optimization: Machine learning for load balancing and loss reduction.
- Predictive Maintenance: Forecasting equipment failures using sensor data.
- Recommended Tools: TensorFlow, PyTorch, Scikit-learn.
Challenges and Solutions
Challenges and Solutions
| Challenge | Solution |
|---|---|
| Proprietary data models creating silos | Implement a unified Common Information Model (CIM - IEC 61968) as the core semantic layer to ensure interoperability. |
| High-volume streaming data | Use Apache Kafka for streaming data management. |
| Poor data quality | Automated cleansing tools (e.g., Trifacta). |
| Security and privacy | Data encryption and GDPR-compliant standards. |
| Lack of skilled personnel | Internal training and external consultancy. |
Why Standards? Global Precedents & Our Approach
We are not inventing from zero. We are leveraging proven global standards to build a future-proof national infrastructure.
| Project | Country/Region | Key Standards | Special Achievement |
|---|---|---|---|
| Energinet Data Hub | Denmark | CIM, IEC 61968/70 | Competitive Electricity Market |
| ENTSO-E | Europe | CIM, IEC 61968/70 | Continental Coordination |
| PG&E Smart Grid | USA | CIM, ISO 8000 | Smart Grid, Loss Reduction |
| Our Proposed Project | Iran | IEC 61968 (CIM), IEC 61970, IEC 20547, ISO 8000 | Domestic Development, National Scalability |
Conclusion
- Data Lake: Data Lake: A key enabler for digital transformation, built on a standardized, secure, and interoperable architecture (IEC 61968, 20547, ISO 8000).
- AI-driven insights for forecasting, optimization, and maintenance.
- Proposed plan: 18-month implementation with cloud and open-source technologies.
- Our commitment: Expert consulting and support throughout the project.
Contact Us
Hadi Sadoghi Yazdi
AI and Data Specialist
Email: h-sadoghi@um.ac.ir
Phone: +98-51-38805117
Website: https://h-sadoghi.github.io/ | https://hadisadoghiyazdi1971.github.io/